

Krita AI Diffusionは無料でAI画像生成ができるペイントツールです。ここでは、2024年7月時点での最新のバージョン1.19.0のセット方法を解説したいと思います。
Krita AI Diffusionは画像の一部をAIで加工したり、下絵に対して、AIを適用して画像生成したり、多機能なAI画像生成ツールです。現在も頻繁にアップデートされていて機能の追加などが行われています。ここでは、最新版のKrita AI Diffusionをセットアップする方法を解説したいと思います。
記事の内容はYouTubeでも紹介しているので、ご参考ください。

パソコンのシステム要件
AI画像生成を使うためにVRAMが8GB以上のNVIDIA製GPUを搭載したWindowsパソコンを推奨します。それ以下のGPUやCPUでも使えることはありますが、非常に遅かったり、大きな画像が生成できなかったりします。おすすめのPCについては別の記事でも紹介しているので、ご参照ください。(ローカル環境で画像生成AIを始めたい人への2024年夏のおすすめパソコン)
Kritaのセットアップ
Kritaは以下のKrita公式サイトからダウンロードできます。メッセージに従ってダウンロードしてインストールしましょう。ダウンロードして、好きなところにインストールします。
Krita AI Diffusionのプラグインのダウンロード
Kritaをインストールしたら、Krita AI Diffusionのプラグインをダウンロードします。AI DiffusionはGitHubの公式サイトからダウンロードできます。
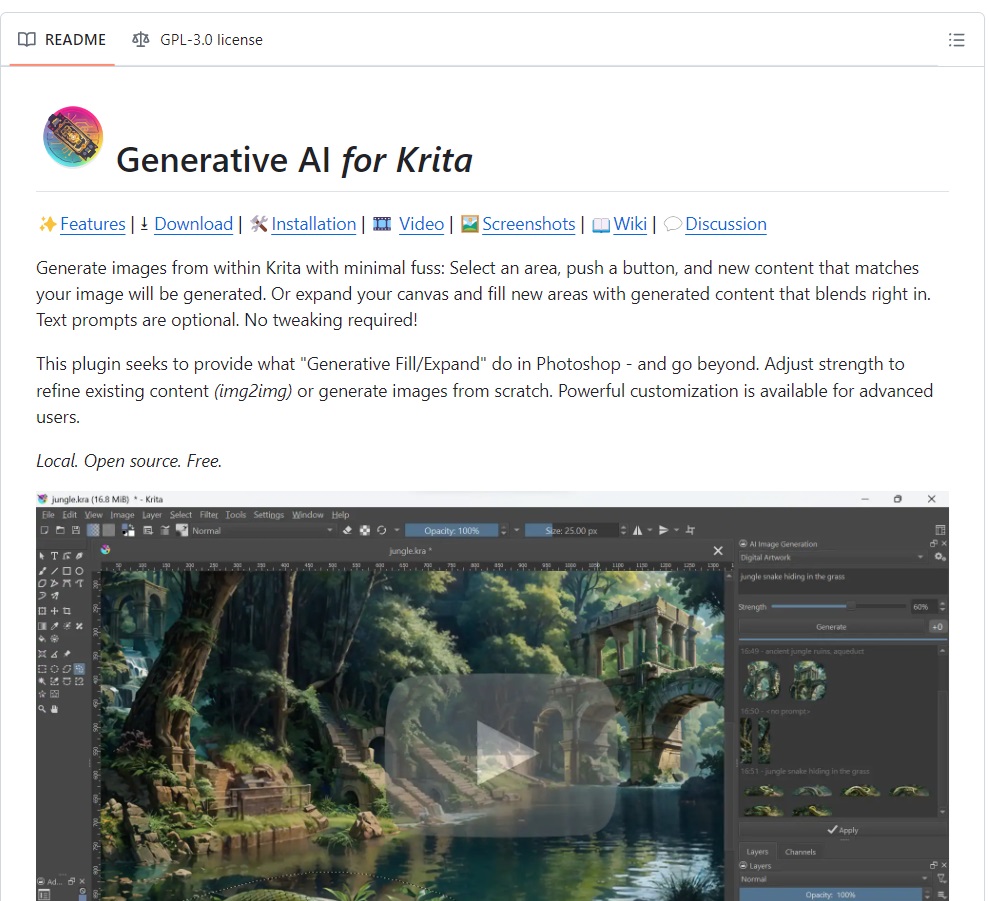
プラグインは、ページの中ほどにある「Download the plugin」をクリックして最新版のプラグインファイルのページに移動します。
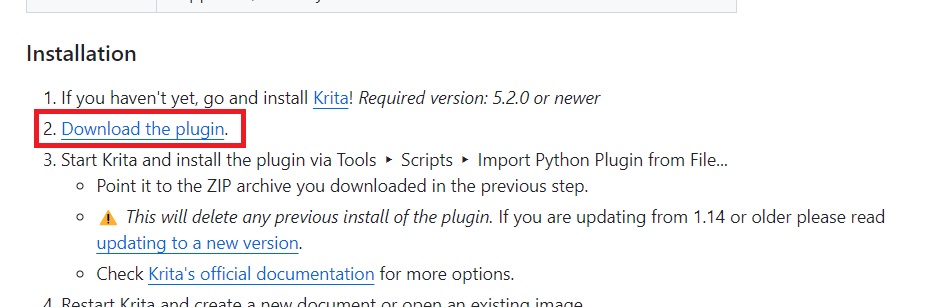
2024年7月現在の、最新バージョンは1.19.0です。現在もどんどん新しい機能が追加されているので、新しいバージョンのAI Diffusionを使いましょう。「Donwload krita_ai_diffusion-1.19.0.zip」をクリックして、ローカルドライブにダウンロードします。(バージョンアップする場合も同様です)
Krita AI Diffusionのプラグインのセットアップ
Kritaを起動してKrita AI Diffusionをセットアップします。
まず、前準備としてKritaのプラグインなどの保存する場所を確認します。「設定」→「Kritaの設定を変更」を選択します。
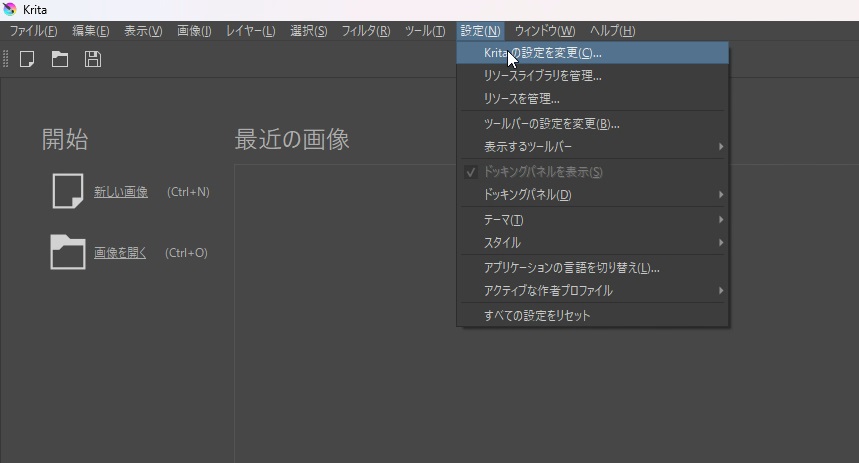
「全般」→「リソース」を開いて、その中の「リソースフォルダ」でKritaのプラグインなどを保存する場所を変更することができます。(デフォルトのままでOKです。以前のバージョンではリソースフォルダ内にAI Diffusionのスタイル設定などが保存される設定でしたが、現在のバージョンではユーザーデータ内にこれらの設定ファイルが保存される仕様になったため、変更は必須ではなくなりました。)変更した場合は、Kritaを再起動します。
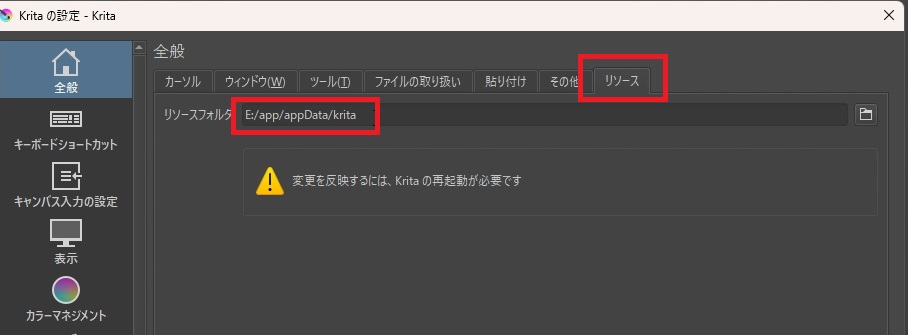
続いて、「ツール」→「スクリプト」→「Pythonプラグインをファイルからインポート」を選択して、先ほどダウンロードした「Donwload krita_ai_diffusion-1.19.0.zip」(バージョンによってファイル名は異なります)を選択して、インポートします。その時、事前にzipファイルを解凍しておく必要はありません。
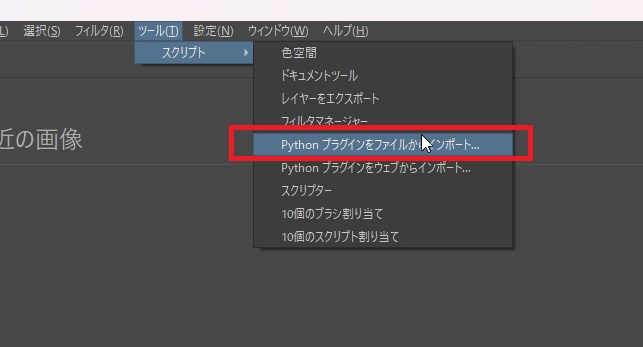
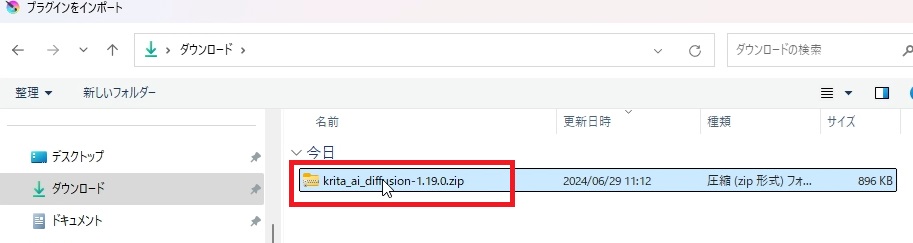
インポートに成功すると下のようなメッセージが出ますので、「はい」をクリックして、プラグインを有効にして、Kritaを再起動します。
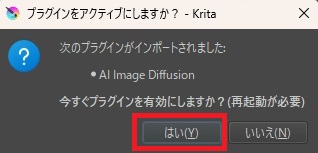
再起動したら、プラグインが有効になっていることを確認するために、「設定」→「Kritaの設定を変更」から、「Pythonプラグインマネージャ」を選んで、下記のように「AI Image Diffusion」にチェックが入っているのを確認します。
AI関連ツール(ComfyUI等)のダウンロードとセットアップ
プラグインのセットアップが完了したら、画像生成AIツールの本体をセットアップしていきます。Krita AI DiffusionはバックグラウンドでComfyUIというStable Diffusionの実行ツールを動かして画像生成します。ComfyUIについては、私の過去のブログ記事(リンク、リンク、リンク、リンク)でも紹介していますが、セットアップや設定がやや複雑です。しかし、Krita AI Diffusionでは、すべて自動でComfyUIを組み込むことができるので、設定が難しいComfyUIの拡張機能やWorkflowと呼ばれる画像生成の仕組みを意識することなく、画像生成AIのツールを使うことができます。
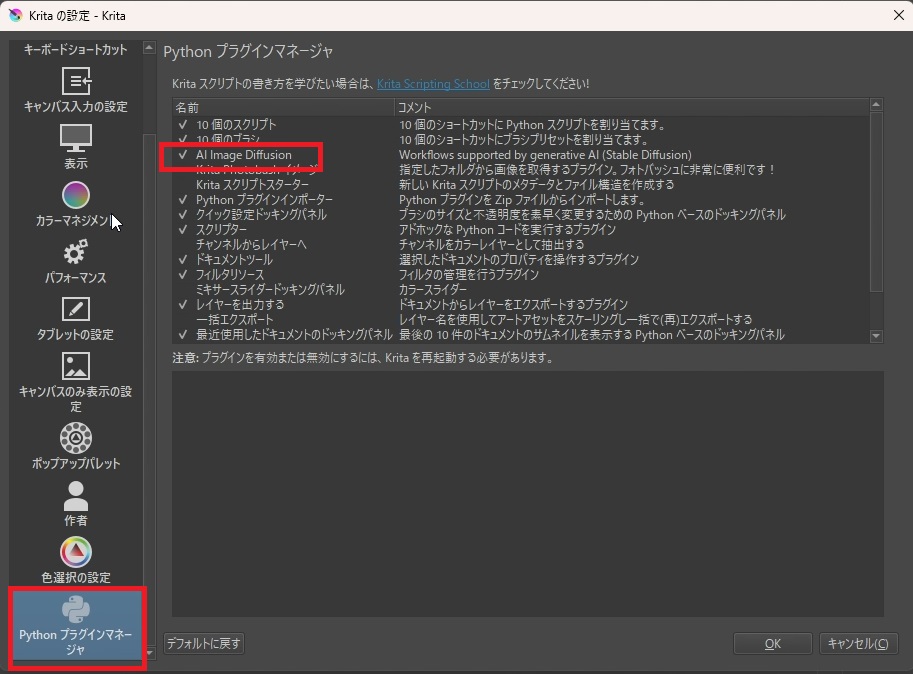
まず、「ファイル」→「新しいドキュメント」から、新しいドキュメント(キャンパス)を開きます。
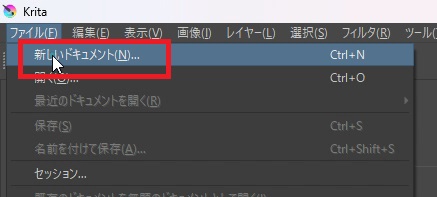
ここで、開く画像のサイズは任意に設定できますが、私は標準的な縦長の画像を作る時は896×1152をよく使います。新規で開くドキュメントのサイズを決めたら「作成」ボタンを押します。
ドキュメントが開いたら右下の「AI Image Generation」のボックスを開きます。
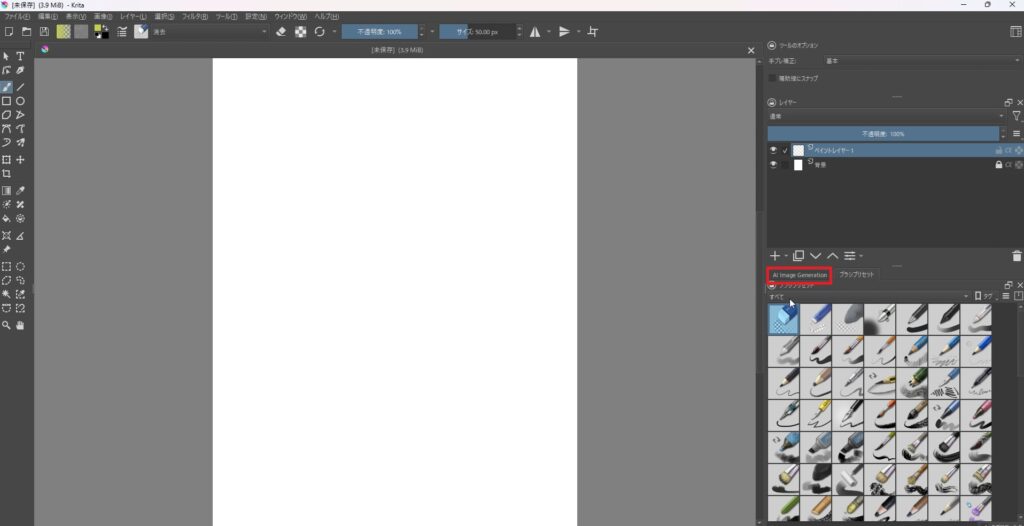
下記の画面の「Configure」のボタンをクリックします。
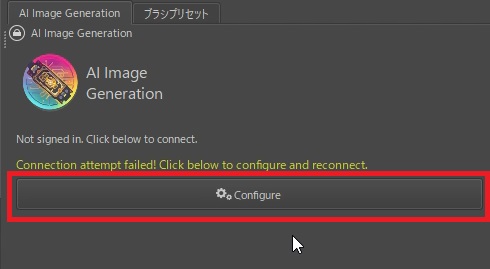
下のような画面が開きます。「Connection」から「Local Managed Server」を選択します。
すでにComfyUIをお使いの方は、「Custom Server (Local or remote)」を選択することで、使っているComfyUIと連動することもできますが、私は推奨しておりません。拡張機能の設定など、難しい設定が必要になり、動作が不安定になる場合があります。もし、される場合は、あとから説明するモデルファイルのみを連動する方法をお勧めします。
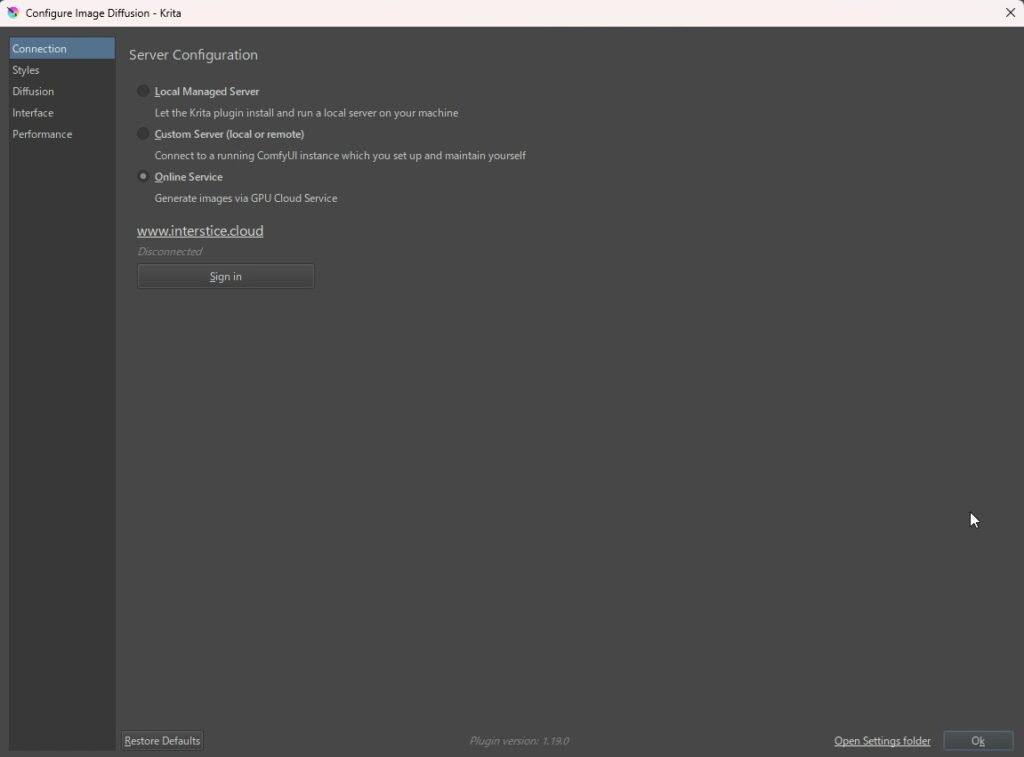
「Local Managed Server」の設定で、「Server Path」の設定します。ComfyUIはギガバイトくらすのモデルを含むため、ComfyUIをセットアップする場所は、30GB以上の空容量のあるストレージのPathを選ぶ方が良いです。ここでは、最低10GBとありますが、各種モデルをインストールする場合、10GBでは容量が足りなくなります。私は、後から増設したSSDのEドライブ内にセットアップしています。選ぶドライブは、HDDより、ファイルの読み込みなどが高速なSSDのドライブをお勧めいたします。
ComfyUIをセットアップするPartを設定したら、Intallボタンをクリックして、ComfyUI本体をセットアップします。インストールは自動で行われます。
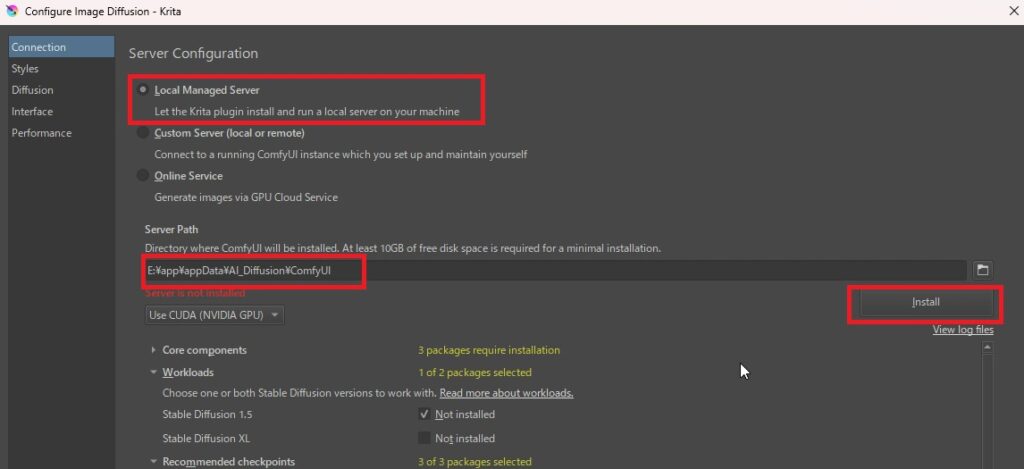
ComfyUIの基礎部分のセットアップできたら、続いてオプション部分をセットアップします。ControlNetなどをモデルのチェックボックスにチェックを入れます。使うものだけにチェックを入れたら良いですが、もし、ストレージの容量に余裕がある場合は、「upscalers」と「Control extensions」のところにある項目にはすべてチェックしてダウンロードしておくとよいと思います。(ダウンロードにはかなり時間が掛かります。また、ダウンロード先のサーバーの状況によりダウンロードが失敗することがありますが、その場合は時間をおいてからお試しください。)
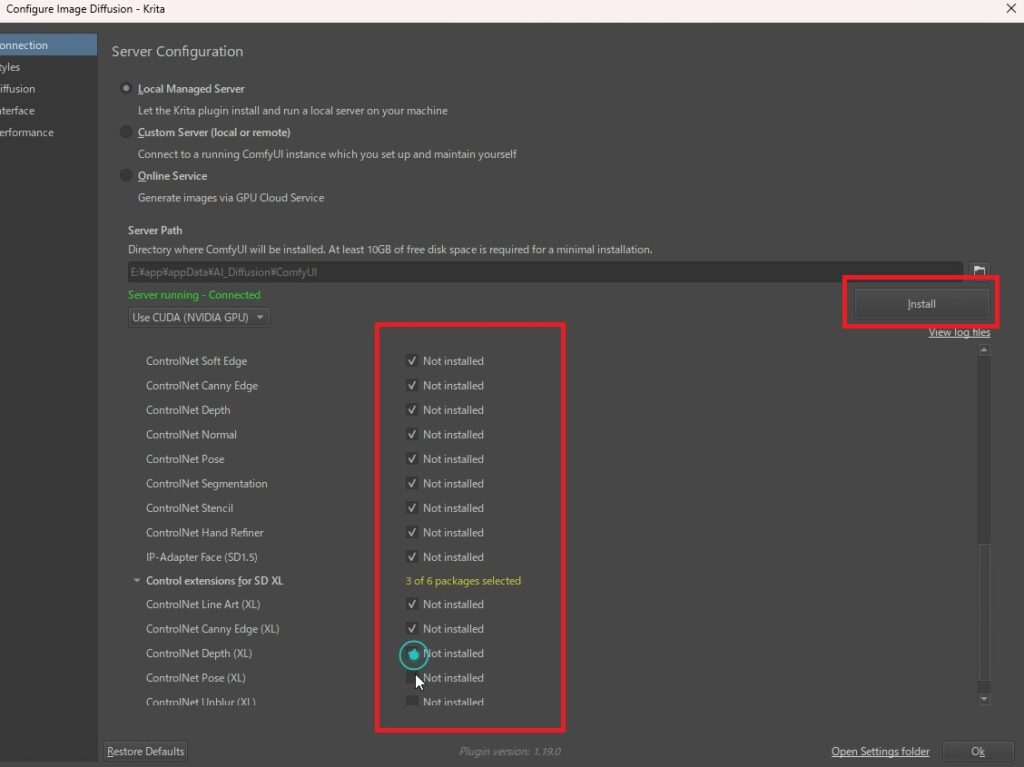
画像生成AIサーバー(ComfyUI)のセットアップが完了しました。「OK」ボタンを押して、「Configure」を閉じます。
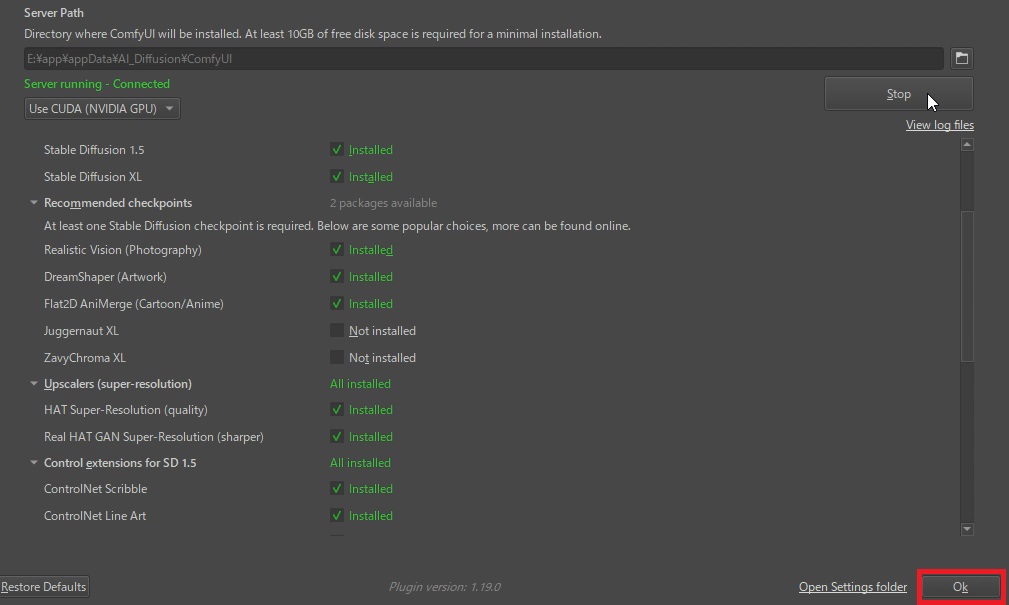
Stable Diffusionモデルのダウンロード
続いて、Stable Diffusionのモデルをセットアップする方法を説明します。すでに上のComfyUIをセットアップするときに一緒にいくつかのモデルもダウンロードされていると思います。それを使っても良いですが、ここでは、新しいモデルを追加する方法を解説します。
オンラインでは有志によって多くのStable Diffusionのモデル(checkpoint)が公開されています。モデルは、Higging FaceやCivitaiなどのサイトで公開されることが多いです。それぞれ使用条件などをしっかりご確認の上、自己責任でご使用ください。ここではアニメ系の高画質画像を得意とするAnimagine XL 3.1を例に手順を紹介します。
公開サイトはそれぞれ下記のリンクからいけます。(ダウンロードにはユーザー登録などが必要な場合がありますが、無料でダウンロードできると思います。)
Animagine XL 3.1(Hugging Face)
Animagine XL 3.1(Civitai)
Hugging Faceからのモデルダウンロード
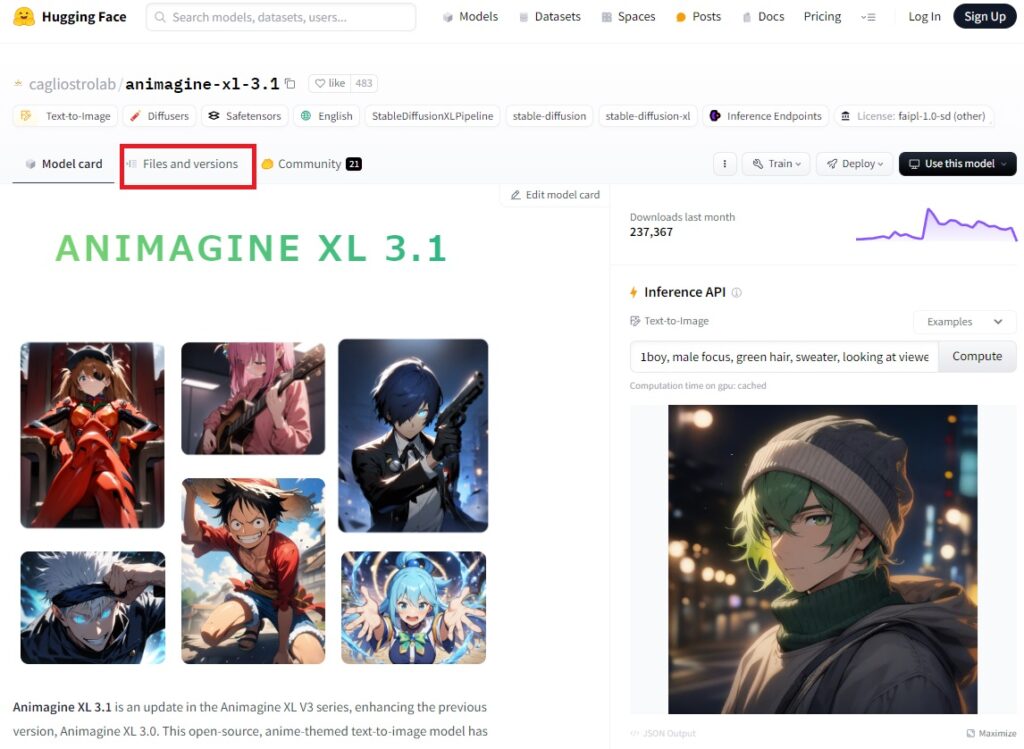
Animagine XL 3.1をHigging Faceからダウンロードするには、Animagine XL 3.1(Hugging Face)にアクセスします。ここには、モデルの使い方や使用例などが記載されています。その中で、トップ付近の「Files and versions」をクリックします。
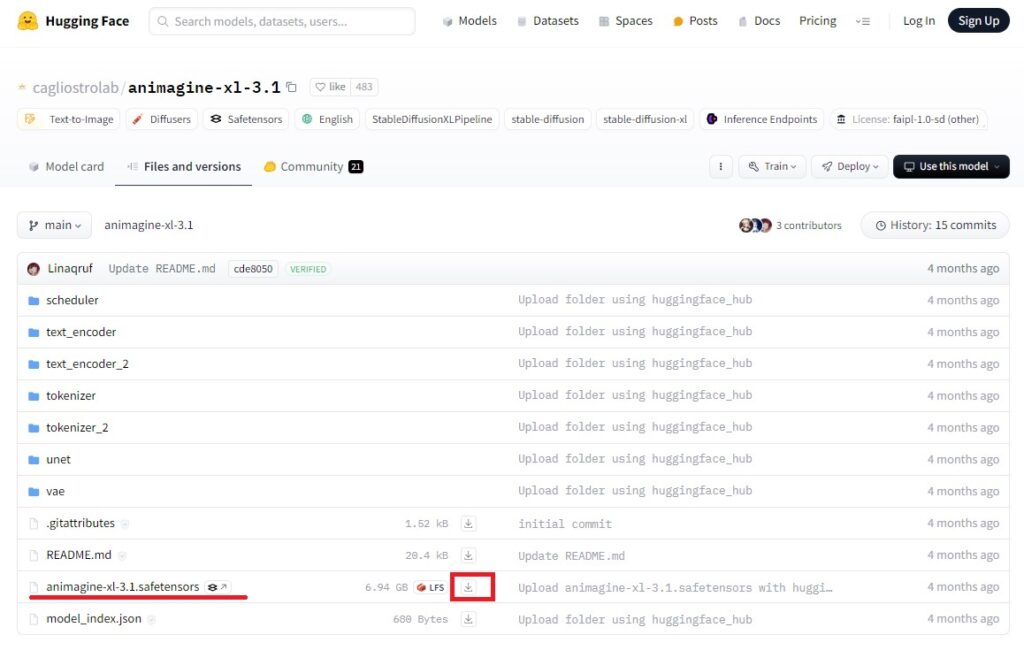
関連ファイル一覧が示されます。その中の「animagine-xl-3.1.safetensors」が目的のモデルファイルになります。右側のダウンロードマークをクリックするとブラウザからダウンロードできます。6.94GBとファイル容量が大きいのでお気を付けください。
Civitaiからのモデルダウンロード
同様にAnimagine XL 3.1は、Civitaiからもダウンロードできます。Animagine XL 3.1(Civitai)にアクセスし、「v3.1」が選択された状態で、トップページ右側のダウンロードマークから、「Full Model fp16(6.46GB)」をクリックするとダウンロードが始まります。Civitaiは時間帯によってはダウンロードするのに非常に時間が掛かることがあるので、ご注意ください。
ダウンロードしたモデルの保存場所
ダウンロードしたモデルを使うには、モデルを適切な場所に保存する必要があります。上のComfyUIのセットアップの時に設定した「server path」のPathの下の「ComfyUI」→「models」→「checkpoints」の中に保存します。
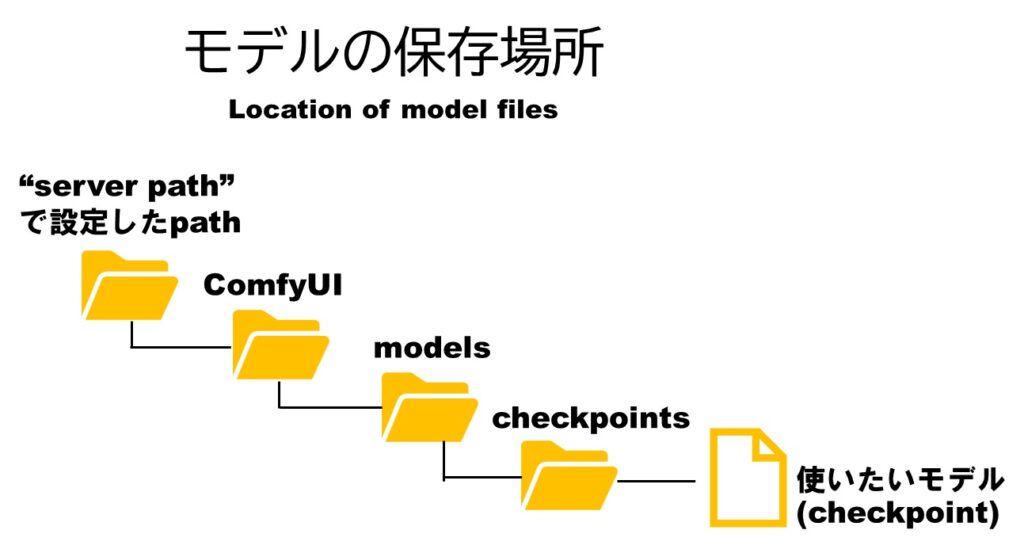
インストール済みのStable Diffusionと共通のモデルを使用する方法
すでにStable Diffusionをお使いの方は、Stable Diffusioで使っているモデルを、Krita AI Diffusion (ComfyUI)で使うように設定できます。別のアプリ、それぞれでモデルを持つ必要がなくなるので、ストレージの節約になります。
server pathで設定したpathの中のComfyUIのフォルダの中に、「extra_model_paths.yaml.example」というファイルがあります。それをメモ帳などのテキストエディタで開きます。その7行目に以下のような記述があります。
base_path: path/to/stable-diffusion-webui/
そこをお使いのStable Diffusion WebUIのpathに変更します。
例えば、私の場合は、Eドライブ直下にあるので、下記のようになります。
base_path: E:\stable-diffusion-webui
変更したら、「名前を付けて保存」でファイル名から「.example」を外して、「extra_model_paths.yaml」というファイル名で保存します。これで、Kritaを再起動すると、Stable Diffusion WebUIで使っているモデルなどが使えるようになります。
スタイルの設定
続いて、Animagine XL3.1をKrita AI Diffusionで使うためのスタイル設定を行います。Kritaで新しいドキュメントを開きます。ここでは896×1152の画像サイズの新規ドキュメントを作成します。
画像生成に使うスタイルを設定します。AI Image Generationのボックスの上の方から、画像生成に使うスタイルを選択できます。その右の歯車マークを押すと、スタイルの新規作成や編集が可能です。
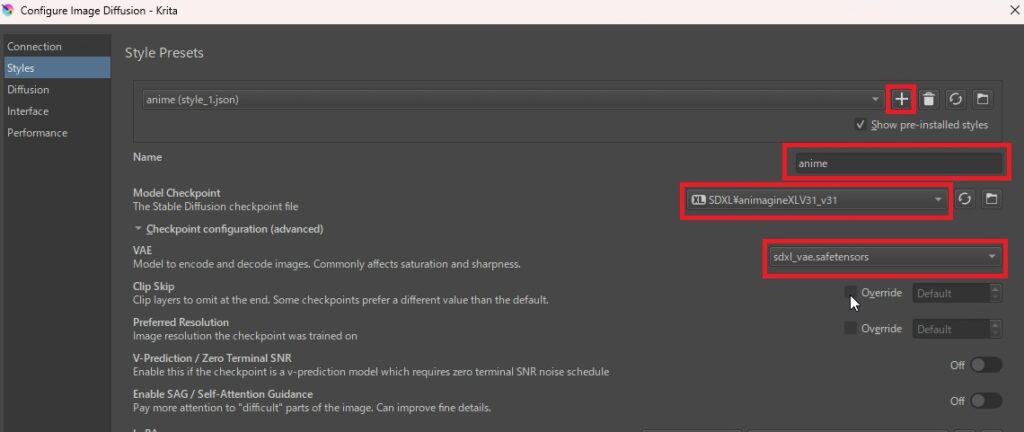
歯車マークを押して「Configure」のStyleの項目を開きます。もし、新規でスタイルを追加したい場合は、「+」マークを押します。「Name」の右には、分かりやすい名前を自由に入れます。今回のスタイルでは、アニメ系を生成するスタイルなので、「anime」と入れています。Model Checkpointでは、画像生成に使うモデル(checkpoint)を選択します。ここでは、先ほどダウンロードしたAnimagineXL3.1を使用します。(ここで選べるようにするには上で説明したように、所定のフォルダに入れておく必要があります。)
また、「Checkpoint configuration (advanced)」の設定欄を広げると中にVAEを設定するところがあります。VAEは画像の仕上げを行ってくれるエンコーダーです。ここでは、SDXL用のVAEを選択します。VAEは使うモデルによって推奨されるVAEが異なるので、モデルの解説をご確認ください、
さらに、下の方の設定項目を確認します。「Style Prompt」には、スタイル共通のプロンプトを入力します。ここでは、AnimagineXLでおすすめのプロンプトを公式ページからコピーして入力しています。
同じく「Negative Prompt」は生成したくない画像の情報を入れます。これも公式のおすすめのものを入れます。
Samplerはデフォルトの「DPM++ 2M」かAnimagineXLの場合は、おすすめの「Euler a」を選択します。Sampler Stepsは30、CFG Scaleは4.0に設定しましたが、このあたりのパラメーターは生成しながら調整が必要です。
Style Prompt
masterpiece, best quality, very aesthetic, absurdres
Negative Prompt
nsfw, lowres, (bad), text, error, fewer, extra, missing, worst quality, jpeg artifacts, low quality, watermark, unfinished, displeasing, oldest, early, chromatic aberration, signature, extra digits, artistic error, username, scan, [abstract]
※公式ページ「https://civitai.com/models/260267/animagine-xl-v31」の情報を転記
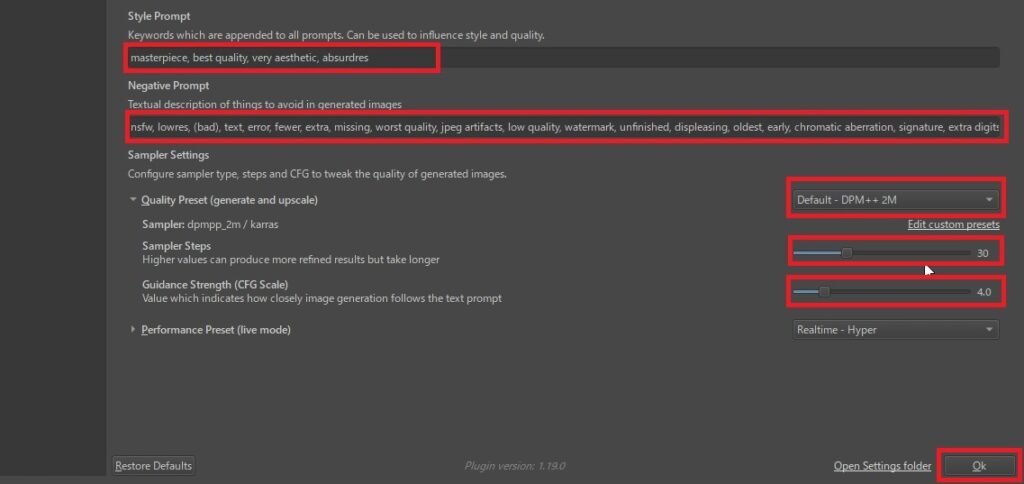
設定したら、OKをクリックして、設定完了です。
Krita AI Diffusionでの画像生成
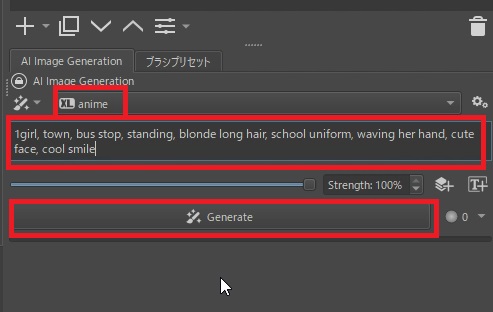
それでは画像を生成してみます。スタイルが選択されていることを確認して、プロンプトを入力します。ここでは、以下のようなプロンプトでバス停で手を振る女の子を生成してみます。
1girl, town, bus stop, standing, blonde long hair, school uniform, waving her hand, cute face, cool smile
「Generate」ボタンをクリックすると画像生成が始まります。生成にはお使いのPCの性能に応じて、少し時間が掛かります。
生成しました。不自然なところもありますが、簡単に思ったような画像が生成できました。
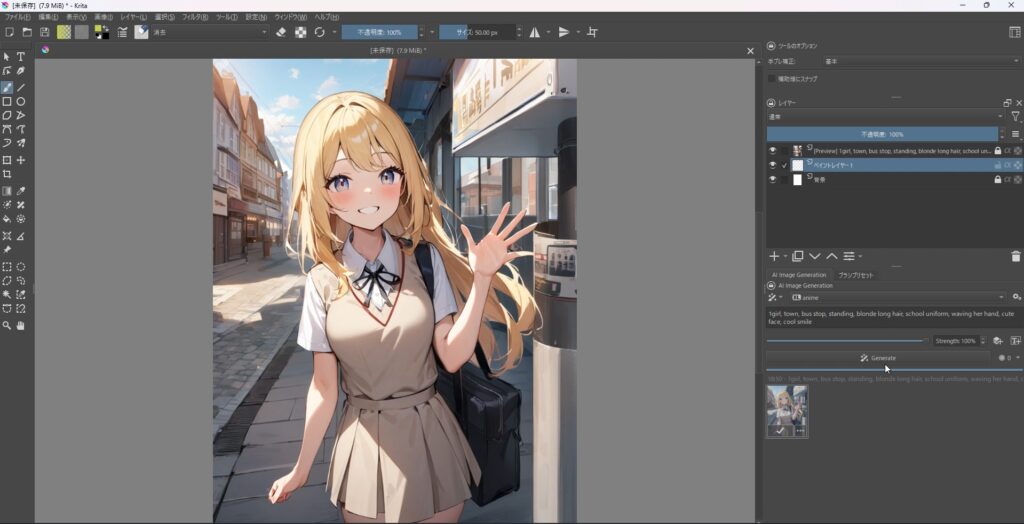
作った画像は、さらに加工することもできます。詳しい使い方は、別の記事や私のYouTubeをご覧ください。
最後に
このブログ「鷹の目週末プログラマー」や私のYouTubeチャンネル「鷹の目週末プログラマーチャンネル」ではStable DiffusionやKrita AI DiffusionなどのAIツールやプログラミング情報を発信しています。是非、ご覧いただき、参考にしていただけたらと思います。
質問や解説してほしいことがあれば、質問フォームからご質問をお待ちしています。

