

会議などの議事録を作成するのに便利な話者識別ライブラリPyannote.audio(ピアノート・オーディオ)を使ってみました。GitHubでオープンソースとして公開されています。Whisperなどのspeak-to-textと組み合わせることにより、議事録を簡単に作成することができます。MITライセンスで公開されており、適切なライセンスと著作権表示をすることで、商用利用も可能です。
※本記事は2023年1月現在の情報に基づき作成しています。(情報としては古いですがアーカイブとして残しています。)
前準備
Pyannote.audioは、必須ではありませんが、GPU環境での実施が推奨されています。GPU環境の構築については、参考記事へのリンクを示しますので、詳しくはそちらをご参照ください。
Windowsのネイティブ環境にvenvで仮想環境を構築し、Pyannote.audioをインストールしていきます。まず、好きなフォルダを作成し、そこで、仮想環境を作ります。Pyannote.audioはPython3.8推奨なので、Python3.8の環境を作成します。もし、別のバージョンのPythonの人や、Python自体をインストールしていない人は、Python3.8をインストールしておきます。(参考記事:Windowsで複数のバージョンのPythonをインストールする)
Python3.8系であれば、Python3.8.15がおススメです。下記のPythonの公式ページからご自分の環境にあったPythonをインストールしましょう。
仮想環境はターミナルからvenvで構築します。
> py -3.8 -m venv venv
> .\venv\Scripts\Activate.ps1
(venv)> python -m pip install -U pip setuptoolsCUDA11.7を入れる場合は、以下のようにPyTorchでGPUが使えるように設定します。
(venv)> pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117Pyannote.audioのインストール
必要なライブラリをインストールします。
GithubからPyannote.audioのクローンを作成します。もし、Gitをインストールしていない場合は、公式ページから入手してください。
git cloneコマンドで、githubからクローンを作成します。
(venv)> git clone https://github.com/pyannote/pyannote-audio続いて、requirements.txtのリストアップから、必要なライブラリをインストールします。
(venv)> pip install -r ./pyannote-audio/requirements.txt本体をインストールします。
(venv)> pip install pyannote.audioPyannote.audioの認証
pyannote.audioのモデルをダウンロードするためには、Hugging faceのトークンが必要になります。費用は発生しませんが、pyannote.audioを使って論文発表する際は引用したり、企業であったら、開発に寄付することを検討しましょう。
1.Hugging faceのアカウント作成
Hugging faceのページからアカウントを作成します。
2.https://huggingface.co/pyannote/speaker-diarizationのページから、所属とwebサイト、使用目的を入力して、同意ボタンを押します。
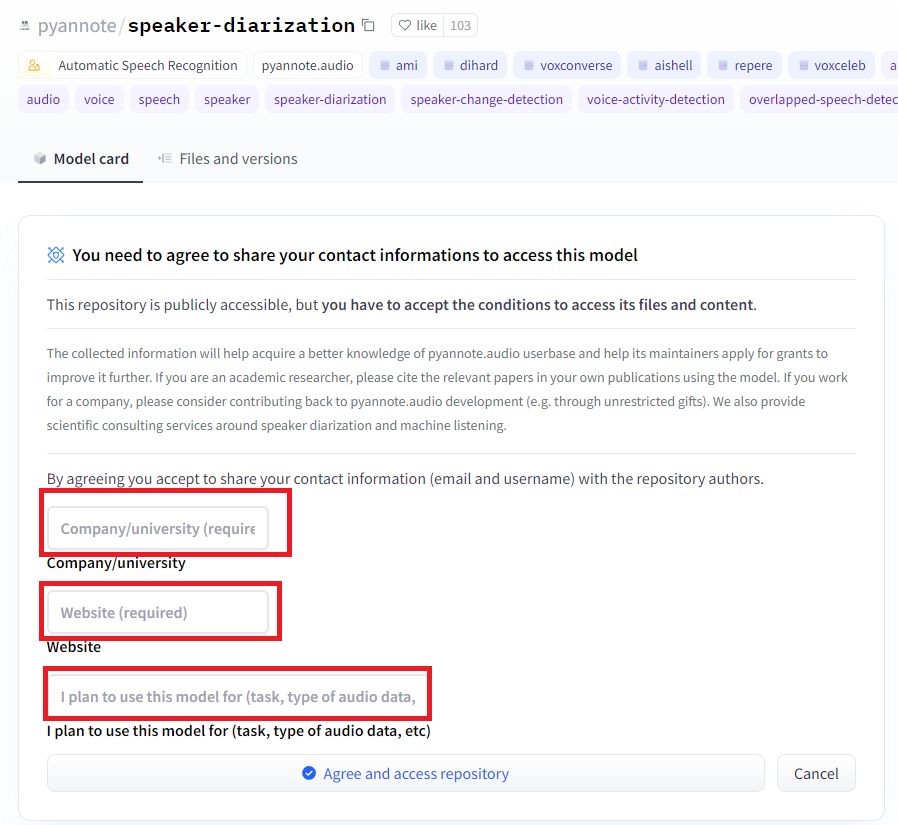
3.同様に、https://huggingface.co/pyannote/segmentationのページにも同じ情報を入力して、同意する。
4.https://huggingface.co/settings/tokensにアクセスして、New tokenから、pyannote.audioのトークンを作成し、入手する。
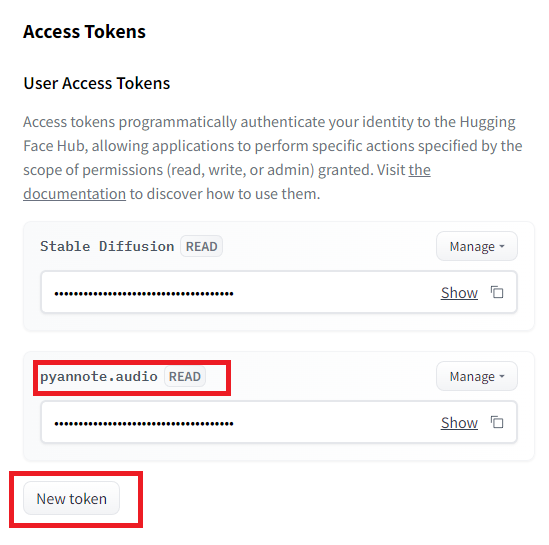
続いて、「.cashe」にトークンを保存します。まずターミナルなどで、hugging faceのCLIにアクセスします。トークンを聞いてきたら、先ほど作成したトークンを入力します。これで、CLIやPythonファイルでpyannote.audioが使えるようになります。
(venv)> huggingface-cli login
Token:
Add token as git credential? (Y/n) Y
Token is valid.
Your token has been saved in your configured git credential helpers (manager-core).
Your token has been saved to C:\Users\username\.huggingface\token
Login successful
もし、上記の実行時に権限エラーで実行できない場合、ターミナルのアイコンを右クリックで選択し、管理者として実行するとエラーは出ないと思います。
また、続いて、JupyterLabでインタラクティブ環境で使うためのライブラリをインストールし、JupyterLabを起動します。
(venv)> pip install jupyterlab
(venv)> pip install huggingface_hub
(venv)> jupyter lab実行後、以下のコマンドで、hunggingfaceのログイン画面が出てきますので、ここで、先ほどのトークンを入れてやると、Jupyter Labでpyannote.audioが使えるようになります。
from huggingface_hub import notebook_login
notebook_login()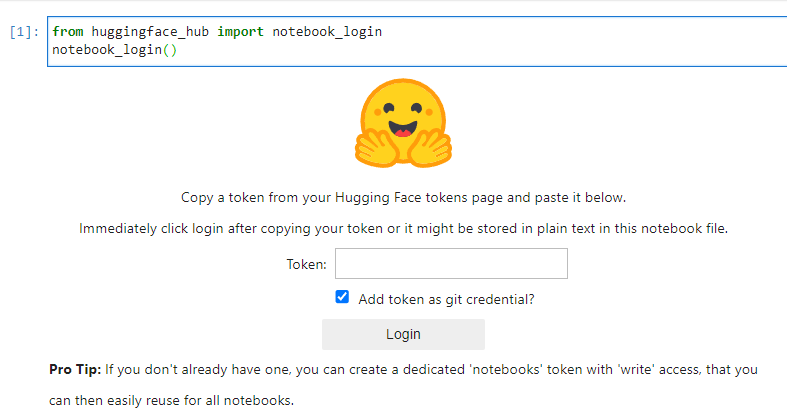
Pyannote.audioを使う
それでは使ってみます。今回はJupyterLabで使っていきます。サンプルの音声として、VoiceVoxで生成した会議の音声を使用します。過去の記事でPythonを使ってVoiceVoxエンジンを使った記事も書いているので、もし、音声生成について興味があれば、そちらもご覧ください。
VOICEVOXエンジンを使ったPythonでの「高」品質音声合成API
音声は、4人のVOICEVOXのキャラクターたちがAIに関するフリーディスカッションを行っています。ちなみに、音声のシナリオ原案はchatGPTで生成しています。音声は自由にダウンロードしてお使いください。
Pyannote.audioはPipelineでモデルを呼び出し、音声をあてがうだけで話者識別をしてくれます。モデルの呼び出しでは、トークンを通していれば、モデルをダウンロードしてきます。今回は、上の「meeting.wav」の話者識別をしてみます。
from pyannote.audio import Pipeline
pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization@2.1")
diarization = pipeline("meeting.wav")
for turn, _, speaker in diarization.itertracks(yield_label=True):
print(f"start={turn.start:.1f}s stop={turn.end:.1f}s speaker_{speaker}")start=0.5s stop=5.5s speaker_SPEAKER_01 start=6.6s stop=8.1s speaker_SPEAKER_03 start=9.0s stop=15.1s speaker_SPEAKER_00 start=16.0s stop=19.5s speaker_SPEAKER_03 start=20.3s stop=27.9s speaker_SPEAKER_02 start=28.7s stop=36.4s speaker_SPEAKER_03 start=37.3s stop=46.5s speaker_SPEAKER_00 start=47.4s stop=54.8s speaker_SPEAKER_02 start=55.6s stop=63.7s speaker_SPEAKER_03 start=64.5s stop=69.2s speaker_SPEAKER_00 start=70.1s stop=75.5s speaker_SPEAKER_02 start=75.5s stop=75.6s speaker_SPEAKER_01 start=76.2s stop=85.5s speaker_SPEAKER_01
上記のように話者を特定できました。上の結果でSPEAKERの00は波音リツ、01は冥鳴ひまり、02は四国めたん、03はずんだもんですので、後付けで、SPEAKERとして当てはめてやると、誰がどのタイミングで話したかわかりやすくなります。
speaker_dict = {"SPEAKER_00":"波音リツ","SPEAKER_01":"冥鳴ひまり","SPEAKER_02":"四国めたん","SPEAKER_03":"ずんだもん"}
for turn, _, speaker in diarization.itertracks(yield_label=True):
speaker_name = speaker_dict[speaker]
print(f"開始={turn.start:.1f}s 終了={turn.end:.1f}s 発言者: {speaker_name}")開始=0.5s 終了=5.5s 発言者: 冥鳴ひまり 開始=6.6s 終了=8.1s 発言者: ずんだもん 開始=9.0s 終了=15.1s 発言者: 波音リツ 開始=16.0s 終了=19.5s 発言者: ずんだもん 開始=20.3s 終了=27.9s 発言者: 四国めたん 開始=28.7s 終了=36.4s 発言者: ずんだもん 開始=37.3s 終了=46.5s 発言者: 波音リツ 開始=47.4s 終了=54.8s 発言者: 四国めたん 開始=55.6s 終了=63.7s 発言者: ずんだもん 開始=64.5s 終了=69.2s 発言者: 波音リツ 開始=70.1s 終了=75.5s 発言者: 四国めたん 開始=75.5s 終了=75.6s 発言者: 冥鳴ひまり 開始=76.2s 終了=85.5s 発言者: 冥鳴ひまり
その他の機能
pyannote.audioでは話者の人数を自動で判断してくれますが、明示することで精度を上げることができます。
# 人数を設定して、話者識別をする
diarization = pipeline("meeting.wav", num_speakers=4)
# 人数の上下限を設定して、話者識別する
diarization = pipeline("meeting.wav", min_speakers=2, max_speakers=10)また、jupyter labなどのインタラクティブ環境で、計算したダイアライゼーションを直接指定することで、タイムラインを表示することができます。
diarization = pipeline("meeting.wav")
diarization
ダイアライゼーションの中身を見ると、下記のようになっていて、それぞれ会話の切れ目でセグメントを分割し、内部的にスコアを比較して、近い音声を同じスピーカーとして割り当てているようです。
list(diarization.itertracks(yield_label=True))[(<Segment(0.497812, 5.49281)>, 'D', 'SPEAKER_01'), (<Segment(6.60656, 8.12531)>, 'J', 'SPEAKER_03'), (<Segment(8.98594, 15.1284)>, 'A', 'SPEAKER_00'), (<Segment(15.9722, 19.4653)>, 'K', 'SPEAKER_03'), (<Segment(20.2753, 27.9028)>, 'G', 'SPEAKER_02'), (<Segment(28.7128, 36.3909)>, 'L', 'SPEAKER_03'), (<Segment(37.2516, 46.5159)>, 'B', 'SPEAKER_00'), (<Segment(47.3766, 54.8353)>, 'H', 'SPEAKER_02'), (<Segment(55.6284, 63.6609)>, 'M', 'SPEAKER_03'), (<Segment(64.4709, 69.1959)>, 'C', 'SPEAKER_00'), (<Segment(70.0734, 75.5072)>, 'I', 'SPEAKER_02'), (<Segment(75.5072, 75.5578)>, 'E', 'SPEAKER_01'), (<Segment(76.1822, 85.4634)>, 'F', 'SPEAKER_01')]
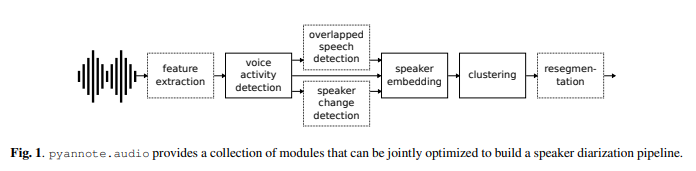
さらに、pyannote.audioでは二人以上の音声がオーバーラップした場合でもある程度見極めてくれるようです。(詳細は開発した方の論文をご参照ください。)
最後に
話者識別のライブラリpyannote.audioを紹介しました。これをwhisperなどのライブラリを組み合わせることで、発言した人を認識した議事録なんかも作れそうです。それについてもまた、記事にしてこうと思います。

