データ解析におけるモデル作成の流れについてメモ。pandas, matplotlib, seabornは機能が多彩で使いこなすのはなかなか難しいですが、いろいろ簡単にデータの外観をつかむのに有用なコマンドがあります。
Gerd AltmannによるPixabayからの画像(アイキャッチ画像の背景)
※本記事は2022年7月現在の情報に基づき作成しています。(情報としては古いですがアーカイブとして残しています。)
データの読み込み
CSVファイルの読み込み
import pandas as pd
# PATHに読み込むデータのパスを入れる
PATH = 'data.csv'
df = pd.read_csv(PATH)探索的データ分析(EDA)
参考サイト
探索的データ分析とは(IBM)
探索的データ分析(EDA)のステップと方法について実データ×Pythonで理解しよう!(スタビジ)
データを見る
# データ表示
dfデータの統計指標を確認
# データの統計指標
df.describe()- count : データ数
- mean : 算術平均
- std : 標準偏差
- min, max : 最小, 最大
- 25%, 50%, 75% : 第一四分位数(25%), 中央値, 第三四分位数(75%)
pandas_propfilingで概要把握
pandas_profiling API documentation
必要なパッケージ:pandas-profiling, ipywidget
# インストールされていない場合はpipなどでインストール
! python -m pip install pandas-profiling# インストールされていない場合はpipなどでインストール
! python -m pip install ipywidgetspandas-profilingレポートの作成
from pandas_profiling import ProfileReport
profile = ProfileReport(df, title="Pandas Profiling Report")JupyterLab内でのレポート表示
profileレポートのHTMLファイルへの出力
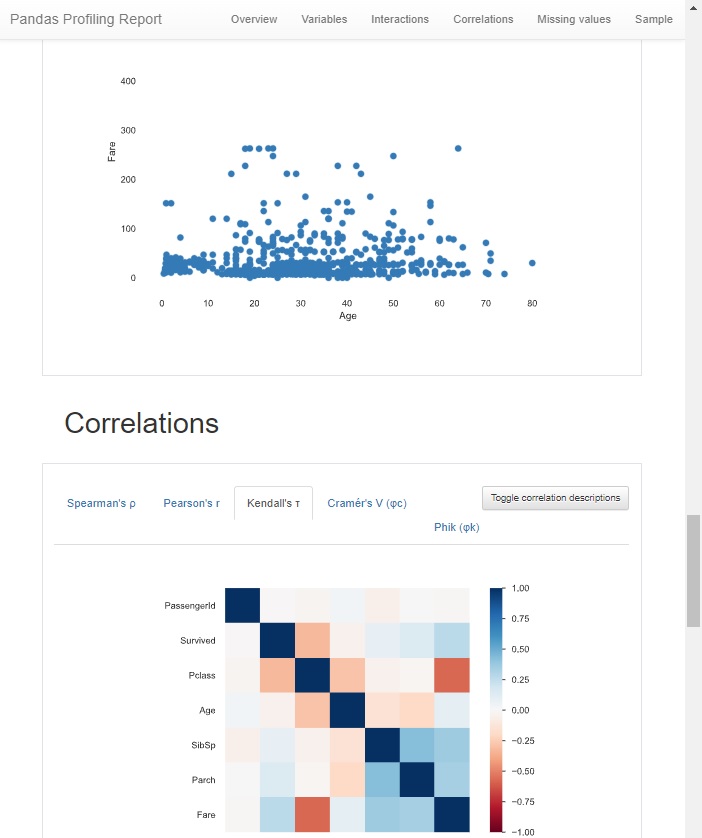
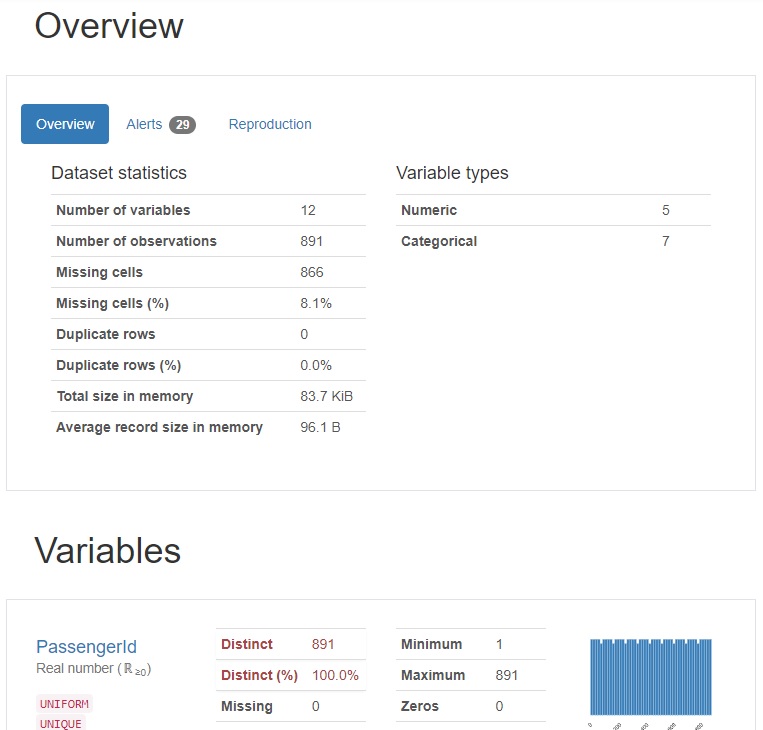
profile.to_file("report.html")レポートの一部
matplotlibで可視化
matplotlibはデータの可視化に超有用です。ということで、まとめようと思ったのですが、公式ページにすごいまとめのページがあったので、そもそもまとめる必要がありませんでした(;^_^A
ご存じない方は、必見です。
matplotlib公式ドキュメント Cheatsheets&Handouts

seabornで可視化
seabornも複雑なグラフを簡単に書ける超有用なライブラリです。
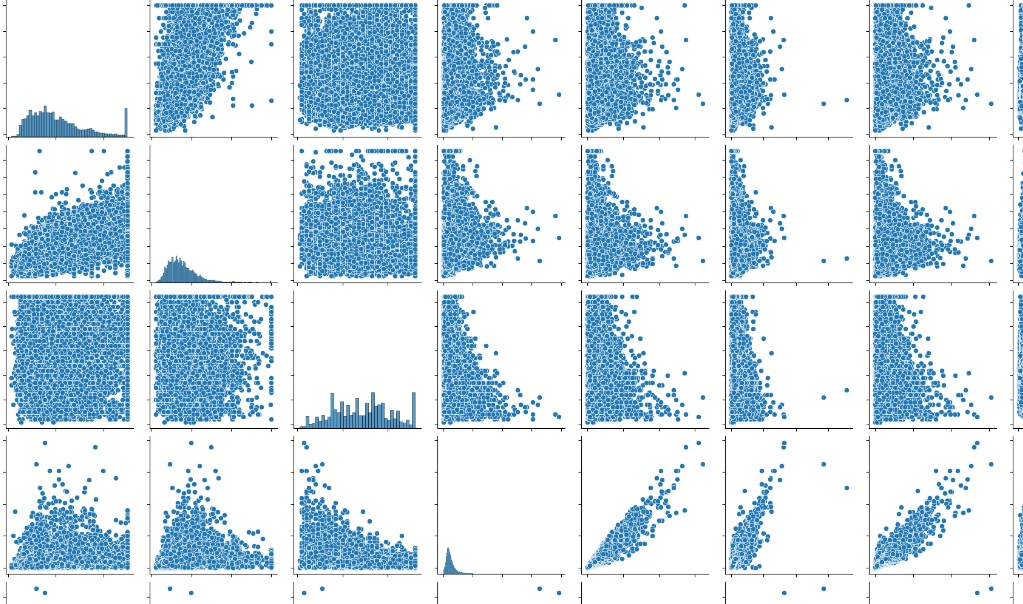
python -m pip install seaborn数値データの集まりであれば、とりあえずヒストグラムと相関プロットをみるだけでデータの外観がわかります。
import seaborn as sns
g = sns.PairGrid(df)
g.map_diag(sns.histplot)
g.map_offdiag(sns.scatterplot)