

VOICEVOXは、商用利用が可能である(※キャラクター毎に利用規定があります)無料のテキスト読み上げソフトです。ホームページ上では中品質と言われていますが、実際にはかなりの高品質の読み上げソフトです。使いやすいUIも用意されていますが、今回はPythonなどのプログラムに組み込むことができるVOICEVOXエンジンを実装してみることにします。
※本記事は2022年12月現在の情報に基づき作成しています。(情報としては古いですがアーカイブとして残しています。)
VOICEVOXエンジンのインストール
前準備1:PythonとGit環境
前提として、Pythonの環境が構築されていることが条件になります。PythonはPython.orgからインストールします。今回は、公式の開発環境に合わせて、Python3.8.10をインストールします。また、今回の導入ではGitを使いますので、Gitのwebサイトからインストールします。以下の記事もご参考ください。


前準備2:C/C++環境
さらにVOICEVOXエンジンで使うpypenjtalkというテキスト音声合成システムのOpen-JTalkのPythonラッパーのパッケージをインストールするためには、C/C++コンパイラー、cmake、cythonが必要になります。C/C++コンパイラー、cmakeは「VisualStadio」(VisualStadio Codeとは別物)の「C++によるデスクトップ開発」からインストールします。下のリンクからVisualStadio2022のカスタムインストールで「C++によるデスクトップ」と「MSVC」、「CMakeツール」にチェックを入れてインストールします。

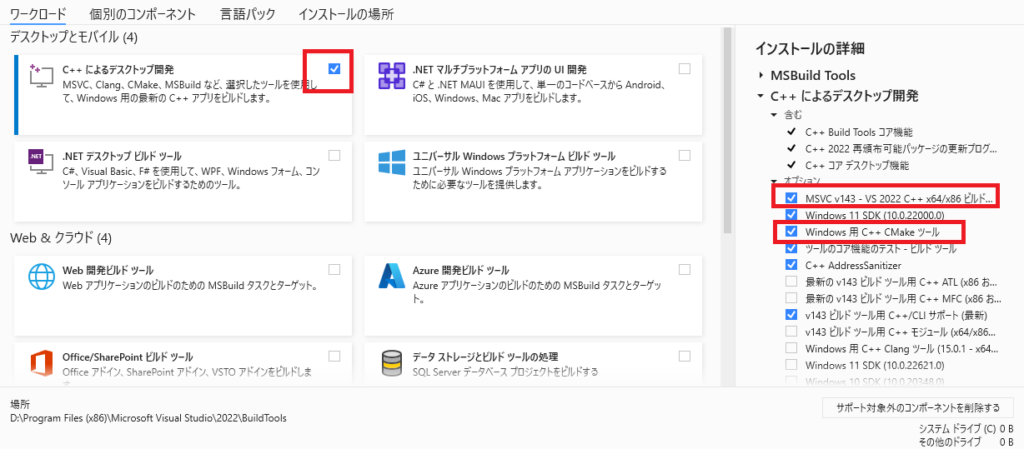
続いて、コンパイラとCMakeにPATHを通します。「システムの詳細設定」から「環境変数」の中のPATHを編集で開き、cmakeとコンパイラのPATHを追加します。VisualStadioのインストールしているところで、あてはまるbinフォルダを追加します。追加後、再起動します。
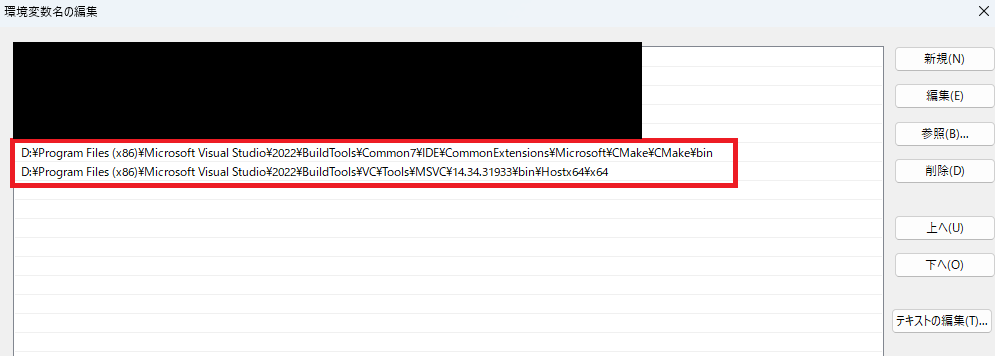
私はpypenjtalkのインストールがエラーでうまくいかず、苦戦しました。。。
仮想環境の構築
今回、VOICEVOX用の仮想環境を作っていきます。作成したいフォルダに移動します。今回、voicevoxというフォルダの中に作っていきます。今回はpython3.9とvenvで仮想環境を作ります。仮想環境はWindowsの場合は、Scriptsの下の「Activate.ps1」を起動することにより、仮想環境に入れます。以下の作業については、すべて仮想環境中で行いますので、再起動などして、仮想環境から抜けてしまった場合は、仮想環境の上のフォルダに行って、「.\venv\Scripts\Activate.ps1」を入力することで、仮想環境に入りなおすことができます。(仮想環境から出るには、「deactivate」コマンドを使います)
> mkdir voicevox
> cd .\voicevox\
> py -3.8 -m venv venv
> .\venv\Scripts\Activate.ps1
(venv) > python -V
Python 3.8.10まずは、pipとsetuptoolsを最新版にしておきます。
(venv) > python -m pip install -U pip setuptoolsVOICEVOXエンジンのダウンロード
VOICEVOXエンジンはGitHub上で公開されているので、自分の環境にcloneを作成します。
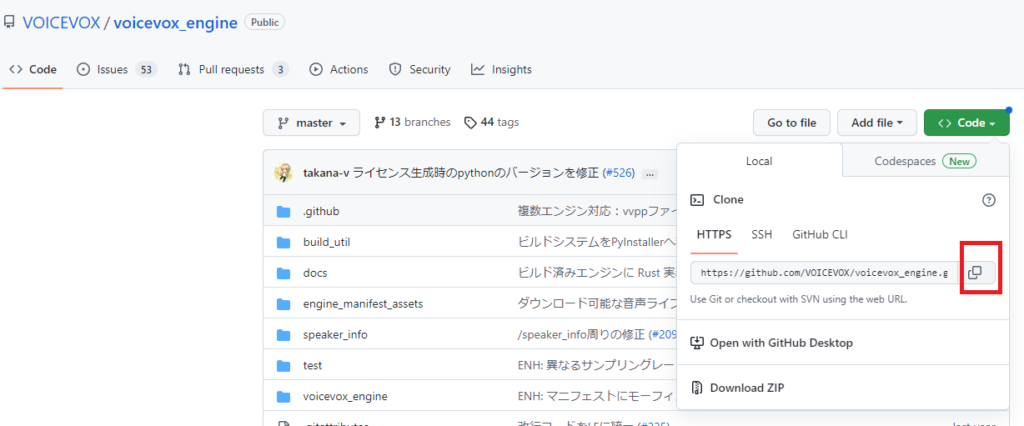
GitHubのページから、URLを取得し、Gitコマンドでクローンを作成します。
(venv) > git clone https://github.com/VOICEVOX/voicevox_engineこれで、カレントディレクトリに「voicevox_engine」というディレクトリができていると思います。
ライブラリのインストール
「voicevox_engine」の中に入って、必要なライブラリをインストールします。
(venv) > cd .\voicevox_engine\
(venv) > python -m pip install -r requirements-test.txtpipがうまく通れば、インストールの成功です。
エンジンのインストール
音声合成のエンジンについては、別に配布されています。下記のページから、必要なエンジンをダウンロードします。GPUが使える場合はGPU用を、CPUしか使えない場合はCPU用のエンジンをダウンロードします。CPU用は実行時間がかかるので、もし、NVIDIA製GPU搭載のPCを持っている方は、GPU環境を構築したうえで、GPU版を使うことをお勧めします。(参考:WindowsへのNVIDIA CUDAのGPU環境構築)
いずれもファイルは7-zip形式で圧縮されているので、解凍用に7-zipを使います。

7-zipで展開したファイルはvoicevox-engineのディレクトリの分かりやすいところに置きます。今回は、「engines」というフォルダを作ってその中に入れます。
VOICEVOXエンジンを使う
VOICEVOXエンジンの起動(GPUを使わない場合)
それでは準備ができたので、起動します。VOICEVOXエンジンはローカルのHTTPサーバーとして起動します。立ち上がったlocalホストへwebブラウザにリクエストを行う形で操作します。
(venv) > python run.py --voicevox_dir="./engines/windows-cpu"
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:50021 (Press CTRL+C to quit)上記の場合はホストは「127.0.0.1」となっています。ホストのドキュメントにアクセスしてみます。「http://127.0.0.1:50021/docs」をブラウザの検索窓に入れて、アクセスするとVOICEVOX ENGINEのAPIのドキュメントが確認できます。
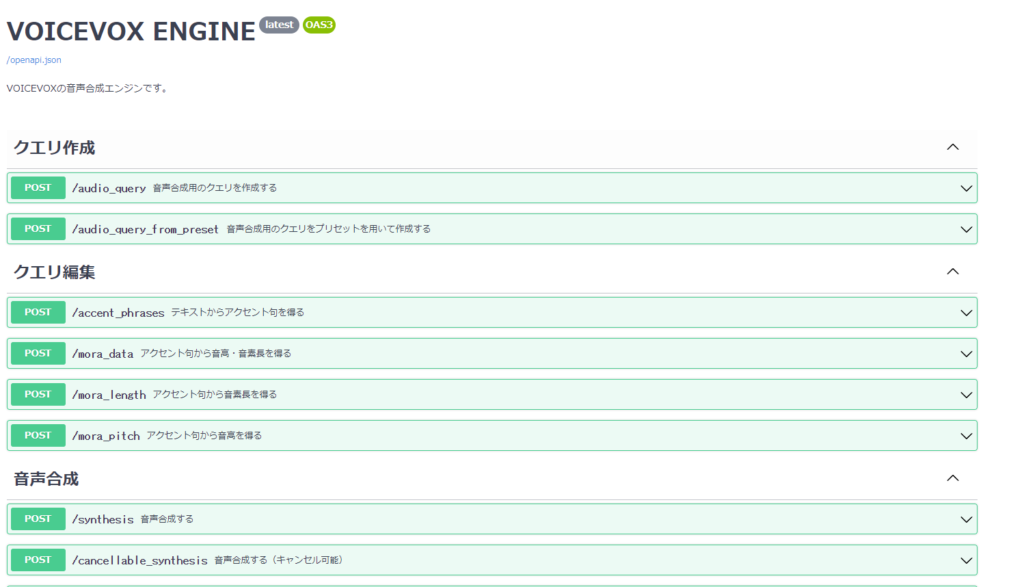
VOICEVOXエンジンの起動(GPUを使う場合)
GPUを使うとCPUの場合より音声合成に掛かる時間を短縮できます。NVIDIAのCUDA環境を構築している場合は、GPU対応のVOICEVOXエンジンを指定することによりGPUを使えます。
(venv) > python run.py --voicevox_dir=".\engines\windows-nvidia" --use_gpuNVIDIAのGPUを搭載したPCを使う場合は以下の記事をご参考にGPU環境を構築してください。
GPU環境構築
WindowsへのNVIDIA CUDAのGPU環境構築
WindowsネイティブへのCUDA, PyTorchの環境構築
パソコン選び
生成系AIを使うためのGPU搭載おすすめパソコン
私の場合は、計算時に「please make sure cudnn_cnn_infer64_8.dll is in your library path」のようなエラーが出て最初うまくいきませんでした。この記事を参考にzlibwapi.dllをダウンロードして、PATHの通ったディレクトリに入れることで、うまくいきました。
VOICEVOXエンジンのAPI操作の準備
今回は、Jupyter Lab環境でVOICEVOXエンジンのAPIを使ってみます。必要なライブラリをインストールします。pyaudioはVOICEVOXで生成されるwavファイルを再生するのに使います。
(venv) > pip install jupyterlab
(venv) > pip install pyaudioVPICEVOXエンジンのAPIから音声合成データの取得と再生
Jupyter Labを起動して、APIから音声合成データを作成してみます。
(venv) > jupyter lab基本的な操作については、「http://127.0.0.1:50021/docs」に記載されているとおりです。基本的な流れは、①audio_queryでクエリを作成②synthsisで音声合成データの作成、③音声データの再生、の手順で行います。まずは一番シンプルなwavファイルへの出力のコードを見てみます。
import requests
import json
#文字列の入力
text = "私の名前はずんだもんです。東北地方の応援マスコットをしています。得意なことはしゃべることです。"
# 音声合成クエリの作成
res1 = requests.post('http://127.0.0.1:50021/audio_query',params = {'text': text, 'speaker': 1})
# 音声合成データの作成
res2 = requests.post('http://127.0.0.1:50021/synthesis',params = {'speaker': 1},data=json.dumps(res1.json()))
# wavデータの生成
with open('test.wav', mode='wb') as f:
f.write(res2.content)音声合成クエリの作成では、パラメータとして、’text’のキーで作成する音声の文章を、また、’speaker’のキーでは話者のIDを入れます。現在、15名、39種類の音声が音源として公開されています。各キャラクター毎に利用規定や禁止事項がありますので、詳しくは公式ページをご確認ください。原則、クレジットを記載したら商用、非商用問わず使えるものがほとんどだと思うので、非常にうれしい規定になっています。
音源IDとキャラクタの対応
2022年12月現在、登録されているキャラクタの一覧をまとめました。(使用は利用規定に従ってください)
| styleId | speakerName | styleName |
|---|---|---|
| 0 | 四国めたん | あまあま |
| 1 | ずんだもん | あまあま |
| 2 | 四国めたん | 四国めたん |
| 3 | ずんだもん | ずんだもん |
| 4 | 四国めたん | セクシー |
| 5 | ずんだもん | セクシー |
| 6 | 四国めたん | ツンツン |
| 7 | ずんだもん | ツンツン |
| 8 | 春日部つむぎ | 春日部つむぎ |
| 9 | 波音リツ | 波音リツ |
| 10 | 雨晴はう | 雨晴はう |
| 11 | 玄野武宏 | 玄野武宏 |
| 12 | 白上虎太郎 | ふつう |
| 13 | 青山龍星 | 青山龍星 |
| 14 | 冥鳴ひまり | 冥鳴ひまり |
| 15 | 九州そら | あまあま |
| 16 | 九州そら | 九州そら |
| 17 | 九州そら | セクシー |
| 18 | 九州そら | ツンツン |
| 19 | 九州そら | ささやき |
| 20 | もち子さん | もち子さん |
| 21 | 剣崎雌雄 | 剣崎雌雄 |
| 22 | ずんだもん | ささやき |
| 23 | WhiteCUL | WhiteCUL |
| 24 | WhiteCUL | たのしい |
| 25 | WhiteCUL | かなしい |
| 26 | WhiteCUL | びえーん |
| 27 | 後鬼 | 人間ver. |
| 28 | 後鬼 | ぬいぐるみver. |
| 29 | No.7 | No.7 |
| 30 | No.7 | アナウンス |
| 31 | No.7 | 読み聞かせ |
| 32 | 白上虎太郎 | わーい |
| 33 | 白上虎太郎 | びくびく |
| 34 | 白上虎太郎 | おこ |
| 35 | 白上虎太郎 | びえーん |
| 36 | 四国めたん | ささやき |
| 37 | 四国めたん | ヒソヒソ |
| 38 | ずんだもん | ヒソヒソ |
wavデータから直接出力
wavファイルを作らずに直接音声を出力することもできます。pythonでwavファイルを出力するにはpyaudioを使います。
import requests # APIを使う
import json # APIで取得するJSONデータを処理する
import pyaudio # wavファイルを再生する
import time # タイムラグをつける
# 文字列の入力
text = "私の名前はずんだもんです。東北地方の応援マスコットをしています。得意なことはしゃべることです。"
# 音声合成クエリの作成
res1 = requests.post('http://127.0.0.1:50021/audio_query',params = {'text': text, 'speaker': 1})
# 音声合成データの作成
res2 = requests.post('http://127.0.0.1:50021/synthesis',params = {'speaker': 1},data=json.dumps(res1.json()))
#
data = res2.content
# PyAudioのインスタンスを生成
p = pyaudio.PyAudio()
# ストリームを開く
stream = p.open(format=pyaudio.paInt16, # 16ビット整数で表されるWAVデータ
channels=1, # モノラル
rate=24000, # サンプリングレート
output=True)
# 再生を少し遅らせる(開始時ノイズが入るため)
time.sleep(0.2) # 0.2秒遅らせる
# WAV データを直接再生する
stream.write(data)
# ストリームを閉じる
stream.stop_stream()
stream.close()
# PyAudio のインスタンスを終了する
p.terminate()終わりに
VOICEVOXは細かい調整もできるようですが、まったく調整なしでもほとんど違和感のない音声を出力してくれます。すんたもんや四国めたんの元気な声を聞いているだけで楽しい気持ちになりますね。インストールが簡単で、操作しやすいUIも備えたエディター版もあります。また、直接アプリに搭載可能なコアライブラリもありますので、ゆくゆくはそちらも使いこなせるようになりたいものです。
今回はVOICEVOXエンジンを紹介しました。他にもいろいろな記事をあげているので、ご覧ください。わからない点があれば、投稿フォームからご質問をお待ちしています。

