

pandasは使わないとすぐに忘れてしまうものです。今日はMeCabで出力したテキストデータをpythonのpandasのMultiIndexのDataFrameに変換して、利用しやすくしてみましたので、その手順をメモに残します。
※本記事は2022年6月現在の情報に基づき作成しています。(情報としては古いですがアーカイブとして残しています。)
MeCabの出力データの確認
今回の環境は前回までにDockerで作ったubuntuにPythonとMeCabを入れたものを使います。その環境をJupyterLabで起動して、ウェブブラウザから使います。MeCab-Pythonの環境構築はこちら(前半、後半)の記事をご覧ください。
対象データは首相官邸HPにある『令和4年6月15日の岸田内閣総理大臣記者会見』の内容をテキストでコピーしたものを用います。(テキストファイル:kaiken.txt)
文書については、著作権上差しさわりのない、政府発表のものを使わせていただきますm(_ _)m
まず、今回使用するMeCab、Pandas、Reの各ライブラリのimportとMeCabの処理のインスタンス化、文書の読み込みをしていきます。
# ライブラリのimport
import MeCab
import pandas as pd
import re
# MeCabのインスタンス化
mecab = MeCab.Tagger()
# 文書の読み込み
with open('./kaiken.txt', mode='r') as f:
s = f.read()
# 文書のスペースを削除して、句点『。』で切って、リスト化
s = "".join(s.split())
text_list = s.split("。")
# センテンスの数を表示
print('センテンスの数={}'.format(len(text_list)))センテンスの数=282
文書の7文目はこんな感じです。
# 9文目を出力
print(text_list[8])我が国は、欧米諸国に比べ、感染を極めて低いレベルに抑え込んでいます
この文書をMeCabで解析(parse)してやるとこんな感じになります。
# MeCabでの解析例
example = mecab.parse(text_list[8])
print(example)我が国 名詞,一般,*,*,*,*,我が国,ワガクニ,ワガクニ は 助詞,係助詞,*,*,*,*,は,ハ,ワ 、 記号,読点,*,*,*,*,、,、,、 欧米 名詞,固有名詞,地域,一般,*,*,欧米,オウベイ,オーベイ 諸国 名詞,一般,*,*,*,*,諸国,ショコク,ショコク に 助詞,格助詞,一般,*,*,*,に,ニ,ニ 比べ 動詞,自立,*,*,一段,連用形,比べる,クラベ,クラベ 、 記号,読点,*,*,*,*,、,、,、 感染 名詞,サ変接続,*,*,*,*,感染,カンセン,カンセン を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ 極めて 副詞,一般,*,*,*,*,極めて,キワメテ,キワメテ 低い 形容詞,自立,*,*,形容詞・アウオ段,基本形,低い,ヒクイ,ヒクイ レベル 名詞,一般,*,*,*,*,レベル,レベル,レベル に 助詞,格助詞,一般,*,*,*,に,ニ,ニ 抑え込ん 動詞,自立,*,*,五段・マ行,連用タ接続,抑え込む,オサエコン,オサエコン で 助詞,接続助詞,*,*,*,*,で,デ,デ い 動詞,非自立,*,*,一段,連用形,いる,イ,イ ます 助動詞,*,*,*,特殊・マス,基本形,ます,マス,マス EOS
この出力結果の型を見ると文字列で、各要素は、Tab(\t)、コンマ(,)、改行(\n)で区切られているのが分かります。
print(type(example))
example<class 'str'> '我が国\t名詞,一般,*,*,*,*,我が国,ワガクニ,ワガクニ\nは\t助詞,係助詞,*,*,*,*,は,ハ,ワ\n、\t記号,読点,*,*,*,*,、,、,、\n欧米\t名詞,固有名詞,地域,一般,*,*,欧米,オウベイ,オーベイ\n諸国\t名詞,一般,*,*,*,*,諸国,ショコク,ショコク\nに\t助詞,格助詞,一般,*,*,*,に,ニ,ニ\n比べ\t動詞,自立,*,*,一段,連用形,比べる,クラベ,クラベ\n、\t記号,読点,*,*,*,*,、,、,、\n感染\t名詞,サ変接続,*,*,*,*,感染,カンセン,カンセン\nを\t助詞,格助詞,一般,*,*,*,を,ヲ,ヲ\n極めて\t副詞,一般,*,*,*,*,極めて,キワメテ,キワメテ\n低い\t形容詞,自立,*,*,形容詞・アウオ段,基本形,低い,ヒクイ,ヒクイ\nレベル\t名詞,一般,*,*,*,*,レベル,レベル,レベル\nに\t助詞,格助詞,一般,*,*,*,に,ニ,ニ\n抑え込ん\t動詞,自立,*,*,五段・マ行,連用タ接続,抑え込む,オサエコン,オサエコン\nで\t助詞,接続助詞,*,*,*,*,で,デ,デ\nい\t動詞,非自立,*,*,一段,連用形,いる,イ,イ\nます\t助動詞,*,*,*,特殊・マス,基本形,ます,マス,マス\nEOS\n'
MeCab出力の整理
上記から、MeCabの解析結果の出力について、以下のことが分かります。
・各単語は、改行コード(\n)で区切られる。
・区切った形態素の表層形はTab(\t)で区切られる。
・各解析結果はコンマ(,)で区切られる。
なお、MeCabの作者のwebサイトでは出力フォーマットは以下の通りだと記載があります。
表層形\t品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音
なお、MeCabには出力フォーマットをいろいろ変更できる便利な機能もあるようですが、今回はそこを変更せずにやります。
最終的に、出力値を表層形から発音までの10個のデータを要素として、インデックスにセンテンスNoと単語Noを付与したMultiIndexのDataFrameを出力することにします。
まずは、『我が国は、欧米諸国に比べ、感染を極めて低いレベルに抑え込んでいます』の1文の最初の形態素の表層形『我が国』の出力結果を取ってきます。各形態素の解析結果は改行コードで区切られていますので、
・改行コードで区切ってリスト化
・そのリストの1要素を、Tab(\t)とコンマ(,)で区切ってリスト化
してやります。
# 1文を解析
example = mecab.parse(text_list[8])
# 改行で区切る
sep_sen = re.split('\n', example)
# 最終行のEOSを削除
sep_sen.pop()
# 解析結果をリスト化
print(re.split('\t|,', sep_sen[0]))['我が国', '名詞', '一般', '*', '*', '*', '*', '我が国', 'ワガクニ', 'ワガクニ']
ここで、「re.split(‘\n’, example)」は解析結果の文字列exampleを改行コード(\n)で分けて、リスト化しています。
さらに「re.split(‘\t|,’, sep_sen[0])」では、リストの「0番目」の形態素をTab(\t)、もしくはコンマ(,)で分けて、リスト化しています。
re.split(‘条件A|条件B’,文字列)
上の式で、条件A or 条件Bの部分で分けてリスト化するという正規表現での記述になります。
処理関数の実装
うまく文字列をリスト化できたので、上の式を関数に実装していきます。
# 各要素名をリスト化
cols = ['sentence','word']+re.split('\t|,', '表層形\t品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音')
# 上記要素名に合わせたリストを出力する関数
#引数1:センテンスNo 引数2:センテンスの文字列
def class_separator(num0, mecab_sen):
sep_sen = re.split('\n', mecab_sen)
sep_sen.pop()
sep_words_list = []
for num1 in range(len(sep_sen)-1):
sep_words_list.append([num0,num1]+re.split('\t|,', sep_sen[num1]))
return sep_words_list試しに関数class_separater()を使って、リスト化し、できたリストの先頭2列をインデックスとしたMultiIndexのDataFrameを作成します。
# 関数例
example = mecab.parse(text_list[8])
l = class_separator(8,example)
# リストをDataFrameに変換。最初の2列をMultiIndexに指定。
df = pd.DataFrame(l, columns = cols).set_index(cols[0:2])
df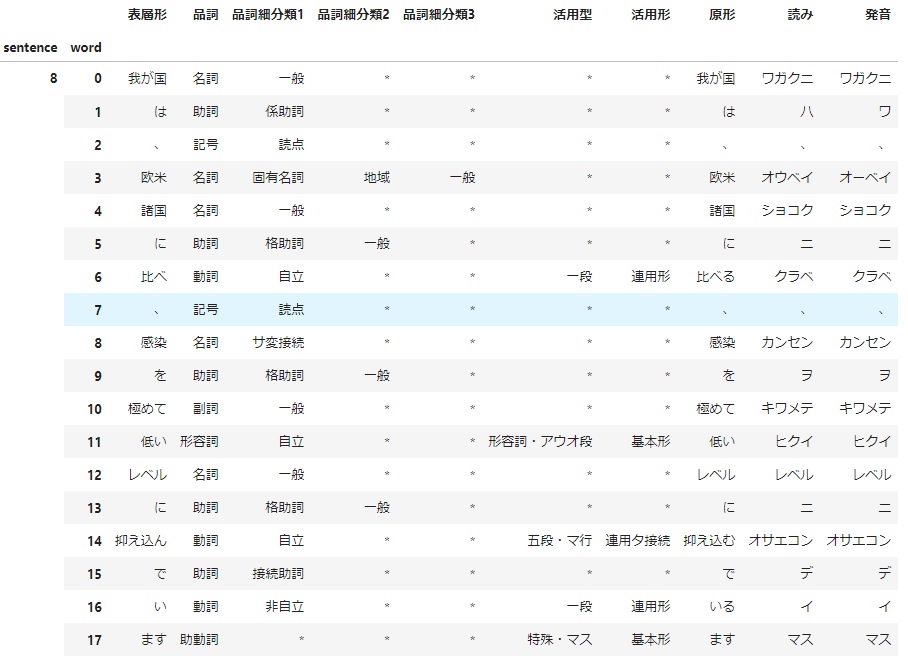
うまくDataFrameに出力できました。
まとめ
最後に文章を入力したらMultiIndexのDataFrameを出力する関数を作成します。
# ライブラリのimport
import MeCab
import pandas as pd
import re
# MeCabのインスタンス化
mecab = MeCab.Tagger()
# 各要素名をリスト化
cols = ['sentence','word']+re.split('\t|,', '表層形\t品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用型,活用形,原形,読み,発音')
# 上記要素名に合わせたリストを出力する関数
#引数1:センテンスNo 引数2:センテンスの文字列
def class_separator(num0, mecab_sen):
sep_sen = re.split('\n', mecab_sen)
sep_sen.pop()
sep_words_list = []
for num1 in range(len(sep_sen)-1):
sep_words_list.append([num0,num1]+re.split('\t|,', sep_sen[num1]))
return sep_words_list
# text_listからMeCabの解析結果をDataFrameで返す関数
def mecab_df_maker(text_list):
df = pd.DataFrame([])
for n in range(len(text_list)):
l = class_separator(n, mecab.parse(text_list[n]))
df = pd.concat([df, pd.DataFrame(l, columns = cols).set_index(cols[0:2])])
return df# 文書の読み込み
with open('./kaiken.txt', mode='r') as f:
s = f.read()
# 文書のスペースを削除して、句点『。』で切って、リスト化
s = "".join(s.split())
text_list = s.split("。")
# 処理の実行
df =mecab_df_maker(text_list)
df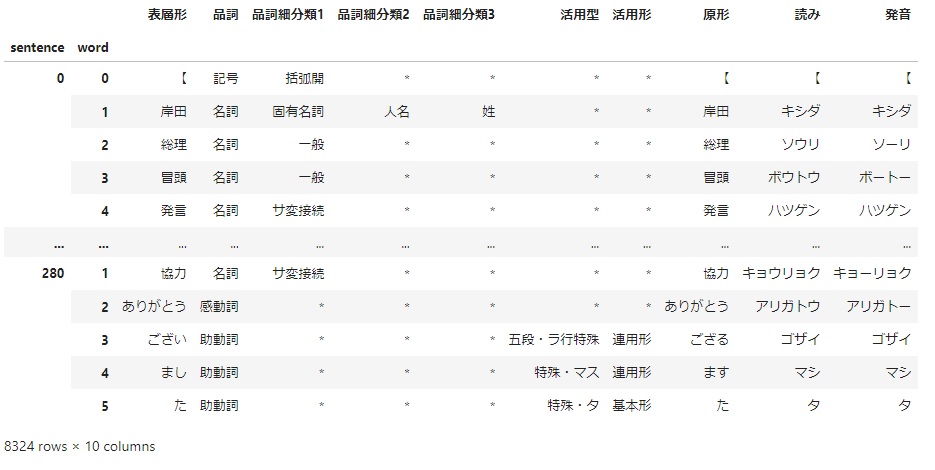
文章全体をDataFrameに変換できました。

