

Stable Diffusionが公開されて半年余り、画像生成系AIは急速な改良と発展をしてきました。ControlNetは指定された制約条件の下が画像を生成することにより、狙った構図の画像を作り出すことができるツールです。今回、Windowsのローカル環境に環境構築をしていきます。(2023/3/20一部更新しました)
※Stable Diffusionの最新の環境構築手順の記事を作成しました→こちらから
※本記事は2023年2月現在の情報に基づき作成しています。(情報としては古いですがアーカイブとして残しています。)
前準備
Windowsローカルに環境構築をするための、前準備(前提)をまとめます。
・NVIDIA製のGPU(VRAM8GB以上はあったほうが安心)のPC推奨(参考記事:生成系AIを使うためのGPU搭載おすすめパソコン)・GPU計算環境(CUDA環境)のインストール(参考記事1:WindowsへのNVIDIA CUDAのGPU環境構築、参考記事2:WindowsネイティブへのCUDA, PyTorchの環境構築)→必要ないみたいです(2023/3/20追記)
・Python3.10.6のインストール(ここから適合する環境のものをダウンロード。PATHを通すのを忘れないこと。)
・Gitのインストール(ダウンロードはここから)
上記の条件での環境構築を進めていきます。
WebUIのインストール
Pythonの準備ができたらWebUIをインストールします。インストールする場所はストレージの容量に余裕のある場所が好ましいです(Cドライブではモデルなどをダウンロードすると容量不足になってしまう可能性があります)。Windowsの場合、自分がインストールしたいフォルダを右クリックするか、シフトキーを押しながらクリックし、「ターミナルで開く」や「PowerShellウインドウをここで開く」を選択すると、そのフォルダでターミナルかPowerShellなどのコマンド入力画面を簡単に開くことができます。そこで、以下のコマンドを入力すると、ネットからWebUIをダウンロードできます。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitダウンロードしたら、「stable-diffusion-webui」のフォルダの中の、「webui-user.bat」をダブルクリックしたら、WebUIが起動します。初回はセットアップが自動で行われるので、起動に時間が掛かります。
Running on local URL: http://127.0.0.1:7860 To create a public link, set `share=True` in `launch()`.
最後に上のようなメッセージが出たら起動完了です。上のlocal URLにアクセスして、WebUIを起動します。(ブラウザの検索窓に「http://127.0.0.1:7860」を入力して開く)
もし、モデルの追加などWebUIのカスタマイズをしたい場合は、下の記事をご参考ください。
「Stable Diffusion WebUIのカスタム設定」
WebUIへのControlNet拡張機能の導入
開いたwebUIにControlNet拡張起動を導入します。
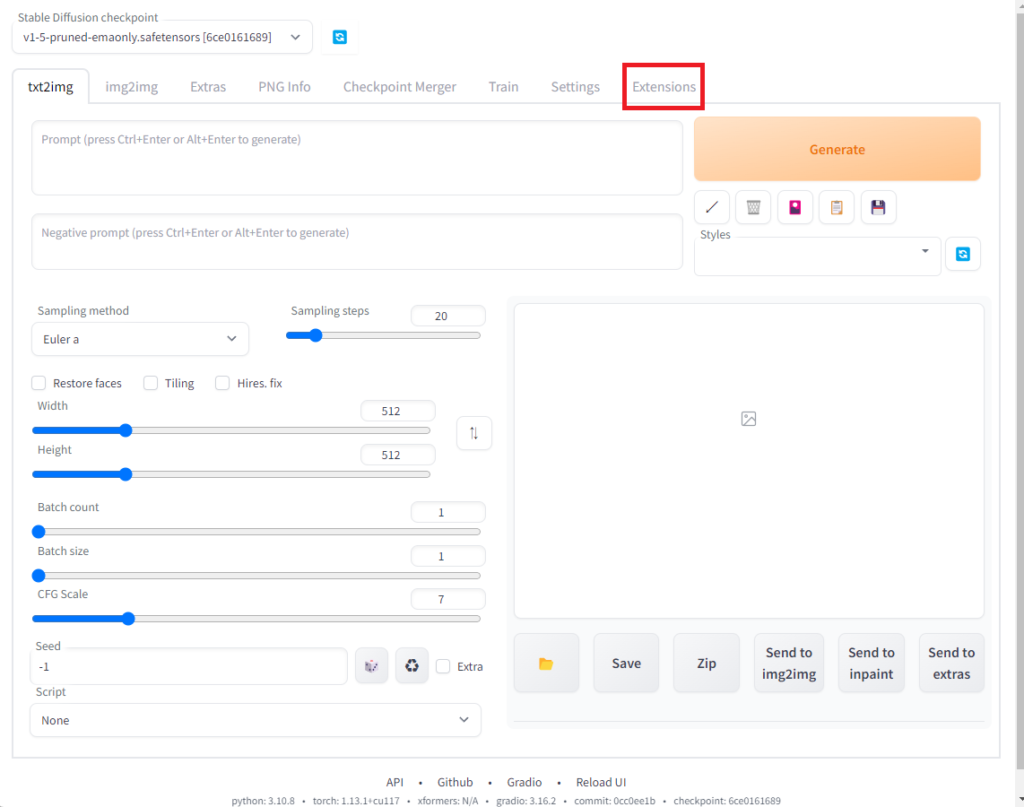
WebUIが開いたら、右上の「Extensions」を開きます。
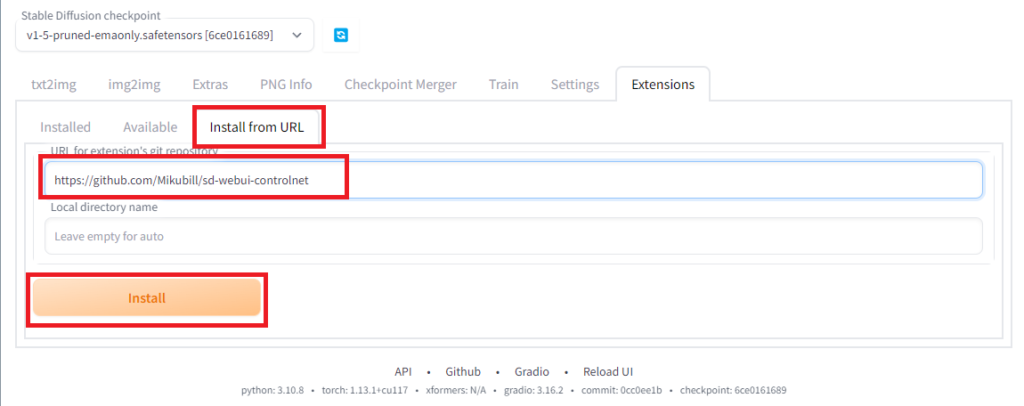
「Install from URL」を開いて、「URL for extension’s git repository」のところに「https://github.com/Mikubill/sd-webui-controlnet」を入力し、「Install」を押します。しばらくすると、extensionsのフォルダにsd-webui-controlnetがインストールされます。それから、一旦、WebUIのタブを消して、ターミナルに戻って、「ctrl-C」でWebUIを停止します。
バッチ ジョブを終了しますか (Y/N)? y次にControlNetのモジュールをダウンロードします。下記のリンクから、.safetensorsのファイルをダウンロードして、extensions>sd-webui-controlnet>modelsのフォルダの中にコピーします。
webui/ControlNet-modules-safetensors
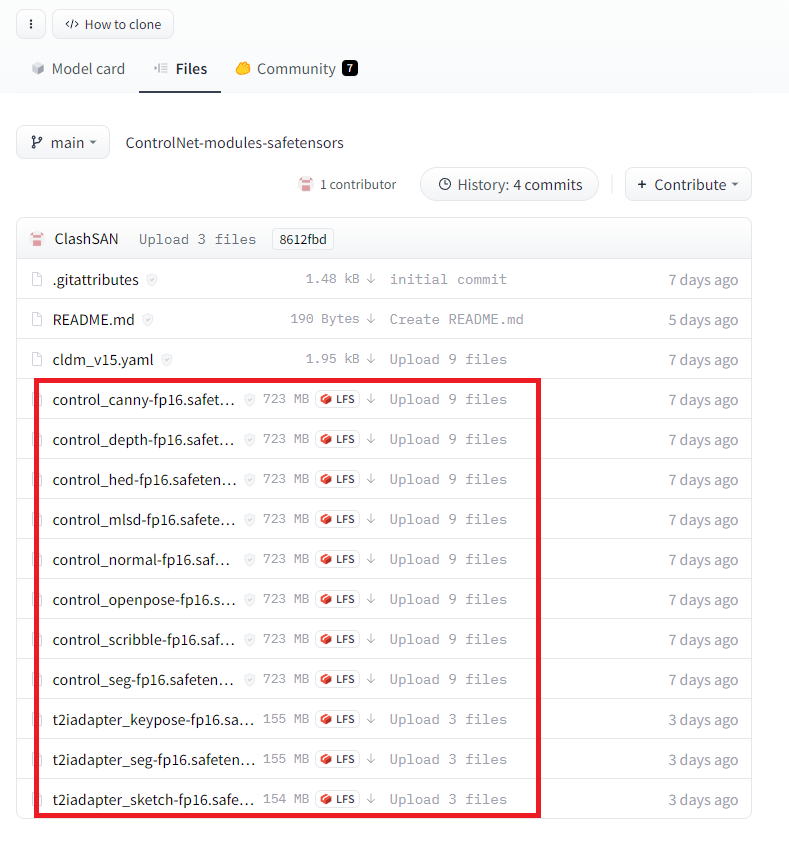
コピーしたら、もう一度WebUIを起動します。
(venv) > ./webui-user.bat下のようにControlNetのタグが追加されていることが分かります。
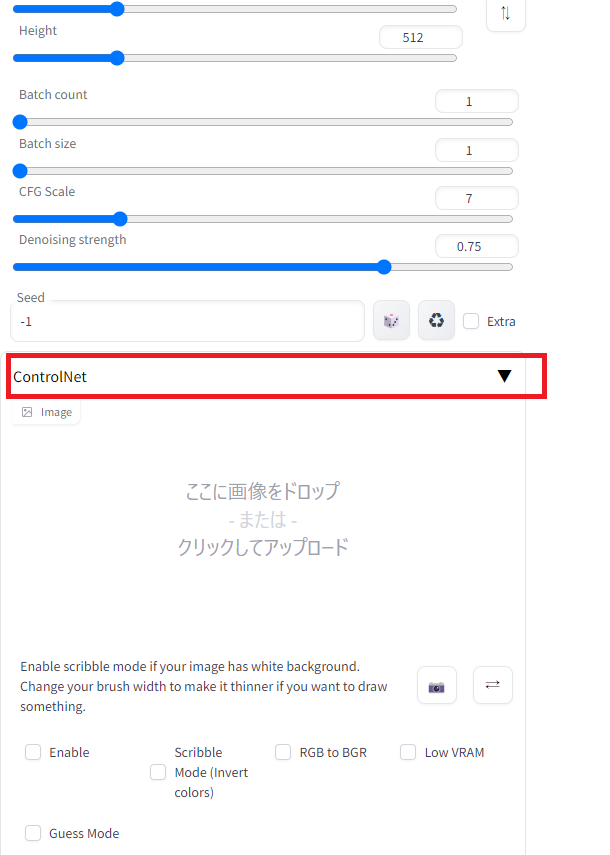
ControlNetの基本的な使用方法
ControlNetの基本的な使用方法は、txt2imgでまずポーズや構図のベースとなる画像を指定し、それに沿って画像を生成することになります。まず、その時、元画像からベース画像への変換方法として、いくつかの種類があります。また、それらのベース画像は前もって自分で準備することもできます。ControlNetを使う場合は、画像をイメージウインドウにドロップし、ControlNetを「Enable」にチェックを入れ、PreprocessorとModelに指定の形式を選択し、また、画像サイズを元の画像のサイズに合わせて調整します。Preprocessorで生成した画像を制約条件を優先して画像を生成します。一方、Preprocessorで制約されない部分については、プロンプトやモデルに依存した画像が生成されます。下に例を示します。
元画像:フリー素材ぱくたそ(www.pakutaso.com)model by 河村友歌さん
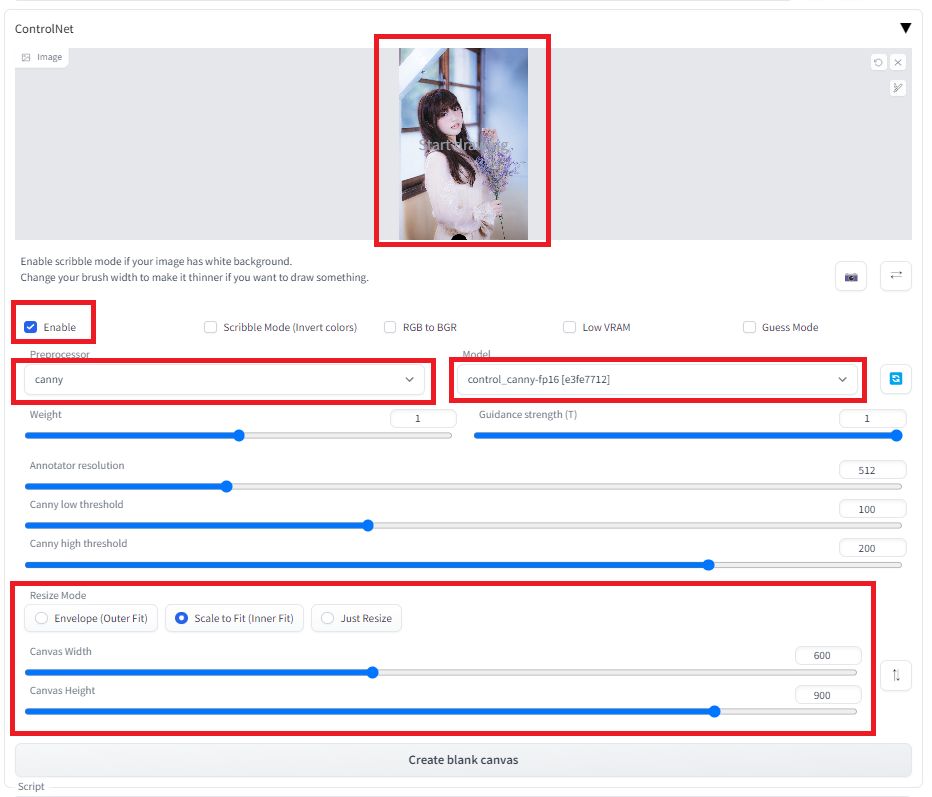

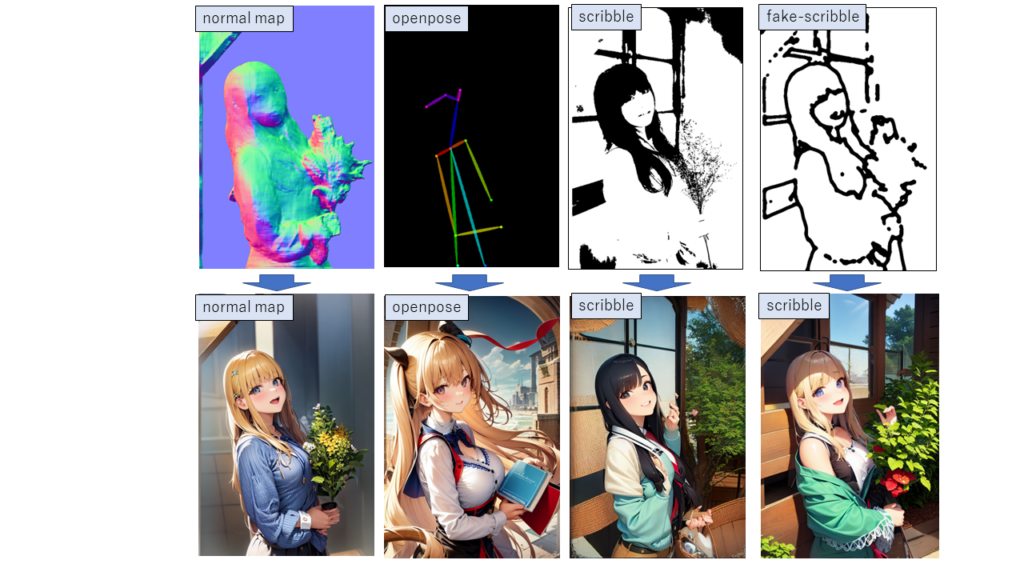

preprosessorの画像は、WebUIの中で変換しなくても、自分で事前に作成したものを用いても構いません。以下に各preprosessorの特徴をまとめます。
canny: キャニーエッジの閾値を調整することで細かい部分まで抽出可能。塗り絵みたいなベースを作るので、原画に割と忠実なものが作りやすいと思う。
depth, depth_leres: 深度コントロールしたベースを抽出する。写真などでは原画の立体感を維持しやすい。
hed: 原画の境界線を割と忠実に残すので、色の変更に便利。
mlsd: ハフ変換で直線情報のみ抽出され、曲線部分の情報は切り捨てられる。上の例でも窓枠の部分だけ切り出され、人物の部分はベースに入っていないため、人物のポーズは反映されていない。
normal_map: 法線マップとして抽出する。バックグラウンドの閾値を設定し、描画対象の物体と拝啓とを切り分けることができる。上記の例でも原画のバックグラウンドを反映せず、人物の部分のみを抽出できている。
openpose: 人物の身体の各部位(顔、腕、足、胴体など)の位置や向きを検出し、それらの部位同士の関係を示す棒人形をベース画像として抽出し、人物のポーズを正確に表すことができる。後述のWebUIの拡張機能でopenposeのエディターを実装し、自分でポージングを作ることもできる。
scribble, fake_scribble: 手書きで領域を指定する手法。画像からpreprocessor画像を作ることもできるが、フリーハンドで書いた線を読み込ませて画像を生成する用途で便利。
pidinet: ニューラルネットワークで領域を分割した前処理。
segmentation: セグメントを色分けした画像から画像を生成する。写真からの変換ではうまくいかないことが多いが、手書きでセグメント分けした画像からの変換で便利。
それぞれのモデルの特徴を説明しました。それぞれの部位に応じて処理方法を適切に選択することにより、意図した画像を精度よく作り出すことができます。
Openpose-EditorのWebUIへの導入
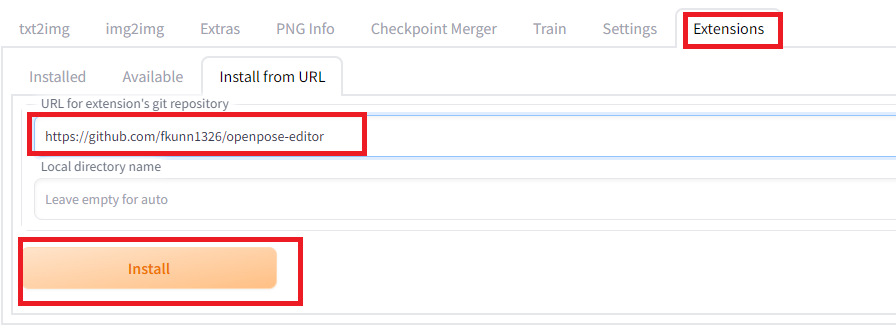
WebUIに拡張機能としてopenposeのエディターを導入できます。WebUIを起動して、「Extensions」のタグから「Install from URL」より「https://github.com/fkunn1326/openpose-editor」を指定してインストールし、WebUIをいったん終了して、立ち上げなおすと使えるようになります。
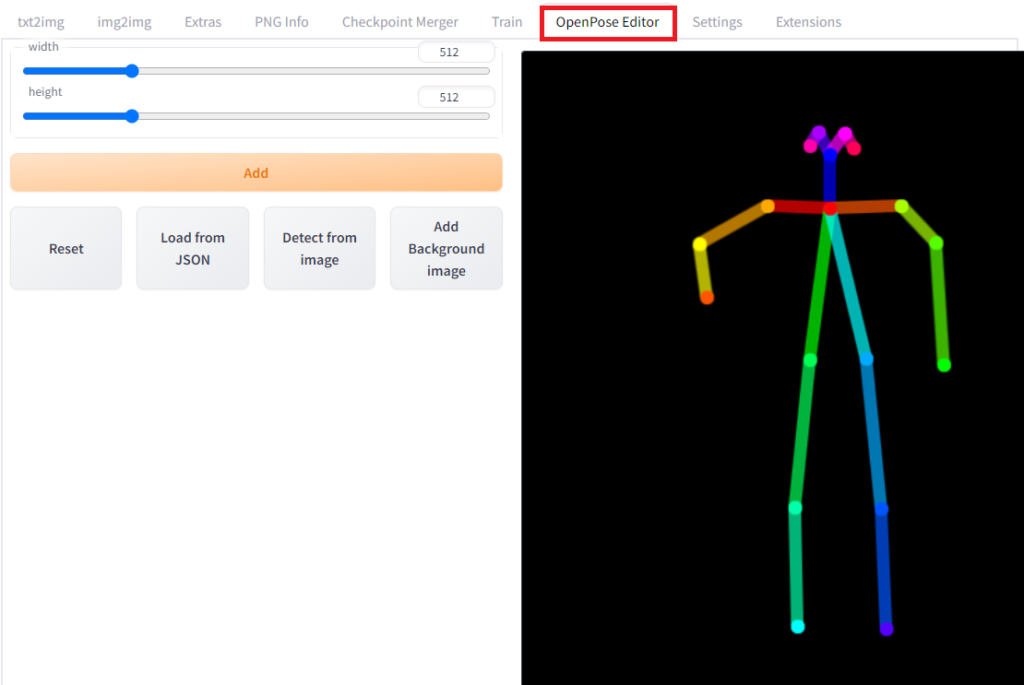
再起動するとOpenPose Editorのタグが追加されます。
最後に
Stable Diffusionなどの生成系AIの発展は本当にものすごいです。オープンソースがこの急速な発展に大きく寄与しているような気がします。他にもいろいろ記事をあげているので、良かったらご覧ください。不明な点があれば、投稿フォームからご質問ください。
【広告】Stable Diffusionをするなら、GPU搭載のPCがおススメです。自作もよいけど、難しい人はBTOのPCもおすすめです。




