MeCabで形態素解析した文章をPandasのMultiIndexのDataFrameに整理したデータをベースとして、複合名詞(2つ以上の名詞がつながった名詞)の出現回数をカウントしてみます。
※本記事は2022年6月現在の情報に基づき作成しています。(情報としては古いですがアーカイブとして残しています。)
元データの確認
使用するデータは前回解析した『令和4年6月15日の岸田内閣総理大臣記者会見』の内容をテキスト(テキストファイル:kaiken.txt)をPandasのMultiIndexに取り込んだものを使います。
前回の記事:MeCabの出力をPandasのMultiIndexのDataFrameに変換してみた
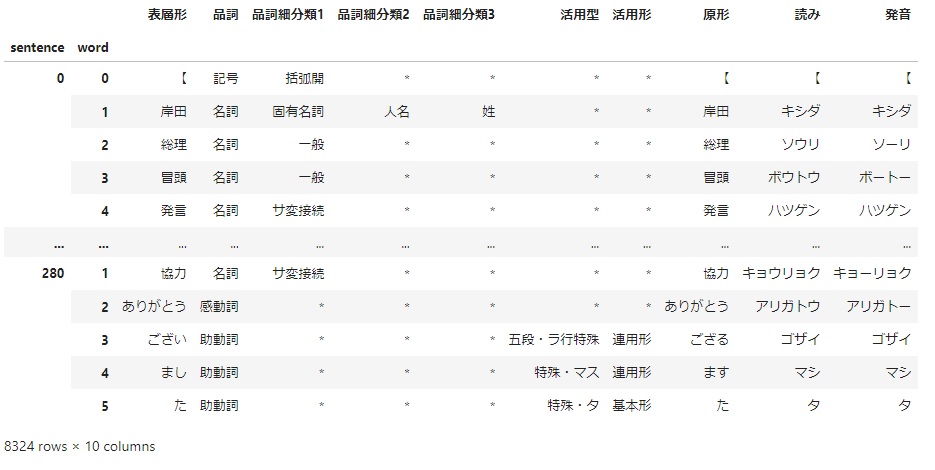
こんな感じのDataFrameになっています。
複合名詞の抽出
ここでは、sentenceのindexが『4』の文を取り出して、部分的な複合語の抽出をしてみます。
df_tmp = df.loc[4]
df_tmp.head(10)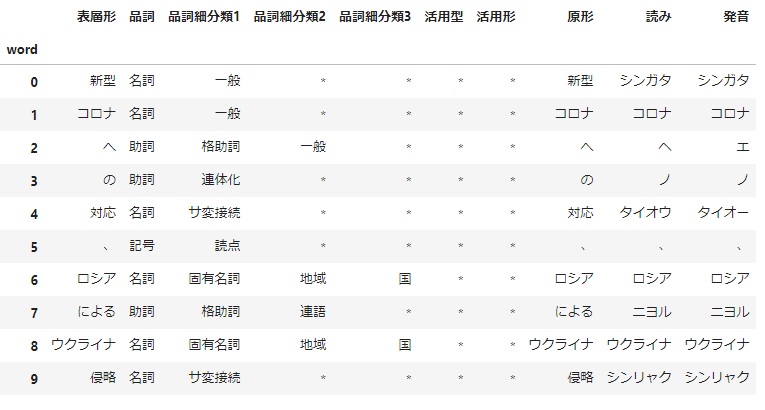
この中でいえば、『新型コロナ』や『ウクライナ侵攻』が複合名詞にあたります。
『品詞』の列に着目し、『名詞』が出てくる行の『表層形』を確認し、複合名詞にカウントしていきます。
multi_word_list = []
noun_flag = 0
for i in range(len(df_tmp)):
if df_tmp['品詞'][i] == '名詞':
noun_flag += 1
if noun_flag >=2:
extracted_noun = extracted_noun + df_tmp['表層形'][i]
else:
extracted_noun = df_tmp['表層形'][i]
else:
if noun_flag >= 2:
multi_word_list.append(extracted_noun)
noun_flag = 0
else:
extracted_noun = ""
noun_flag = 0
print(multi_word_list)かなり泥臭いコードになりましたが、『noun_flag』で名詞の連続して出現する回数をカウントし、2回以上連続が続いた場合に複合名詞と判断し、『multi_word_list』に入れてやります。出力結果は以下の通りで、8個の複合名詞を出力しました。あくまで、MeCabの辞書の名詞の判定をベースにしているので、少し「ん?」と思う複合名詞があるように思います。。。
['新型コロナ', 'ウクライナ侵略', '世界的', '食料市場', '何十年', '一度', '危機的事態', '内閣総理大臣']
関数化と会見の全文への適用
上の判定式を関数化して、会見の全文に適用します。
# 複合名詞抽出の関数
def get_multi_word_list(df_tmp):
multi_word_list = []
noun_flag = 0
for i in range(len(df_tmp)):
if df_tmp['品詞'][i] == '名詞':
noun_flag += 1
if noun_flag >=2:
extracted_noun = extracted_noun + df_tmp['表層形'][i]
else:
extracted_noun = df_tmp['表層形'][i]
else:
if noun_flag >= 2:
multi_word_list.append(extracted_noun)
noun_flag = 0
else:
extracted_noun = ""
noun_flag = 0
return multi_word_list
# 会見全文の解析
length = len(df.xs(0, level='word'))
multi_word_list = []
for i in range(length):
df_tmp = df.loc[i]
multi_word_list += get_multi_word_list(df_tmp)
multi_word_list['岸田総理冒頭発言', '通常国会', '補正予算', '61本', '内閣提出法案', '7本', '会期内', '26年ぶり', '国会運営', '新型コロナ', 'ウクライナ侵略', '世界的', ...(以下、略)
何ページにも渡る複合名詞リストが出てきました。
複合名詞の頻度カウントとランク付け
今度はこれをpython標準で入っているcollectionsのライブラリを用いて、ランク付けをしてみます。
import collections
counter = collections.Counter(multi_word_list)
counter.most_common()[0:10][('岸田総理', 12),
('内閣広報官', 11),
('金融政策', 8),
('資本主義', 7),
('サル痘', 6),
('ウクライナ侵略', 5),
('有識者会議', 5),
('司令塔機能', 5),
('内閣感染症危機管理庁', 5),
('感染症対策部', 5)]
上位10個の複合名詞が出現回数とともに抽出できました。最初の二つの複合名詞は会見の本文ではなく、発言者を示す部分から切り取られたものなので、ここではランキングから外して、3位から22位までを少しformat文を使って整形したprint文で出力してみます。
print('会見での複合語 頻度20傑')
for i in range(2, 22):
print('第{}位 {} {}回'.format(str(i-1), counter.most_common()[i][0], counter.most_common()[i][1]))会見での複合語 頻度20傑 第1位 金融政策 8回 第2位 資本主義 7回 第3位 サル痘 6回 第4位 ウクライナ侵略 5回 第5位 有識者会議 5回 第6位 司令塔機能 5回 第7位 内閣感染症危機管理庁 5回 第8位 感染症対策部 5回 第9位 憲法改正 5回 第10位 現実的 5回 第11位 核兵器禁止条約 5回 第12位 新型コロナ 4回 第13位 世界的 4回 第14位 4項目 4回 第15位 NPT運用検討会議 4回 第16位 核兵器国 4回 第17位 日韓関係 4回 第18位 首脳会談 4回 第19位 補正予算 3回 第20位 国際社会 3回
これを見ると、どんな言葉が会見で多く語られたか分かります。時の総理大臣が何に注目しているかわかる内容です。
今回はMeCabで解析した結果を加工して、複合名詞の抽出とランキング作成を行ってみました。