

WindowsローカルにOpenAIのWhisperをインストールして環境構築して、日本語音声の文字起こしをしてみます。実際にWhisperがどんなものか使ってみた体験レポートをお送ります。
※本記事は2022年9月現在の情報に基づき作成しています。(情報としては古いですがアーカイブとして残しています。)
Whisperとは
WhisperはOpenAIがニューラルネットワークで学習した音声認識のオープンソースです。インターネットから収集した68万時間の多言語・マルチタスク教師付きデータで学習し、アクセント、背景雑音、専門用語に対応可能で、多言語での書き起こしや、翻訳も可能で、オープンソースで公開されているため、適切なライセンス表示を行えば、商用利用や有償利用も可能なライブラリです。
Windowsのローカル環境への構築
すでにWebAPIやGoogle Colaboratoryなどで手軽に使うことができるようですが、ここではWindowsローカル環境にWhisperの開発環境を構築してみます。ネットの情報によればそれなりのPCの性能が必要とのことでしたが、一応、StableDeffusionもインストールして、普通に使えるくらいの性能のあるPCなので、大丈夫だろうと踏んでいます。。。
私の環境は下の通り。
本体:Dell G5 5590
スペック:CPU Intel Core i7-9750H メインメモリ 32GB
グラフィックボード NVIDIA GeForce GTX 1660 Ti
OS:Windows 11 Home / Python 3.10.4
GitHubの公式ページを参考に環境構築してみました。
環境構築の準備
以下の環境を準備します。
- Python3.7以降
- 最新版のPyTorch
それぞれインストールはネット上で簡単に情報は見つけることができます。PyTorchは公式ページから入手可能です。ちなみに私のPytorch1.12.1-CUDA11.6のバージョンがインストールしてあります。
ffmpegのインストール
Whisperは音声の読み込みなどを行うためにffmpegをインストールする必要があります。ffmpegは動画や音声を扱うためのフリーウエアです。ffmpegは下の公式ページからダウンロードしてインストールできます。

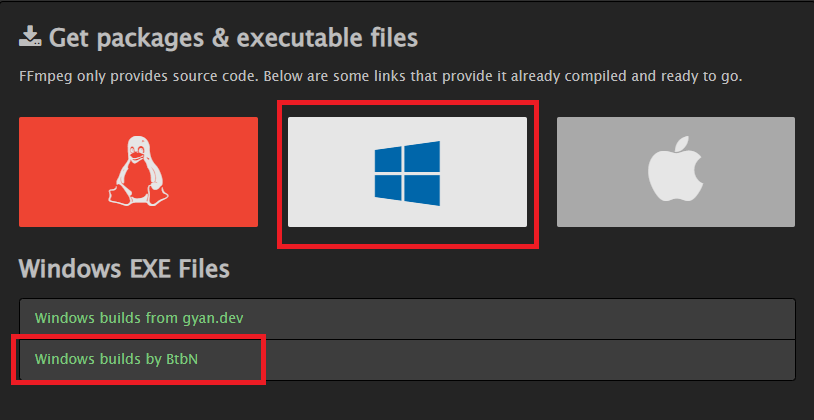
windows版は「Windows builds by BtbN」を選んでその先のzipファイルをダウンロードします。
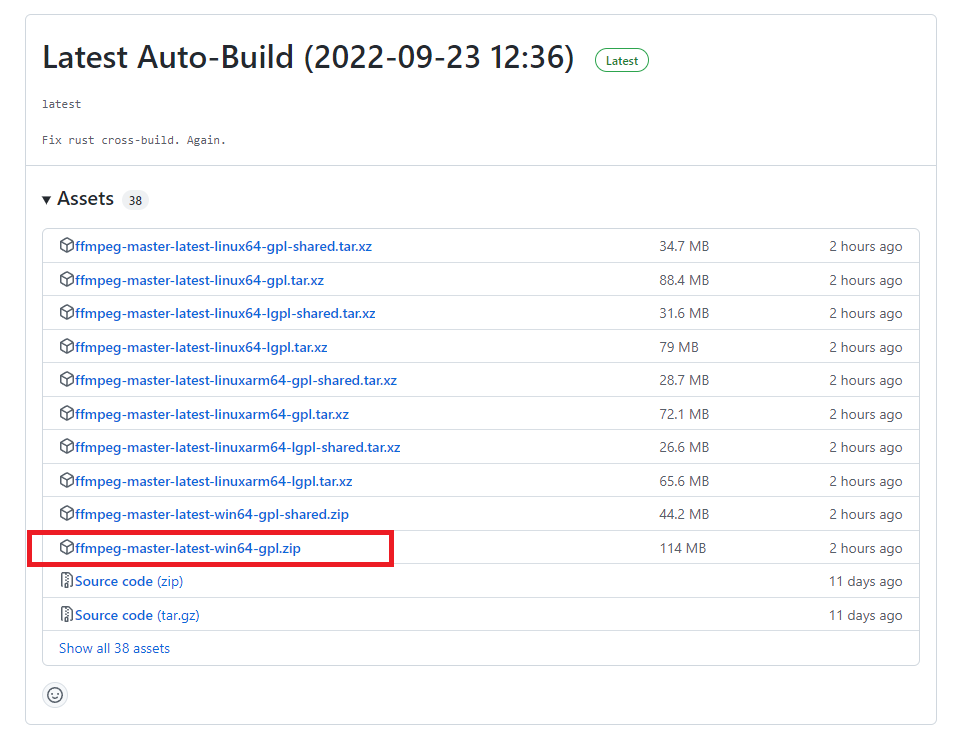
ダウンロードしたzipファイルを適当な場所に解凍したあと、環境変数名の編集からbinフォルダにPATHを通してから、一旦PCを再起動します。
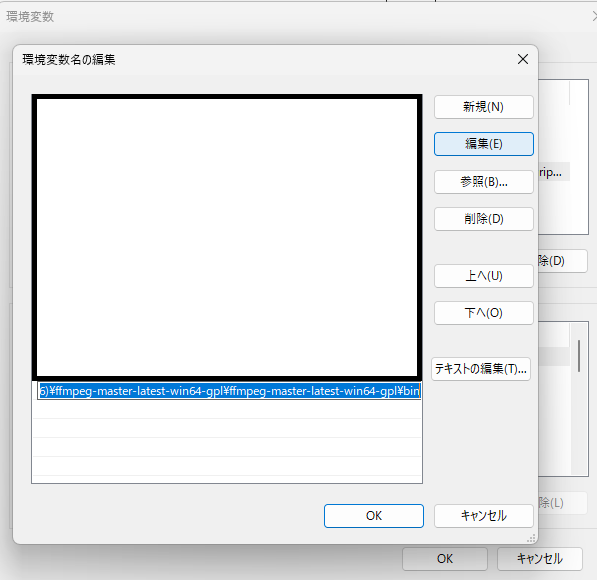
> ffmpeg
ffmpeg version N-108306-ge7a987d7c9-20220923 Copyright (c) 2000-2022 the FFmpeg developers
built with gcc 12.1.0 (crosstool-NG 1.25.0.55_3defb7b)Shellから「ffmpeg」と入力するとffmpegの情報が表示され、インストールできたことが分かります。
Whisperと関連ライブラリのインストール
Whisperと関連ライブラリをpipコマンドでインストールします。足りないライブラリとWhisperをインストールしてくれます。
> pip install git+https://github.com/openai/whisper.git
Installing collected packages: more-itertools, ffmpeg-python, whisper
Successfully installed ffmpeg-python-0.2.0 more-itertools-8.14.0 whisper-1.0これでインストール完了です。
Whisperを使ってみる
それでは使ってみましょう。jupyter labから起動してみます。音声にはスマホのアプリで録音したかなり活舌の悪いw私が「本日は晴天なり、本日は晴天なり。テスト、テスト。」とささやいた声のデータを使っています。解析は公式ページに記載の通り打ち込んでみます。モデルには”base”という軽量のモデルを使っています。
# ライブラリの読み込み
import whisper
# モデルの読み込み
model = whisper.load_model("base")
# 音声データの読み込みと30秒のデータへのトリミング処理
audio = whisper.load_audio("record01.m4a")
audio = whisper.pad_or_trim(audio)
# 音声データのログメルスペクトログラムへの変換
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# 言語の検知と出力
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# 音声の解読
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# 認識したテキストの出力
print(result.text)
Detected language: ja 本日は正点なり 本日は正点なり テストテスト
コードはエラーもなく、何と一発で私のしゃべったことを(漢字がちょっと違うけど)、認識してくれました。すごいです。でも、発音は合っていますが、漢字はぐちゃぐちゃです。そこで次は使用するモデルを”medium”に変えてやってみました。上のコードのモデルの読み込みのところを以下のように変えます。初回は、モデルのwebからダウンロードしてくるので、少し時間はかかりますが、同じように実行すると、今度はちゃんと漢字もあった内容で出力できました。
model = whisper.load_model("medium")Detected language: ja 本日は晴天なり、本日は晴天なり、テストテスト。
公式ページから各モデルの比較を抜粋を下表に示します。私のPCのGPUのメモリ容量は6GBなので、mediumが限界のようです。(WERは論文『Robust Speech Recognition via Large-Scale Weak Supervision』からCommon Voiceでの結果(Table11)のデータを参考のため抜粋)
| 大きさ | パラメータ数 | 英語用モデル名 | 多言語モデル名 | 必要なVRAM | WER% 英語※ | WER% 日本語※ | 相対速度 |
|---|---|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | 28.8 | 36.1 | ~32x |
| base | 74 M | base.en | base | ~1 GB | 21.9 | 24.2 | ~16x |
| small | 244 M | small.en | small | ~2 GB | 14.5 | 14.0 | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | 11.2 | 10.5 | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 10.1 | 9.4 | 1x |
一方で、各モデルでのWER(Word Error Rate)、つまり単語エラー率を論文の中で詳しく解析しています。これを見ると、日本語では、mediumとlargeではあまりWERに違いがないようです。
長い音声からの文字起こし
長い音声の文字起こしをしてみます。使うデータは政府広報オンラインのページの音声広報CD「明日への声」の2022年9月発行(vol.87)から「夕暮れ時には車に注意!歩行者が亡くなる交通事故が多発しています。」という7分40秒の音声データ(プロのアナウンサーの方がしゃべっている非常に聞き取りやすい音声)の文字起こしをやってみます。

ここではJupyter Labでは試行ごとにうまくメモリが開放されないため、すぐにメモリオーバーをおこしてしまうため、ここではPythonの実行ファイルを作成して文字起こしをしてみました。
import whisper
import time
start = time.time()
model = whisper.load_model("base")
result = model.transcribe("onseicd_202209_02.mp3")
print(result["text"])
end = time.time()
print(end-start)import whisper
import time
start = time.time()
model = whisper.load_model("medium")
result = model.transcribe("onseicd_202209_02.mp3")
print(result["text"])
end = time.time()
print(end-start)実行時間比較、メモリの使用量
7分40秒のmp3の文字起こし時間の比較は以下の通りでした。私のPCではやはりmediumでぎりぎりで、実行時間はbaseがmediumの10倍くらい早く、相対的な速度は公式ページの「8倍」と同じくらいでした。
| モデル | 実行時間 | VRAM使用量 |
| base | 1分6秒 | max 2.2GB |
| medium | 10分54秒 | max 5.8GB |
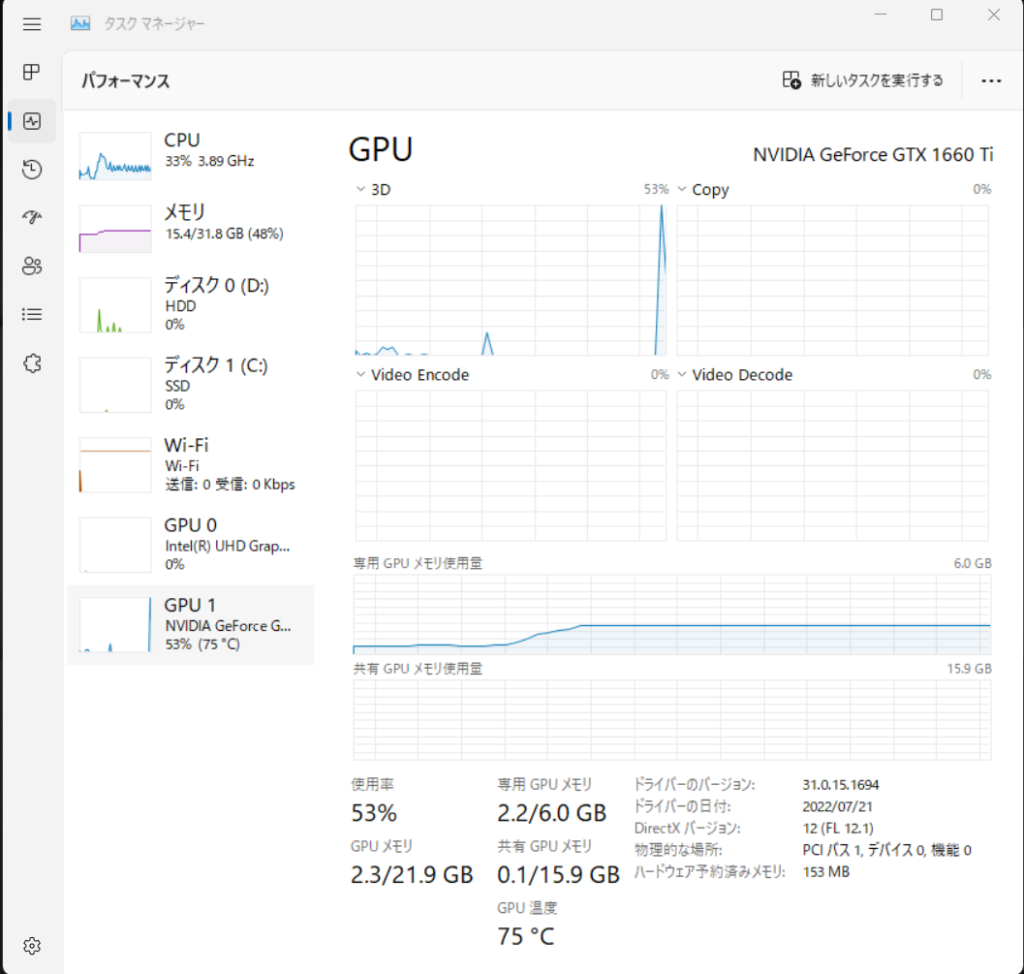
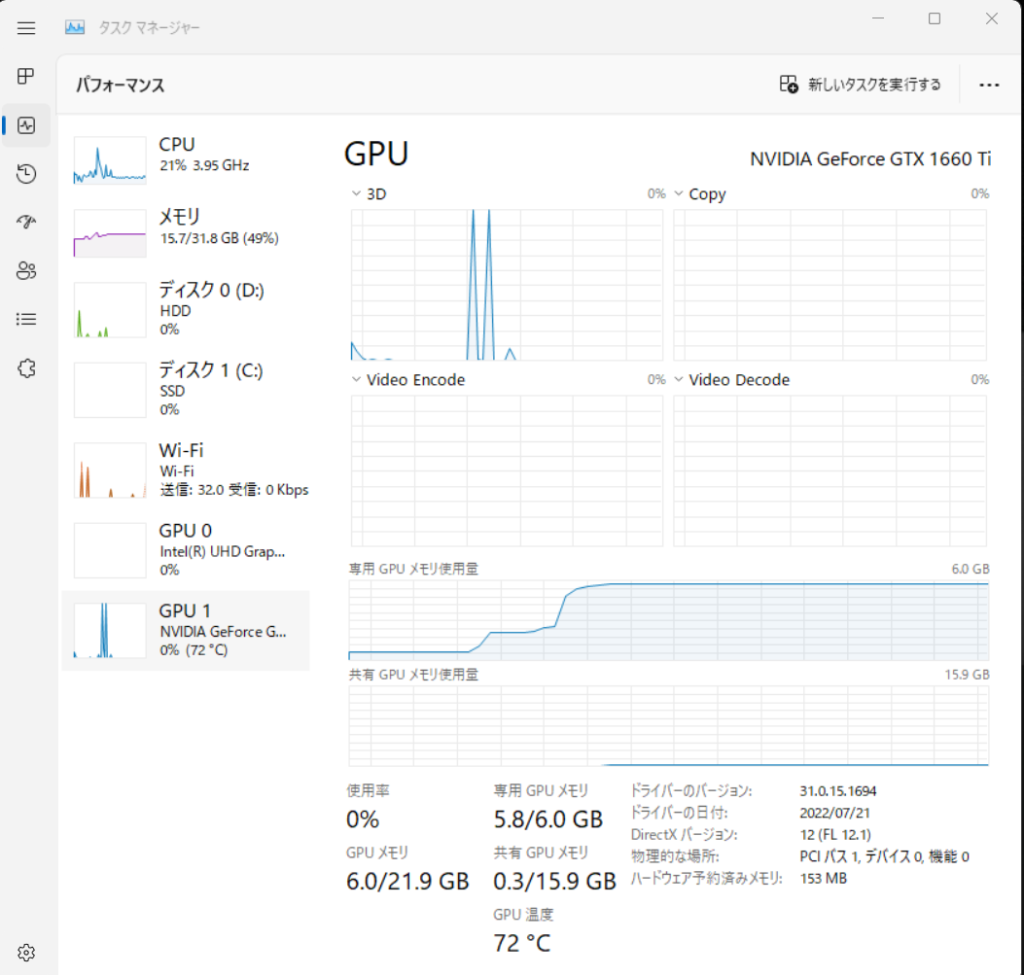
文字起こしの結果比較
下の文字起こし結果の比較を示します。


冒頭の部分を見てみます。(ちなみに文字起こしの正解はこちらです。)
[baseモデル使用] トラックナンバーに、ユングレドキには車に注意、保校車が無くなる交通事故が 出発しています。日々ごつ時間が早まる今の時期、ユングレドキは急激に暮らくなっていくため、車を運転するドライバーは、暮らさの変化になれず、保校車に気づきにくくなります。そのためユングレドキは、1日の中でも、保校車が死亡する交通事故が 出発する危険な時間帯です。事故を防止するための注意点を知っておきましょう。
[mediumモデル使用] トラックナンバー2 夕暮れ時には車に注意歩行者が亡くなる交通事故が多発しています日没時間が早まる今の時期 夕暮れ時は急激に暗くなっていくため車を運転するドライバーは暗さの変化になれず 歩行者に 気づきにくくなりますそのため夕暮れ時は一日の中でも歩行者が死亡する交通事故が多発する危険な時間帯です事故を防止するための注意点を知っておきましょう
baseモデルを使用した方は、言葉の発音としては概ね近いものが出力できているのですが、単語の意味や言葉などはかなり間違っています。一方で、mediumモデルを使用した方は完璧といってよいレベルで文字起こしができています。他の部分を見ると、明らかに間違っていそうなものは、『19時台』を『19時代』としたり、『死角』を『四角』と間違っているところはありますが、私の感覚では、人間が文字起こしするときの誤変換の発生してしまう頻度と似たり寄ったりのような気がします。私のPCでここまでできるので、もっと高性能なPCを使ったり、上位のlargeモデルを使えば、さらに速度や精度が上がるような気がします。
最後に
最近話題のオープンソースのAIですが、社会を大きく変えるポテンシャルを持っています。このOpenAIのWhisperもこれまで人がやっていた議事録作成などをサポートする強力なツールになる気がします。そのライブラリも商用利用可能ですので、Stable Deffusionのようにすぐに商用ツールの拡張機能として搭載されてくる気がします。本当に便利な世の中になります。(個人的にはTeamsのトランスクリプションは現状精度が低いので、Whisperのモデルを適用して早く精度をあげてほしいものですが。私の声は活舌が悪すぎてまともに文字起こしされたことがないので。。。)
関連記事
WhisperWebUIを含めて、詳しくまとめ直しました。

【広告】Whisperをするなら、GPU搭載のPCがおススメです。自作もよいけど、難しい人はBTOのPCもコスパ良いですよ。




