

LoRAによりStable Diffusionのモデルに画風の追加学習してみます。あらかじめターゲットとする画風の画像での追加学習により、Stable Diffusionで好みの画風の画像を生成できるようになります。今回もKahya_ssのGUIを用いて追加学習をします。
参考記事→LoRA追加学習で好きなキャラ召喚:Stable Diffusion WebUIでの画像生成
※本記事は2023年4月現在の情報に基づき作成しています。(情報としては古いですがアーカイブとして残しています。)
Kohya_ssのGUIのインストール
追加学習に使用するKohya_ssのインストールに先立って、Python3.10とvenv環境を準備します。(参考:Windowsで複数のバージョンのPythonをインストールする)
準備ができたら、Kohya_ssが公開されているGithubサイトのREADMEを参考にインストールします。
> git clone https://github.com/bmaltais/kohya_ss.git
> cd kohya_ss
> py -3.10 -m venv venv
> .\venv\Scripts\Activate.ps1
(venv) > python -m pip install -U pip setuptools
(venv) > pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
(venv) > pip install --use-pep517 --upgrade -r requirements.txt
(venv) > pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
(venv) > cp .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
(venv) > cp .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
(venv) > cp .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py引き続き、accelerateの設定を行います。下のように質問に答えて、accelerateでGPUを使った学習計算を高速化します。設定後、テストによって、設定ができていることを確認します。
(venv) > accelerate config
------------------------------------------------------------------------------------------------------------------------
In which compute environment are you running?
This machine
------------------------------------------------------------------------------------------------------------------------
Which type of machine are you using?
No distributed training
Do you want to run your training on CPU only (even if a GPU is available)? [yes/NO]:NO
Do you wish to optimize your script with torch dynamo?[yes/NO]:NO
Do you want to use DeepSpeed? [yes/NO]: NO
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:all
------------------------------------------------------------------------------------------------------------------------
Do you wish to use FP16 or BF16 (mixed precision)?
fp16
accelerate configuration saved at C:\Users\user-name/.cache\huggingface\accelerate\default_config.yaml
(venv) > accelerate test
Test is a success! You are ready for your distributed training!続いて、NVIDIA 30X0や40X0を使っている場合は、cuDNNのライブラリを使えるように設定します。ここから、ZIPファイルを解凍し、中身の「cudnn_windows」のフォルダを「kohya_ss」の直下にコピーします。そのうえで、以下のコマンドでインストールします。
(venv) > python .\tools\cudann_1.8_install.py
[ ] xformers version 0.0.14.dev0 installed.
[+] bitsandbytes version 0.35.0 installed.
[ ] diffusers version 0.10.2 installed.
[+] transformers version 4.26.0 installed.
[+] torch version 1.12.1+cu116 installed.
[+] torchvision version 0.13.1+cu116 installed.
Checking for CUDNN files in D:\Users\python_train\kohya_ss\venv\Lib\site-packages\torch\lib
Copied CUDNN 8.6 files to destination学習用データの準備
今回は国立国会図書館の公開している「NDLイメージバンク」から明治時代の画家、山本昇雲の美人風俗画「いますがた」を学習データとして用いて、山本昇雲の美人風俗画の画風をStable Diffusionのモデルに追加学習してみます。このNDLイメージバンクでは著作権の満了した画像を公開しています。

上記のリンクから画像をダウンロードしてローカルに保存します。ここでは48枚の画像をダウンロードしました。
今回、画像を呼び出すプロンプトとして、意味のない3文字のアルファベット「xlx」を設定します。これは意味がない単語なら何でもよいです。「kohya_ss」のフォルダ内に「\Train\images\20_xlx」というフォルダを作成してその中に画像を入れます。画像を入れるフォルダは「20_xlx」というように「数字_プロンプト」の形式で作成します。先頭の「20_」は繰り返し学習回数を示します。今回は画像からの学習を20回行う設定にします。(実際の学習回数はこの数字にkahya_ssのGUI内で設定されるエポック数を掛けたものになります。)
続いて、学習用データの説明をするテキストをタガーで生成します。様々なタガーがありますが、ここではWebUIの拡張機能であるstable-diffusion-webui-wd14-taggerを用います。このタガーはWD1.4をベースとするタグ付けツールです。Tagger拡張機能をAutomatic1111にインストールには、「Extensions」タグから「Install from URL」から「URL for extension’s git repository」にgithubの配布リポジトリ「https://github.com/toriato/stable-diffusion-webui-wd14-tagger」を指定し、「Install」ボタンを押してインストールします。(参考:WebUIのTagger拡張機能で画像のタグ付け)
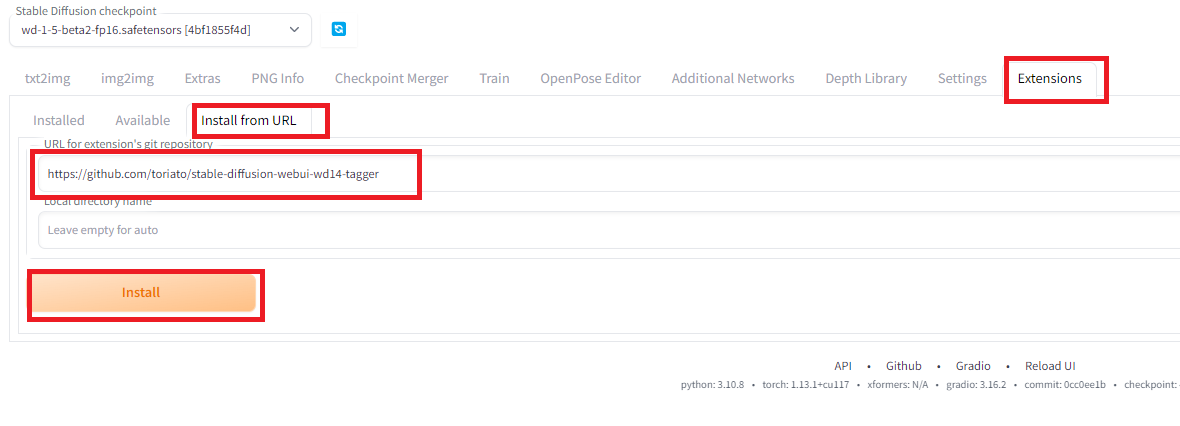
インストールしたら、「Installed」のところから追加されていることを確認し、「Aply and restart UI」でWebUIを再起動します。
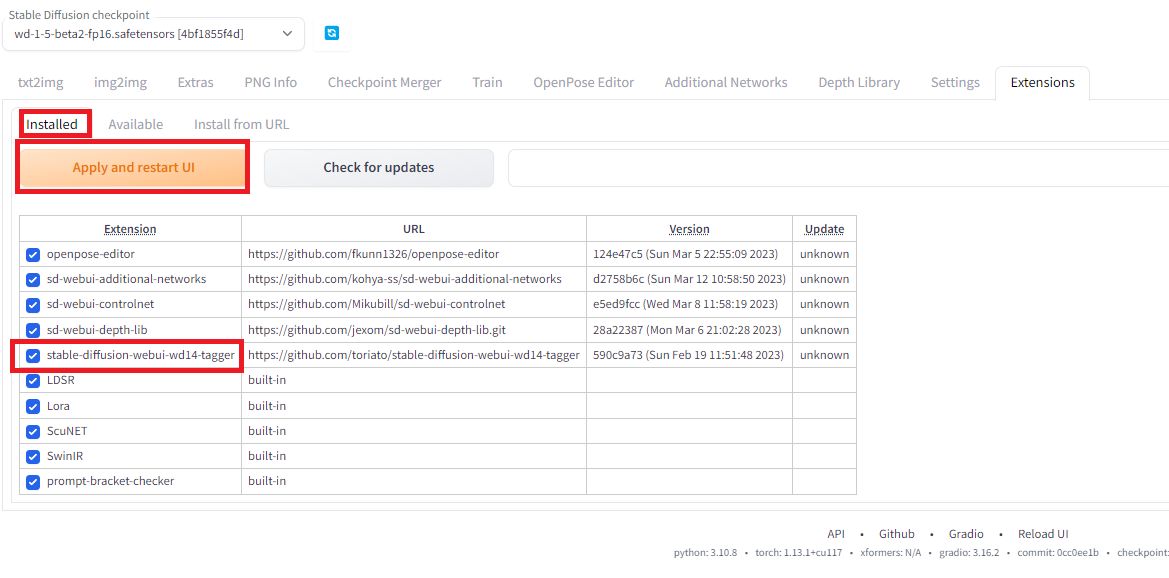
新しく「Tagger」のメニューが追加されていると思います。うまく更新が反映されない場合、ブラウザを更新します。
「Tagger」の「Batch from directory」を選択して一度にすべての画像のタグを生成したいと思います。「Input directory」に画像が保存をしているフォルダを選択し、「Output directory」は生成するテキストファイルを画像と同じ場所に置きたいの空白にします。「Threshold」は生成するプロンプトが5~15個くらいになるように0.5に設定します。「Additional tags」には呼び出し用のプロンプト「xlx」を入力します。ちゃんとプロンプトが生成されるかは、あらかじめSingle processで確認してみるのがよいでしょう。(Single processに画像が貼ってあるとBatch from directoryでテキスト生成ができないのでご注意ください。)
設定が終わったら、「Interrogate」ボタンで画像それぞれに対応するタグがテキストで生成されます。
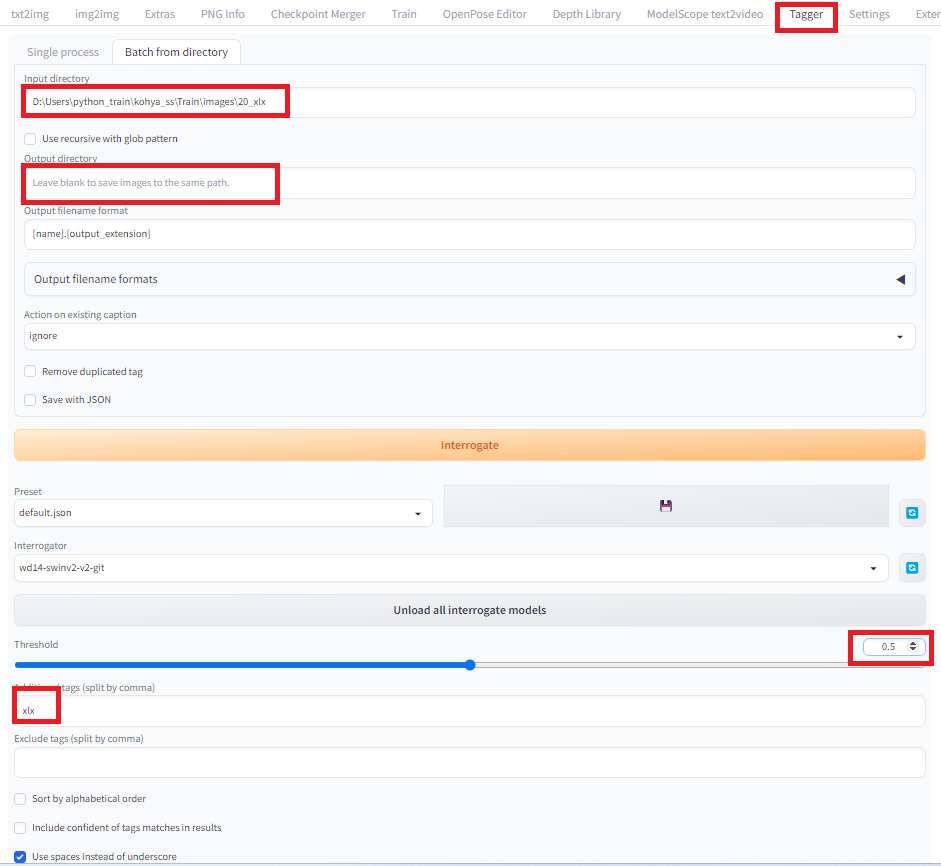
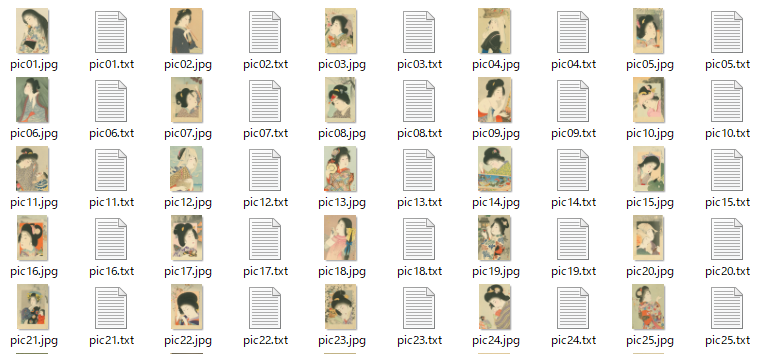
生成されたテキストを開いて、ちゃんとプロンプトが生成されていることを確認します。
生成されたテキストの例: xlx, 1girl, solo, japanese clothes, kimono, long hair, flower, black hair, animal print, sash, obi, holding, traditional media, holding flower
GUIの起動と画像の学習(LoRA)
学習用データが準備できたら、kohya_ssを使って、学習させてみます。kohya_ssのフォルダに移動して、gui.batをクリックすることで、GUIを起動します。起動後、指定されたローカルURL(下記であれば、http://127.0.0.1:7860)を開きます。
(venv) > ./gui.bat --listen 127.0.0.1 --server_port 7860 --inbrowser --share
Validating that requirements are satisfied.
All requirements satisfied.
Load CSS...
Running on local URL: http://127.0.0.1:7860間違えないようにDreamboothのタグではなく、2つ目の「Dreambooth LoRA」のタグを開きます。その中の「Source model」を選択し、そのページで、ベースとなるモデルを指定します。今回、Stable Diffusion1.5系の学習済みモデルanthing-v4.5をベースモデルとして用いますので、モデルのローカル保存先のPATHを「Pretrained model name or path」で指定します。「Model Quick Pick」は「custom」、Save trained model asには「safetensors」を指定します。
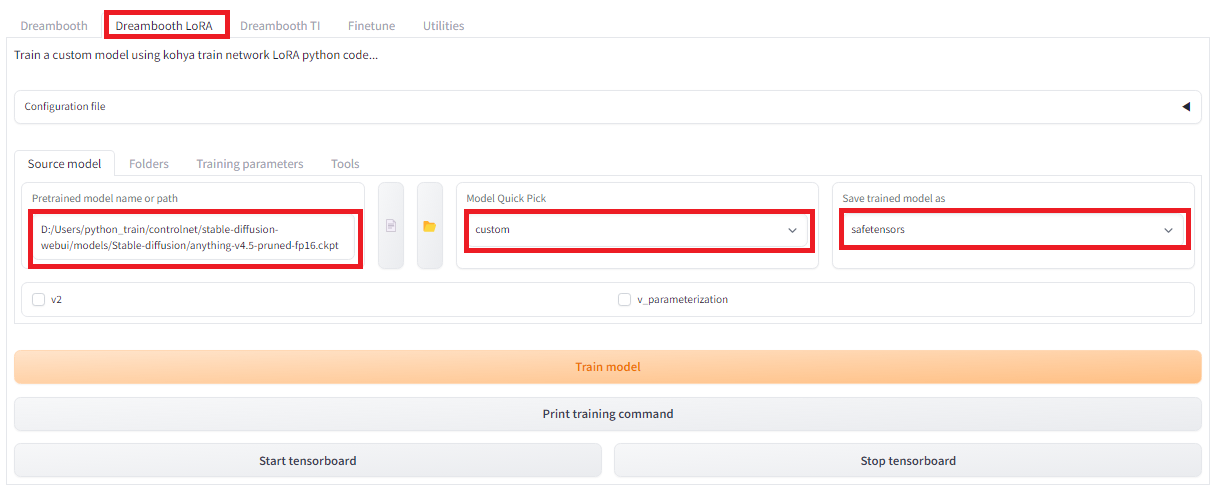
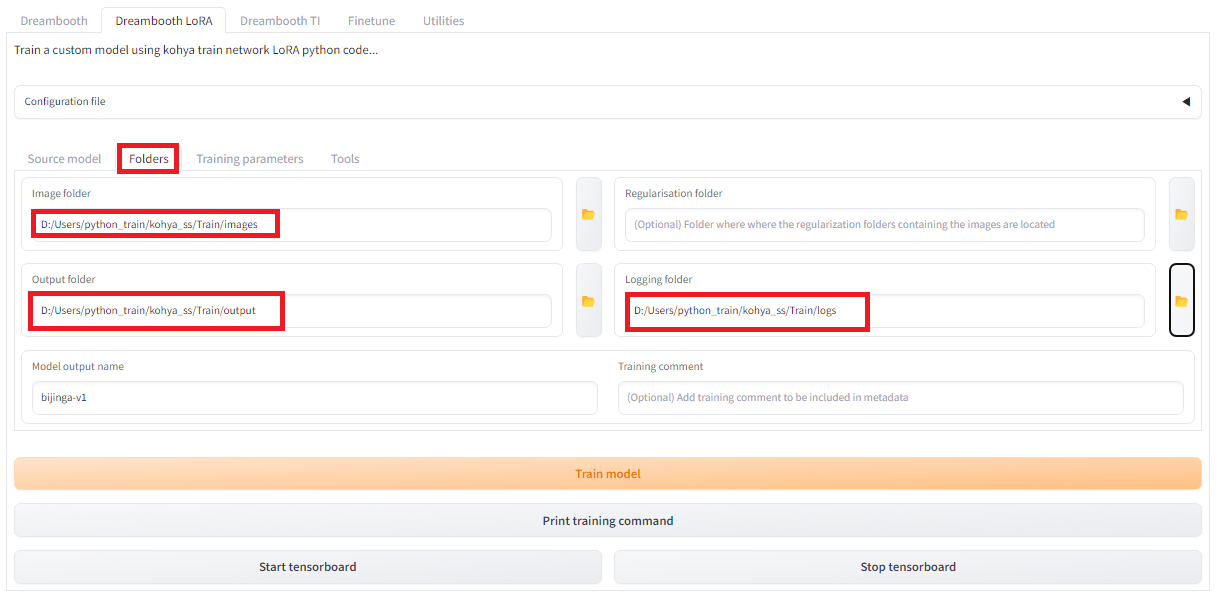
続いて画像フォルダとアウトプットフォルダを指定し、生成するモデルのアウトプット名を指定します。「Dreambooth LoRA」タグの「Folders」を選択します。画像フォルダとしては、画像が入っているフォルダではなく、その親フォルダの「images」を指定します。「Model output name」には作成するモデル名を入力します。今回は”bijinga_v1″としました。「Output folder」にはモデルが出力する場所を指定します。また、オプションでログも出力できます。今回は画風の学習なので、正規化用画像は用いませんので、「Regularisation folder」は何も入れません。
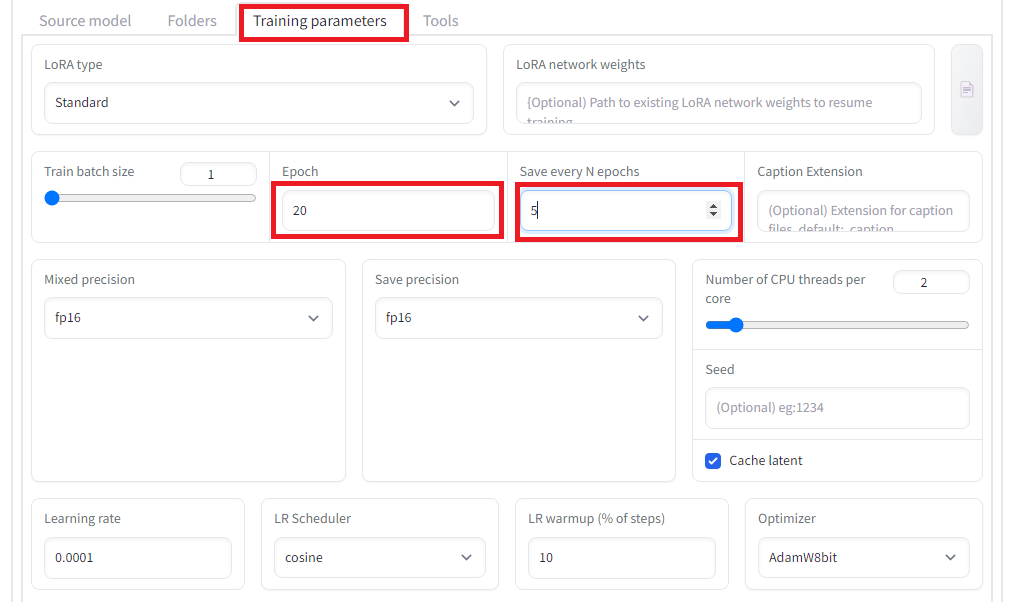
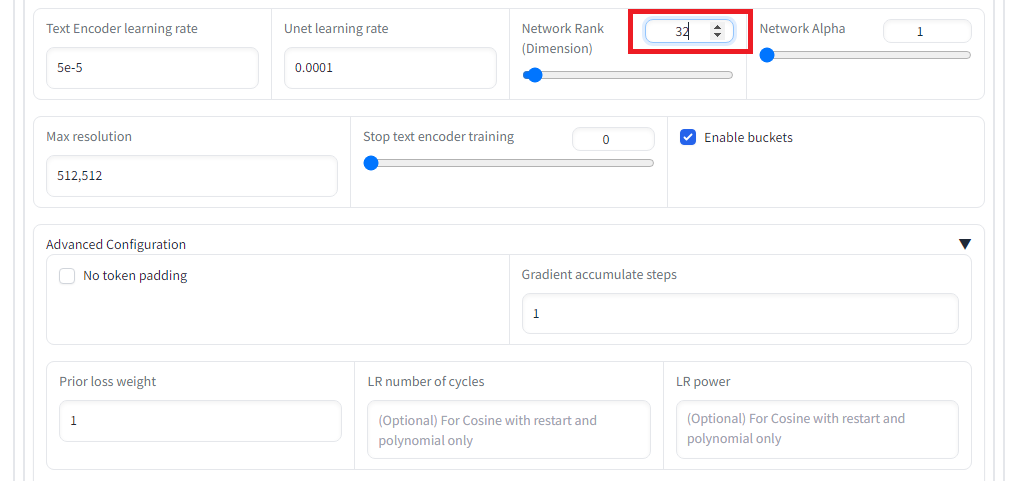
「Training parameters」タグで学習パラメータを設定します。今回はエポック数を20にするのと、5エポックずつ保存のと、Network rank(次元数)を32に設定し、また、memory efficient attentionにチェックを入れています。その他、設定は以下の通りです。設定出来たら、「Train model」ボタンを押して学習を開始します。
これにより、Outputのフォルダ内に、学習データの入ったLoRaのsafetensorsファイルが生成されます。
LoRA追加学習モデルを使った画像生成
LoRAで追加学習したデータを使って画像生成をしてみます。Stable DiffusionのWebUI AUTOMATIC1111ではLoRAモデルを標準でサポートしています。作ったLoRAモデルは「\stable-diffusion-webui\models\Lora」のフォルダの中に入れます。
Automatic1111を起動して、Generateボタンの下の赤いアイコンをクリックし、LoRAのタグを選ぶと登録されているLoRAモデルを確認できます。もし、モデルが見つからないときはRefreshボタンを押してみてください。LoRAモデルのパネルをクリックすると、<lora:bijinga-v1:1.0>のプロンプトが生成されます。bijinga-v1は私が先ほど作ったLoRAモデルです。<lora:bijinga-v1:1.0>のプロンプトはloraのbijinga-v1というモデルを強度1.0で適用させるという意味になります。強度のところは1以下の適当な数字をいれます。また、プロンプトにはモデル生成の時に使ったxlx,1girlも入れます。
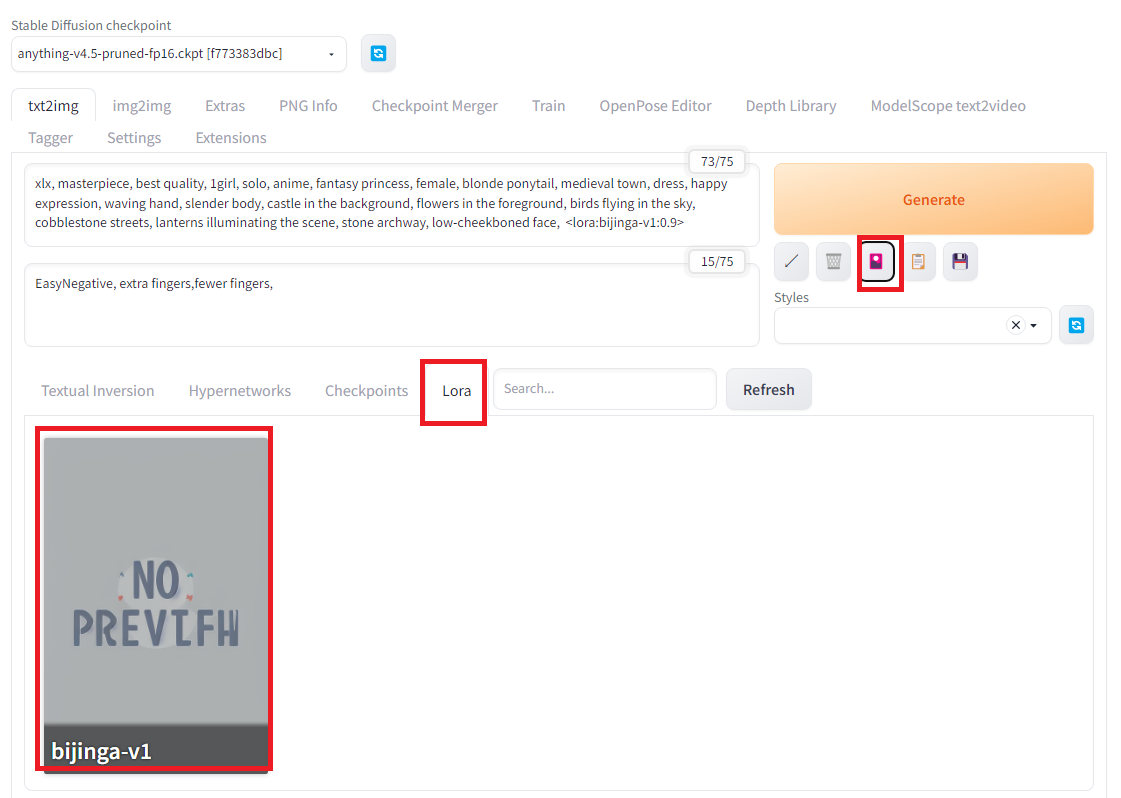
プロンプトを入れたら「Generate」ボタンで画像を生成します。美人画っぽい画像が生成しました。

parameters xlx, masterpiece, best quality, 1girl, solo, anime, fantasy princess, female, blonde ponytail, medieval town, dress, happy expression, waving hand, slender body, castle in the background, flowers in the foreground, birds flying in the sky, cobblestone streets, lanterns illuminating the scene, stone archway, low-cheekboned face, <lora:bijinga-v1:0.9> Negative prompt: EasyNegative, extra fingers,fewer fingers, Steps: 20, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 3046064259, Size: 640x800, Model hash: f773383dbc, Model: anything-v4.5-pruned-fp16
続いて、「Script」のx/yプロットを使って最適なLoRAの強度を見てみます。

強度については、0.7~1.0くらいの間がよさそうです。
強度0.9でいろいろな美人画を生成してみます。ブロンドのポニーテールでドレスを着た女性です。

黒髪の着物の女性も生成してみます。

今回はLoRAで美人画の画風を学習してみました。学習モデルを作ることで、画像の画風を再現できるようになりました。

