

多言語AI音声認識モデルWhisperのインストールから、各パラメータの意味、WebUIを使った環境構築など、Whisperの使いこなしをまとめ見ました。オープンソースで商用利用可能な高性能な文字起こしをご自分のPCに入れてみましょう!
※本記事は2023年1月現在の情報に基づき作成しています。(情報としては古いですがアーカイブとして残しています。)
Whisperの環境構築
過去の記事でも紹介していますが、改めて環境構築の流れを簡単に紹介します。
PyTorch環境の構築
今回はWindowsのネイティブ環境でPython3.8の仮想環境を作成して、そこに構築します。もし、Pythonをインストールしていなかったり、Python3.10などの別のバージョンのPythonしかインストールしていない場合は、Python3.8で始めた方が使うライブラリの構築条件に近いので、うまくいきます。また、使用するPCはNVIDIAのGPUを搭載し、ある程度GPUのメモリを搭載したものを使う方がいいです。CPUでもいけますが、動作が非常に遅いので、その場合はGoogleColabなどを使うことを検討した方がいいかもしれません。(参考記事:生成系AIを使うためのGPU搭載おすすめパソコン)
Pythonをインストールしてない人向け記事→WindowsへのPythonローカル環境構築のおすすめの方法
バージョンが違う方向け記事→Windowsで複数のバージョンのPythonをインストールする
以下のインストールの流れをしまします。※GPUを使わずCPUだけで計算する場合は、以下の1~5は不要。
1.NVIDIAドライバの更新・・・NVIDIAのWebサイトから、構成にあった最新のドライバをダウンロードしてインストールします。
2.PyTorchの要件確認・・・PyTorchのwebサイトからインストールする環境とCUDAのバージョンを確認します。
3.C++コンパイラのインストール・・・「Build Tools for Visual Studio2022」のインストーラーから「C++によるデスクトップ開発」と、「v143ビルドツール用C++/CLIサポート(最新)」をインストールします。
4.CUDAのインストール・・・目標のバージョンのCUDAを公式ページからインストールします。(CUDA1.7インストーラーへのリンク)
5.cuDNNのインストール・・・公式ページからダウンロードします。ダウンロードをするときは登録とアンケートへの回答が必要になります。また、ダウンロードしたcuDNNへのPATHを通します。
詳細は以下の記事をご参照ください。
GPU環境構築
WindowsへのNVIDIA CUDAのGPU環境構築
ffmpegのインストール
フリーウエアのffmpegを公式ページからダウンロードしてインストールします。また、PATHを通します。詳しくは以下の記事をご参照ください。

gitのインストール
gitを公式ページからダウンロードしてインストールします。

Whisperのインストール
Python3.7~3.9の仮想環境を準備し、そこにPyTorchとWhisperをインストールしていきます。まずはターミナルなどで、好きな場所にフォルダを準備して、venvで仮想環境を作成します。仮想環境に入り、PyTorchをインストールしてから、githubサイトからWhisperをダウンロードし、インストールします。あと、テストをするのに便利な対話型開発環境のJupyterLabもインストールしておきます。
> py -3.8 -m venv venv
> .\venv\Scripts\Activate.ps1
(venv)> python -m pip install -U pip setuptools
(venv)> pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117
(venv)> pip install git+https://github.com/openai/whisper.git
(venv)> pip install jupyterlabもう少し詳しく過去の記事でも紹介していますので、良かったらそちらのほうもご参考ください。
Whisperの基本
Whisperとは
Whisperはウェブから収集した68万時間の多言語の教師付きデータで学習させた自動音声識別システムで、多言語での書き起こしや、多言語から英語への翻訳も可能で、OpenAIからオープンソースで提供されています。規制の緩いMITライセンスで提供されており、著作権表示さえしたら、商用利用も可能で、自分の作ったソフトに組み込むこともできます。
Whisperを使ってみる
JupyterLabからWhisperを使ってみます。まずはJupyterLabを起動して、Webブラウザから新しいノートブックを作ります。
(venv)> jupyter lab以下、ノートブックに入力します。
import whisper
model = whisper.load_model("base")Whisperをインポートし、モデルをセットアップします。初回のみモデルのダウンロードで時間が掛かります。モデルはデフォルトではUserのtempフォルダに保存されます。それでは、音声の文字起こしをしてみます。今回は、VoiceVoxで作成したずんだもんの自己紹介を使ってみます。
result = model.transcribe("test.wav")
print(result["text"])私の名前はずんだもんです東北地方の応援マスコットをしています特異なことはしゃべることです
ファイルネームのところを、他の音声ファイルや動画ファイルなどを選択すると、その音声の文字お越しをしてくれます。
関数transcribe
model.transcribe
関数transcribe(文字起こし)ではWhisperのモデルを使ってオーディオファイルの文字起こしをします。
出力
medel.transcribe(“音声ファイル”)の関数で得られる結果がjson形式になって出力します。キーは以下の通りです。’text’、’segments’、’language’を出力しています。以下にそれぞれ少し詳しく噛みくだいてみます。
result.keys()dict_keys(['text', 'segments', 'language'])
‘text’: 文字起こしをしたテキストデータ
‘segments’:文節ごとのセグメントデータのリスト
‘language’:認識した言語
result['segments'][0]{'id': 0,
'seek': 0,
'start': 0.0,
'end': 2.7600000000000002,
'text': '私の名前はずんだもんです',
'tokens': [20083, 2972, 15940, 8945, 3065, 18216, 26983, 4801, 27113],
'temperature': 0.0,
'avg_logprob': -0.2711757566870713,
'compression_ratio': 1.168141592920354,
'no_speech_prob': 0.041641715914011}
result['language']'ja'
[‘seguments’]のキーを詳しく見ます。本体の説明を見るとこんな感じ。。。
‘id’:セグメントのid
‘seek’:シーク位置(シーク再生で使用できる)
‘start’:開始時間
‘end’:終了時間
‘text’:テキスト
‘token’:分割したトークンの番号
‘temperature’:トークンを確率的に選ぶ度合い。ゼロの時は毎回同じ値を選ばれる。大きくすると結果が揺らぐ。
‘avg_logprob’:サンプリングされたトークンの平均ログ確率。この値が’logprob_threshold’を下回る場合は出力されない
‘compression_ratio’:音声の圧縮率
‘no_speech_prob’:無音部の確率。この確率が’no_speech_threshold’を上回り、’avg_logprob’が’logprob_threshold’を下回る場合、無音と判断する
transcribeのパラメータ
audio
音声ファイルのパスを示します。内部でffmpegを使っているので、ffmpegの多様なファイル形式をサポートしています。動画であっても、音声部分を抜き出して文字起こしできます。
verbose
Trueに設定すると文字起こし中にコンソールに文字起こしした結果を出力してくれます(デフォルトはFalse)。出力内容は以下の通りで、開始時間、終了時間、テキストをidごとに出力してくれるので、長い文字起こしをするときでも途中経過を確認できます。
print(f"[{format_timestamp(start)} --> {format_timestamp(end)}] {text}")temperature
トークンを確率的に選ぶ度合い。デフォルトは(0.0, 0.2, 0.4, 0.6, 0.8, 1.0)が設定されていて、圧縮率に従ってWhisperが良きに計らってくれるようである。
compression_ratio_threshold
圧縮比の閾値。デフォルトは2.4。もし、この圧縮率を上回る場合、失敗として扱われる。普通はデフォルトのままで読んでくれる。
logprob_threshold
ログを返した割合の閾値。デフォルトは-1.0。この値を”avg_logprob”が下回ると、失敗と判断する。
no_speech_threshold
無音と判断する閾値。デフォルトは0.6。”no_speech_prob”がこの値を上回り、”avg_logprob”が”logprob_threshold”を下回った場合、「無音」と判断する。
condition_on_previous_text
前の出力を参照して、一貫性のある文章を出力してくれる。デフォルトはTrue。Falseにすると、前後の文脈の一貫性がなくなるが、まれに発生する繰り返しループにハマることを避けることができる。
decode_options
その他、様々なデコードオプションを設定できる。
task
“transcribe”(デフォルト):文字起こし
“translate”:英語に翻訳
冒頭に紹介したずんだもんの自己紹介音声をオリジナルの日本語と英語で表記してみます。
model = whisper.load_model("medium")
ja_result = model.transcribe("test.wav")
en_result = model.transcribe("test.wav", task="translate")
print(ja_result["text"])
print(en_result["text"])私の名前はズンダモンです。東北地方の応援マスコットをしています。得意なことは喋ることです。 My name is Zundamon. I am a cheer-up mascot of Tohoku. My specialty is speaking.
language
音声の言語は冒頭部分を参照して自動識別してくれますが、あらかじめ分かっている場合は指定できます。
temperature
temperature固定で文字起こしもできます。大きめの数を入れると結果がばらつきます。試しにtemperature=0.8として、10回繰り返してみました。
for i in range(10):
test_result = model.transcribe("test.wav",language="ja", temperature=0.8)
print(test_result["text"])私の名前はズンダモンです。東北地方の応援マスコットをしています。得意なことはしゃべることです 私の名前はズンダモンです。東北地方の応援マスコットをしています。得意なことは喋ることです 私の名前はずんだもんです 東北地方の応援マスコットをしています得意なことは喋ることです 私の名前はズンダモンです東北地方の応援マスコットをしています得意なことは喋ることです人生の最終的なことを知りたい人生の最終的なことを知りたい人生の最終的なことを知りたい人生の最終的なことを知りたい人生の最終的なことを知りたい人生の最終的なことを知りたい人生の最終的なことを知りたい人生の最終的なことを知りたい人生の最終的なことを知りたい人生の最終的なことを知りたい人生の最終的なことを知りたい人生の最終的なことを知りたい 私の名前はずんだもんです東北地方の応援マスコットをしています得意なことは喋ることです 私の名前はズンダモンです東北地方の応援マスコットをしています得意なことは喋ることです 私の名前はズんだもんです 東北地方の応援マスコットをしています得意なことは、喋ることです 私の名前はゾンナモンです 東北地方の応援マスコットをしています得意なことはしゃべることです 私の名前は珍太もんです 東北地方の応援マスコットをしています得意なことは喋ることです 私の名前はZUNDAMONです東北地方の応援マスコットをしています得意なことは喋ることです
sample_len
サンプリングするトークンの数の最大値を設定。
best_of
ビームサーチで収集する独立したサンプル数
beam_size
ビームサーチで設定するビーム数
patience
ビームサーチにおけるpatienceで設定されるパラメータ。生成に対し、さらに候補をあげて改善しようとするか決定するロジックに関係する
prompt
その文章の前に置かれるテキストやトークンのリスト
prefix
その文章の後ろに置かれるテキストやトークンのリスト
suppress_blank
無用な空白の生成を抑える。デフォルトでTrue
suppress_tokens
リストでトークンのIDを与え、そのトークンを結果から除外する
without_timestamps
Trueにするとタイムスタンプを使わず、textトークンのみを出力します。(segmentsで分かれなくなる)
max_initial_timestamp
最初のタイムスタンプを出力する最大の時間を設定
fp16
主として、fp16(倍精度浮動小数点数) で計算する。とはいっても、ここでfp16に設定するだけでfp16になるわけではないようです。(Qiitaに参考となる記事が上がっていました。私には難しく仕組みは解く分かりません。。。)
WhisperをWebUIでつかう
WhisperをWebUIで使ってみましょう。有志によって、Hugging Face上には複数のWebUIがあがっています。今回は、aadnkさんのWebUIを実装してみます。
前提
前提として、上記でのWhispeやcuda計算環境のセットアップができている仮想環境に差分をインストトールしてセットアップします。
whisper-Webuiのインストール
今回はWindowsのネイティブ環境へのセットアップを行います。git cloneでwhisper-Webuiをダウンロードして、不足しているライブラリをインストールします。
(venv) > git clone https://huggingface.co/spaces/aadnk/whisper-webui
(venv) > cd .\whisper-webui\
(venv) > pip install -r requirements.txt
Whisper-WebUIを使ってみる
whisper-webuiのフォルダに入ってgradioを起動させます。
(venv) > python app.py --input_audio_max_duration -1 --server_name 127.0.0.1 --auto_parallel TrueRunning on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`.
表示されたURL(上記なら、http://127.0.0.1:7860)にwebブラウザでアクセスします。画面は下のような感じで直感的に操作が可能です。詳しくは説明しませんが、YouTubeのスクリプト化やマイク入力にも対応しており、いろいろな使い方ができます。試しに上のずんだもんの音声を読み込ませたところ、ちゃんと文字起こしができました。
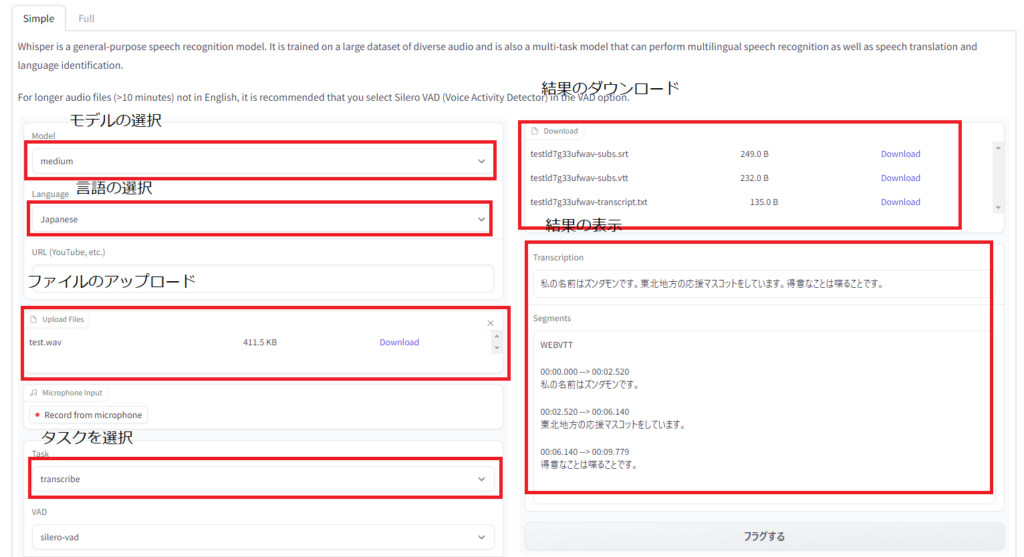
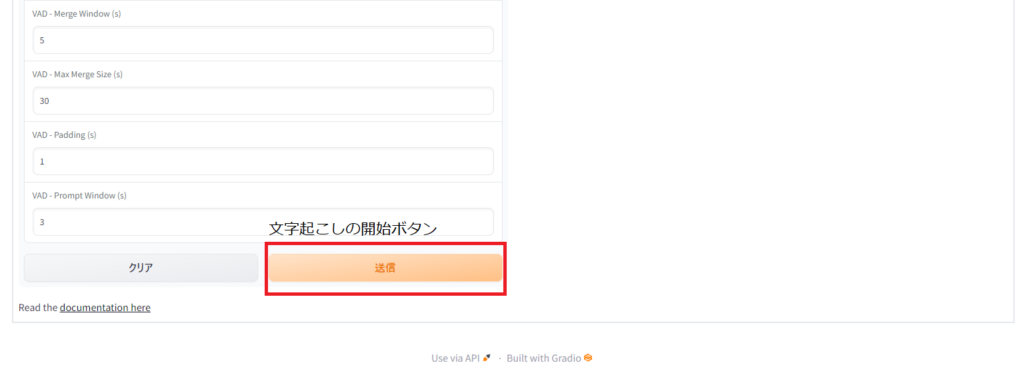
他にもいろいろな記事をあげているので、良かったら、ご覧ください。もし、わからない点があれば、投稿フォームからご質問をください。
【広告】Stable Diffusionをするなら、GPU搭載のPCがおススメです。自作もよいけど、難しい人はBTOのPCもコスパ良いですよ。




