

Pythonのpandasはデータの解析に有用なツールである。今回は、国際特許分類(IPC)の整理をpandasで行い、特許解析に役立てたい。その前準備として、国際特許分類(IPC)について調べて、まとめてみた。
※本記事は2022年5月現在の情報に基づき作成しています。(情報としては古いですがアーカイブとして残しています。)
国際特許分類(IPC)について
Wikipediaによると、国際特許分類(International Patent Classification、IPC)とは、世界知的所有権機関(WIPO)が管理する国際的の取り決められた特許分類のルールによって作られている。特許のIPCを見れば、その特許が何に関する発明かわかるので、特許解析をする上では非常に重要である。日本語版のIPCは特許庁のホームページからダウンロードできる。
ダウンロードは、IPC分類表は、特許庁webページの「国際特許分類(IPC)について」から、ダウンロードページから行える。
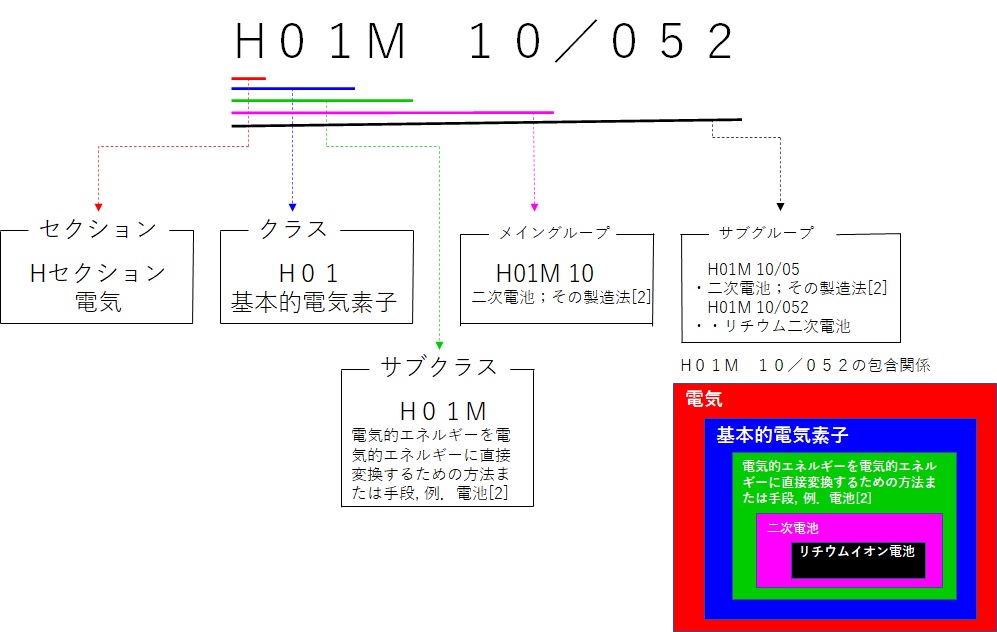
IPC分類は以下のような包含関係で示される。例えば、H01M 10/052のIPC分類の場合、先頭のHは「電気」のセクション記号を示す。さらにHセクションの中で、H01は「基本的電気素子」を示す。また、その中で、H01Mは「電池」のような、「電気エネルギーを直接変換する方法や手段」を示す。さらに、H01M 10は「二次電池」を示す。その/(スラッシュ)以下はサブグループを示し、サブグループは2桁から6桁の数字で示される。サブグループの中で、H01M 10/052は「リチウムイオン電池」を示すが、前に「・・」がついており、それは、前の「・」のH01M 10/05に包含関係にあることを示す。
PythonによるIPC整理の考え方
ここでは、特許庁のページからダウンロードできるIPC分類表をPythonを使って整理し、IPCを入力したら、そのセクション、クラス、サブクラス、メイングループおよびサブグループを返すような関数を作ることを目標としてみる。
IPCは頻繁にアップデートされるので、特許庁のHPからダウンロードできるExcelファイルから直接IPCの変換データが作成できるようにしたい。特許庁からダウンロードできるExcelファイルは、脚注や索引などの分類データ以外の情報も含まれているため、ExcelファイルからPandasで読み出すだけでは、きれいな分類表は作れない。また、クラスからサブグループまでの各階層が一様に列挙されているので、その行がどの階層の情報かの見極めが必要である。さらに、サブグループの「・」の数で示される包含関係も考えたい。
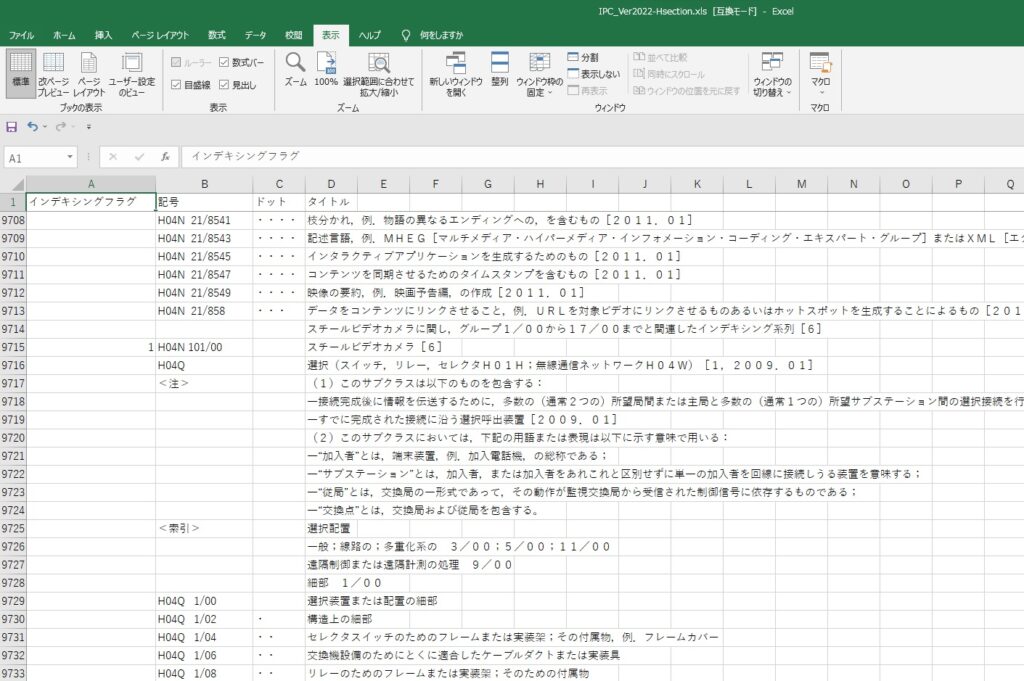
ここでは、HセクションのExcelのデータをPandasで読み出し、IPC分類を整理してみることにする。

