

Stable DiffusionのWebUI Automatic1111用に追加学習によりLoRA学習モデルを作成します。追加学習の方法はいろいろありますが、比較的低スペックのPCでも対応可能なLoRAを実施します。手軽に自分の欲しい画像が出せるのは素晴らしいですね。今回は、東北ずん子様を学習データに用いたLoRAの生成をしてみます。
※本記事は2023年3月現在の情報に基づき作成しています。(情報としては古いですがアーカイブとして残しています。)
LoRAとは
LoRA(Low-Rank Adaptation)はStable Diffusionモデルの追加学習をする手法の一つです。追加学習により、自分の欲しいキャラクターや画風の画像を生成することができます。LoRAはDreamBoothでは24GBクラスの大きなVRAMが必要だったのに比べ、比較的低スペックのPCでも対応可能であるという特徴もあり、また、学習に要す時間も短くて済みます。LoRAはトレーニングされるパラメータの数を必要なものだけに減らす手法で、モデルの差分のようなものを作成します。そのため、元のモデルより品質を上げることができませんが、容易に自分の欲しい画像をモデルから取り出すことができるようになります。
LoRAの原著:LoRA: Low-Rank Adaptation of Large Language Models
参考記事→LoRA追加学習で画風を再現
Kohya_ssのGUIのインストール
追加学習に使用するKohya_ssのインストールに先立って、Python3.10とvenv環境を準備します。(参考:Windowsで複数のバージョンのPythonをインストールする)
準備ができたら、Kohya_ssが公開されているGithubサイトのREADMEを参考にインストールします。
> git clone https://github.com/bmaltais/kohya_ss.git
> cd kohya_ss
> py -3.10 -m venv venv
> .\venv\Scripts\Activate.ps1
(venv) > python -m pip install -U pip setuptools
(venv) > pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
(venv) > pip install --upgrade -r requirements.txt
(venv) > pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
(venv) > cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
(venv) > cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
(venv) > cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
引き続き、accelerateの設定を行います。下のように質問に答えて、accelerateでGPUを使った学習計算を高速化します。質問への答え方は、下のような操作で回答します。
In which compute environment are you running?→Enterキー
Which type of machine are you using?→Enterキー
[yes/NO]の質問(3つ):→NOを入力してEnterキー
[all]:の質問→allを入力してEnterキー
Do you wish to use FP16 or BF16 (mixed precision)?→1を押してからEnterキー
設定後、テストによって、設定ができていることを確認します。入力を間違えて設定が失敗した場合はもう一度実施してください。
(venv) > accelerate config
------------------------------------------------------------------------------------------------------------------------
In which compute environment are you running?
This machine
------------------------------------------------------------------------------------------------------------------------
Which type of machine are you using?
No distributed training
Do you want to run your training on CPU only (even if a GPU is available)? [yes/NO]:NO
Do you wish to optimize your script with torch dynamo?[yes/NO]:NO
Do you want to use DeepSpeed? [yes/NO]: NO
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:all
------------------------------------------------------------------------------------------------------------------------
Do you wish to use FP16 or BF16 (mixed precision)?
fp16
accelerate configuration saved at C:\Users\user-name/.cache\huggingface\accelerate\default_config.yaml
(venv) > accelerate test
Test is a success! You are ready for your distributed training!続いて、NVIDIA 30X0や40X0を使っている場合は、cuDNNのライブラリを使えるように設定します。ここから、ZIPファイルを解凍し、中身の「cudnn_windows」のフォルダを「kohya_ss」の直下にコピーします。そのうえで、以下のコマンドでインストールします。
(venv) > python .\tools\cudann_1.8_install.py
[ ] xformers version 0.0.14.dev0 installed.
[+] bitsandbytes version 0.35.0 installed.
[ ] diffusers version 0.10.2 installed.
[+] transformers version 4.26.0 installed.
[+] torch version 1.12.1+cu116 installed.
[+] torchvision version 0.13.1+cu116 installed.
Checking for CUDNN files in D:\Users\python_train\kohya_ss\venv\Lib\site-packages\torch\lib
Copied CUDNN 8.6 files to destination学習用画像の準備
学習用の画像を準備します。準備する画像としては、例えば人であればその人物が中心となっている画像で、編集でその人物以外の部分は削除しておきます。枚数としてはおおむね20枚程度あればよいとのことです。今回、『東北ずんこofficialページ』から東北ずん子様の画像をお借りして、追加学習モデルを作っていくことにします。

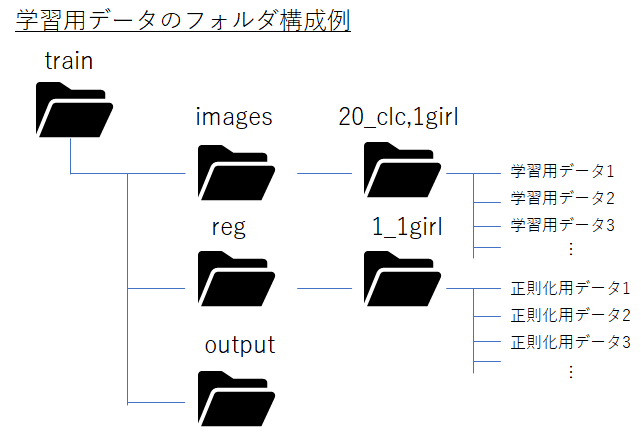
今回は上記のHPからずん子様54枚をダウンロードして使います。画像は透過背景のpngファイルでがぞ数も非常に大きかったので、jpegに変換して、透過背景をキャンセルし上で画像サイズを縦1000ピクセル程度にリサイズしたものを学習データとして使います。今回、画像を呼び出すプロンプトとして、意味のない3文字のアルファベット「clc」を設定します。これは意味がない単語なら何でもよいです。今回はずん子様は有名なので、「zunko」とつけるだけで、ずん子様が召喚される可能性が高いので、そういう単語は避けます。また、ずん子様の概念は「1girl」なので、その単語合わせて、下のようにtrainフォルダの下にimagesフォルダを作成し、その中に使った「20_clc,1girl」というフォルダを作成し、その中に学習用データを入れます。タグについては、別途txtデータでフォルダ内に置くこともできますが、今回はフォルダ名にキャラ名を入れる簡易的な方法を使っています。
先頭の「20_」は繰り返し学習回数を示します。学習時間は、繰り返し回数×学習する画像数×エポック数で決まります。そこは持っている画像の枚数や学習のしやすさに応じて、適当に設定します。
また、正則化画像を準備します。別途WebUIで自分の使いたいモデルで、「1girl」をプロンプトにして画像を200枚程度準備しました。trainフォルダの下に「reg」というフォルダを作成し、その中に「1_1girl」というフォルダを作成し、その中にそれらの画像を入れます。正則化により、1girlの概念の凡化性能を維持することができます。
また、モデル出力用にoutputフォルダも準備しておきます。
GUIの起動と画像の学習(LoRA)
学習用データが準備できたら、kohya_ssを使って、学習させてみます。kohya_ssのフォルダに移動して、gui.batをクリックすることで、GUIを起動します。起動後、指定されたローカルURL(下記であれば、http://127.0.0.1:7860)を開きます。
(venv) > ./gui.bat --listen 127.0.0.1 --server_port 7860 --inbrowser --share
Validating that requirements are satisfied.
All requirements satisfied.
Load CSS...
Running on local URL: http://127.0.0.1:7860間違えないようにDreamboothのタグではなく、2つ目の「Dreambooth LoRA」のタグを開きます。その中の「Source model」を選択し、そのページで、ベースとなるモデルを指定します。今回、Stable Diffusion1.5系の学習済みモデルanthing-v4.5をベースモデルとして用いますので、モデルのローカル保存先のPATHを「Pretrained model name or path」で指定します。「Model Quick Pick」は「custom」、Save trained model asには「safetensors」を指定します。

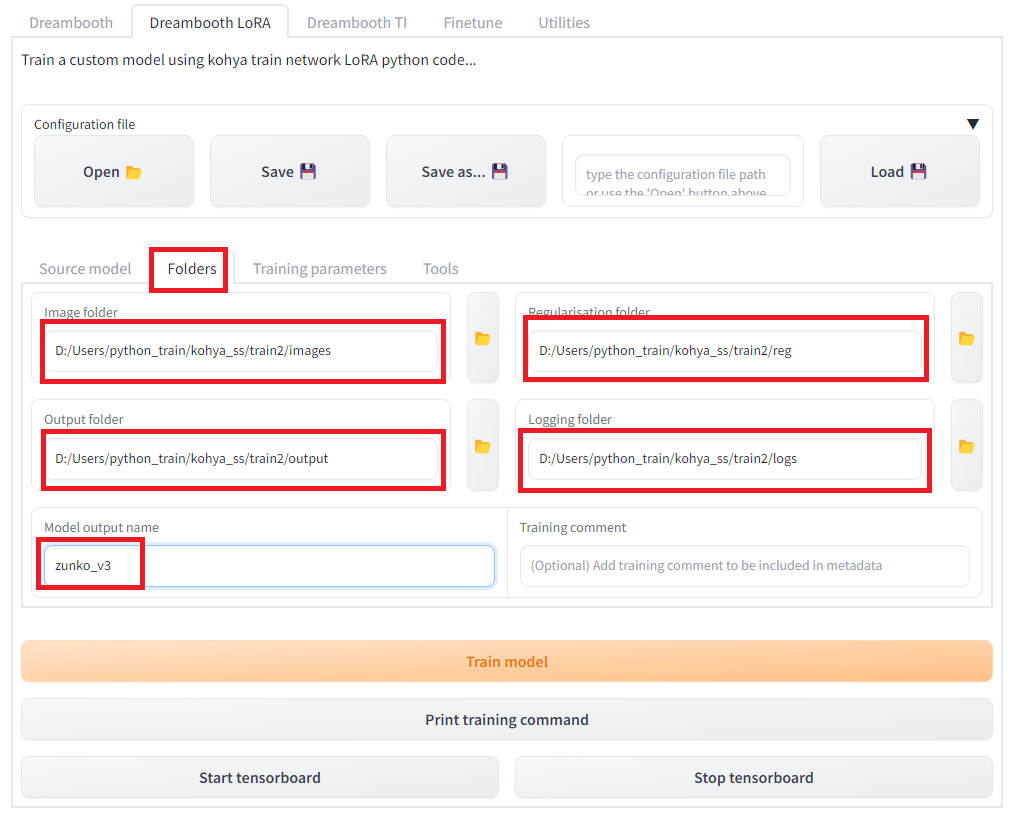
続いて画像フォルダとアウトプットフォルダを指定し、生成するモデルのアウトプット名を指定します。「Dreambooth LoRA」タグの「Folders」を選択します。画像フォルダ(Image folder)としては、画像が入っているフォルダではなく、その親フォルダの「images」を指定します。「Regularisation folder」は正規化用画像の入っているフォルダの親フォルダの「reg」を指定します。「Model output name」には作成するモデル名を入力します。今回は”zunko_v3″としました。「Output folder」にはモデルが出力する場所を指定します。また、オプションでログも出力できます。
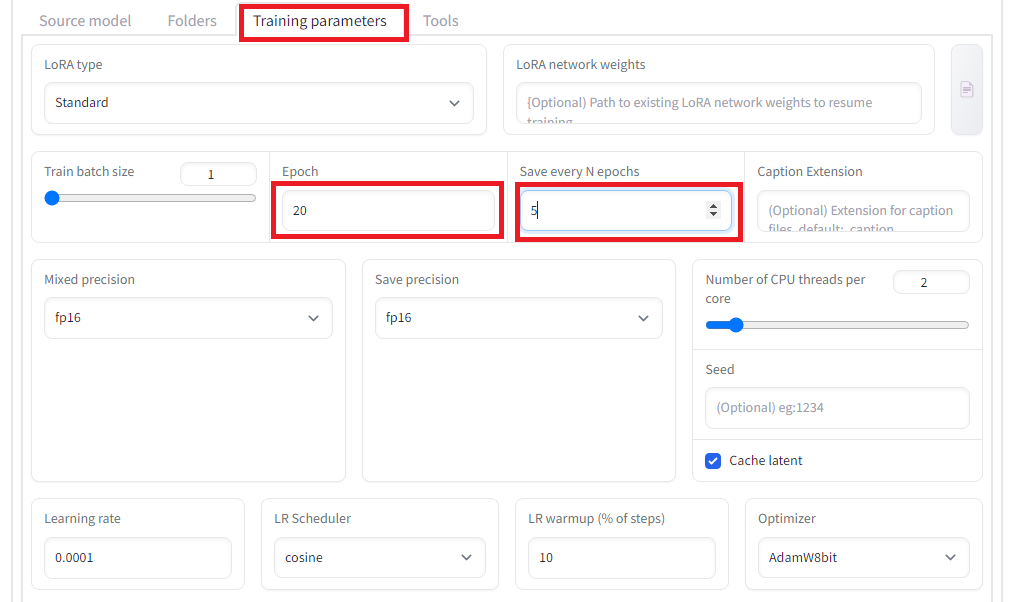
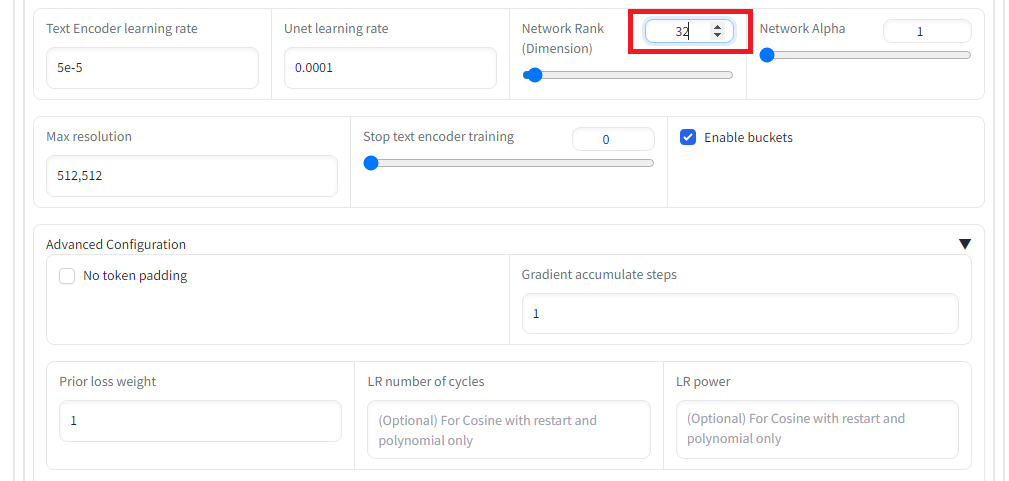
「Training parameters」タグで学習パラメータを設定します。今回はエポック数を20にするのと、5エポックずつ保存のと、Network rank(次元数)を32に設定し、また、memory efficient attentionにチェックを入れています。その他、設定は以下の通りです。設定出来たら、「Train model」ボタンを押して学習を開始します。
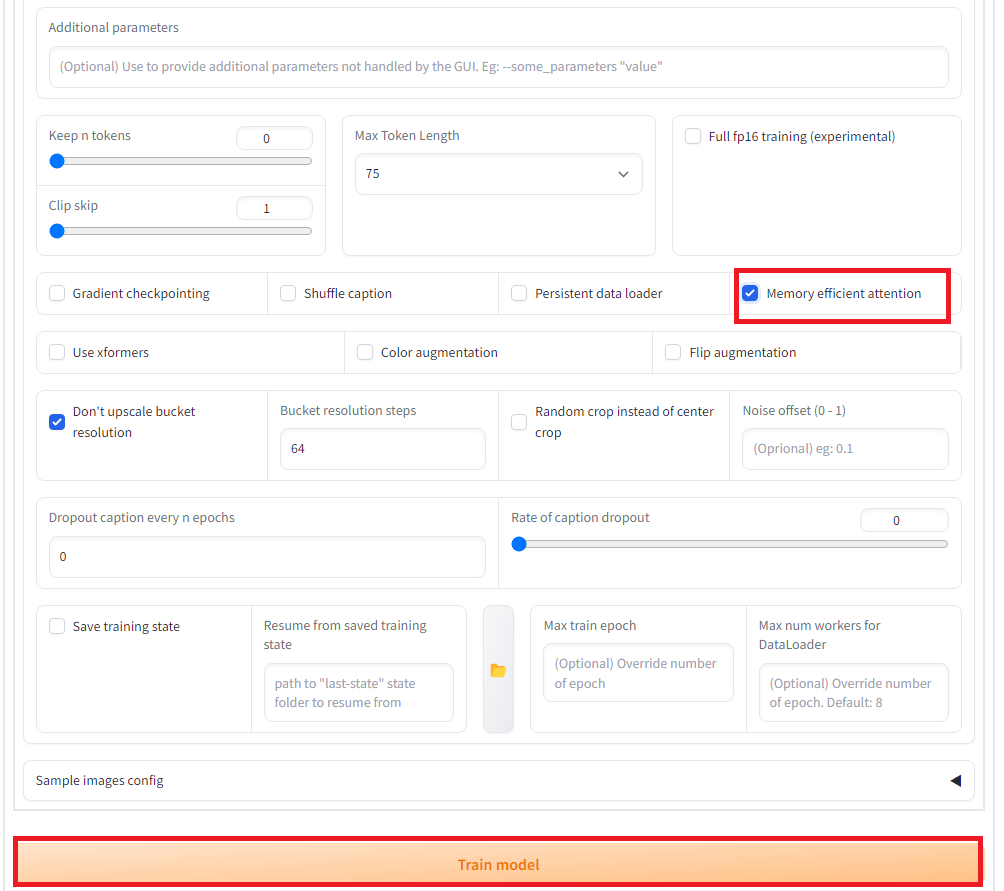
これにより、Outputのフォルダ内に、学習データの入ったLoRaのsafetensorsファイルが生成されます。
LoRA追加学習モデルを使った画像生成
LoRAで追加学習したデータを使って画像生成をしてみます。Stable DiffusionのWebUI AUTOMATIC1111ではLoRAモデルを標準でサポートしています。作ったLoRAモデルは「\stable-diffusion-webui\models\Lora」のフォルダの中に入れます。
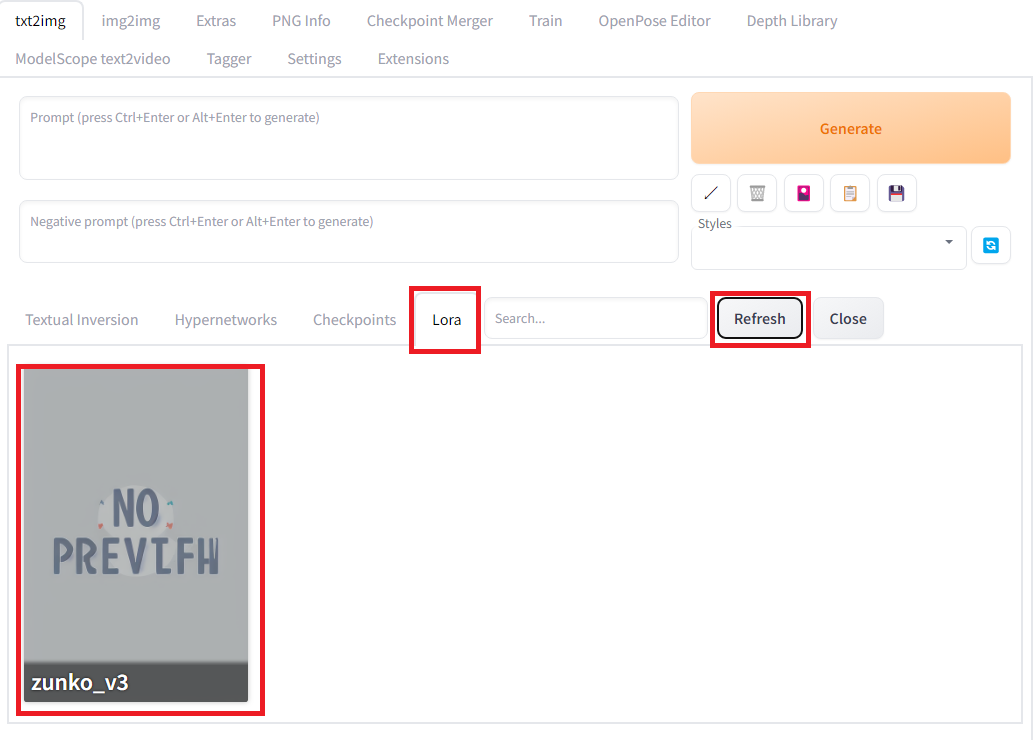
Automatic1111を起動して、Generateボタンの下の赤いアイコンをクリックし、LoRAのタグを選ぶと登録されているLoRAモデルを確認できます。
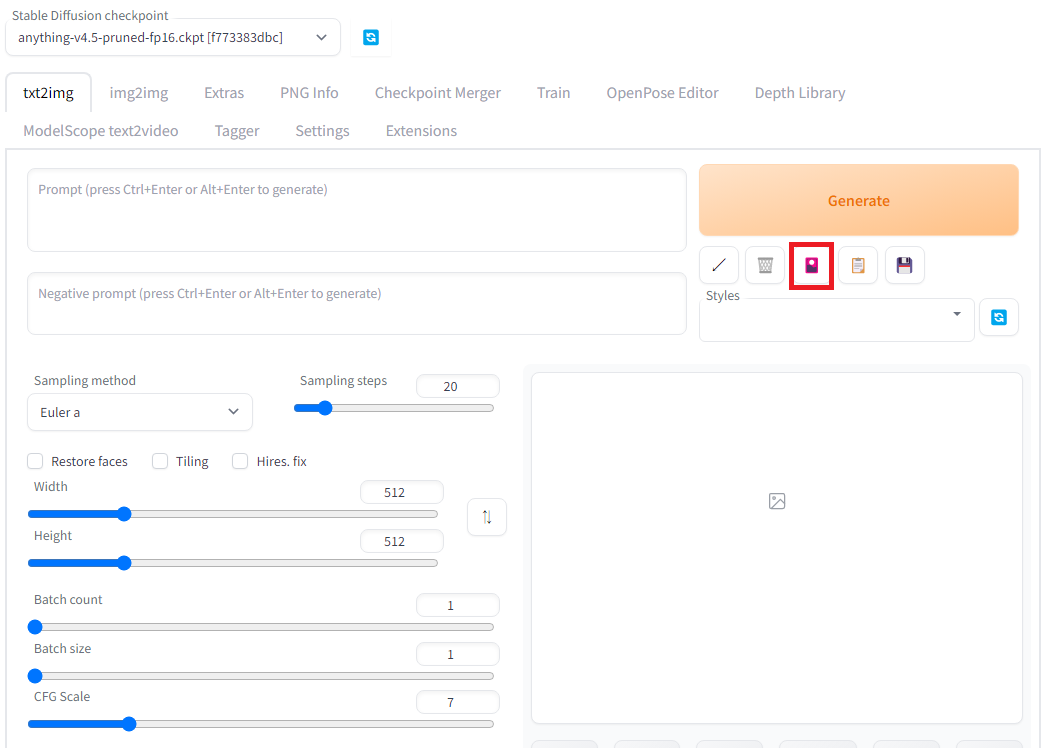
もし、モデルが見つからないときはRefreshボタンを押してみてください。先ほど作ったLoraのカードをクリックすると、プロンプトに<lora:zunko_v3:1>と表示れます。<lora:zunko_v3:1>のプロンプトでloraのzunko_v3というモデルを強度1で反映させることができるようになります。強度については、強弱は調整してください。大きくするほどLoRAモデルの影響が大きくなります。1以上にすると画像が崩れてしまうことがあるので、1以下の適当な数字をいれます。また、プロンプトには生成の時に使ったclc, 1girlも入れます。
例えば、以下のようなプロンプトを入れます。(緑色のヘアバンドについてはうまく学習ができなったようなので、プラス要素として加えています。)
clc, 1girl, masterpiece, best quality, outdoors, streets, green headband, kimono
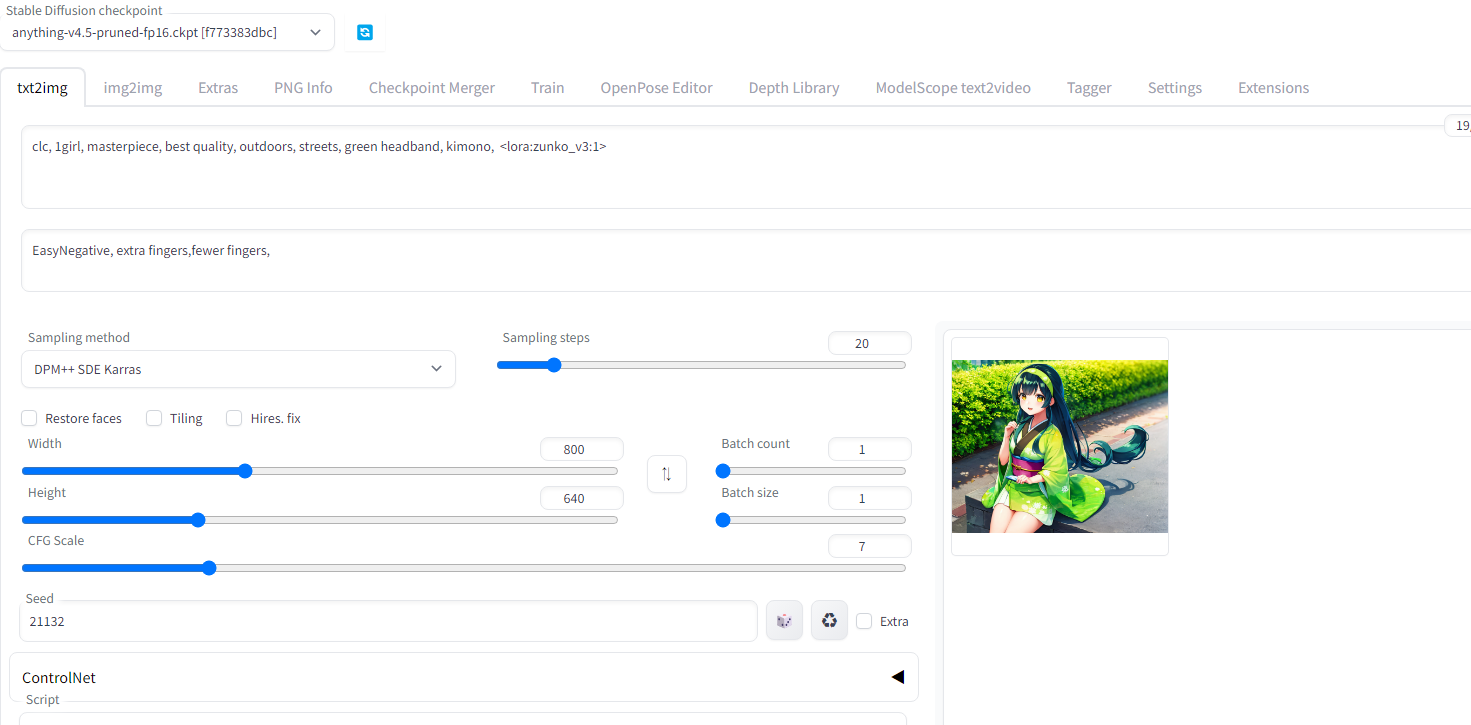
ずん子様風の美少女が生成できました。いろいろプロンプトを工夫するとかわいらしずん子様が生成します。

今回はKohya-ssを使って、追加学習でLoRAモデルを作って、キャラクターをしてした画像を生成する方法をまとめました。LoRAの学習方法については、いろいろ工夫された新しい方法がどんどん開発されていて目が離せません。今後も、いろいろな方法を見ていきたいと思います。

