

Wordnetはプリンストン大学で開発された自然言語処理(NLP)のツールです。今回はWordnetの辞書を使って言葉遊びをしてみました。語句が豊富に登録されていて、非常に面白いです。
※本記事は2022年7月現在の情報に基づき作成しています。(情報としては古いですがアーカイブとして残しています。)
Wordnetとは
Wordnetはプリンストン大学で開発された自然言語処理(NLP)のツールです。シーソーラスという分類で呼ばれていて、同義語や類義語を上位と下位の関係性で示した辞書です。本家Wordnetは英語の辞書ですが、日本語版のWordnetも情報通信機構で作られたものが公開されています。Wordnetを使うことにより、英語だけではなく、日本語でも、文章中の単語同士の関連性をコンピュータに伝え、コンピュータが文書を意味を理解するの助けてくれます。
WordnetはNLTK(Natural Language Toolkit)というPythonのライブラリで操作できるので、簡単に扱うことができます。今回、NLTKからWordnetを使ってみます。
NLTK(Natural Language Toolkit)公式ページ
Wordnetのインストール
NLTKライブラリはコマンドラインから、pipコマンドなどでインストールできます。
python -m pip install nltk
....
Installing collected packages: regex, click, nltk
Successfully installed click-8.1.3 nltk-3.7 regex-2022.7.9辞書ファイルのインストール
JupyterLabでNLTKをインポートして使ってみます。まず最初に辞書ファイルのダウンロードをします。ダウンロードはnltk.download()のコマンドで専用のダウンローダーを立ち上げることができます。
# NLTKのインポート
import nltk
# 辞書ファイルのダウンロード
nltk.download()ダウンローダーが立ち上がったら、ダウンロードをする場所と、ダウンロードしたいアイテムを選択します。今回はDドライブのnltk_dataのファルダをダウンロード先に指定して、”all”をダウンロードします。ドライブ直下のnltk_data内にデータをダウンロードするとに、自動的にnltkがデータファイルを読みに行ってくれます。うまく読みに行ってくれない場合は、別途PATHを通して、nltk_dataにアクセスできるように設定する必要があります。
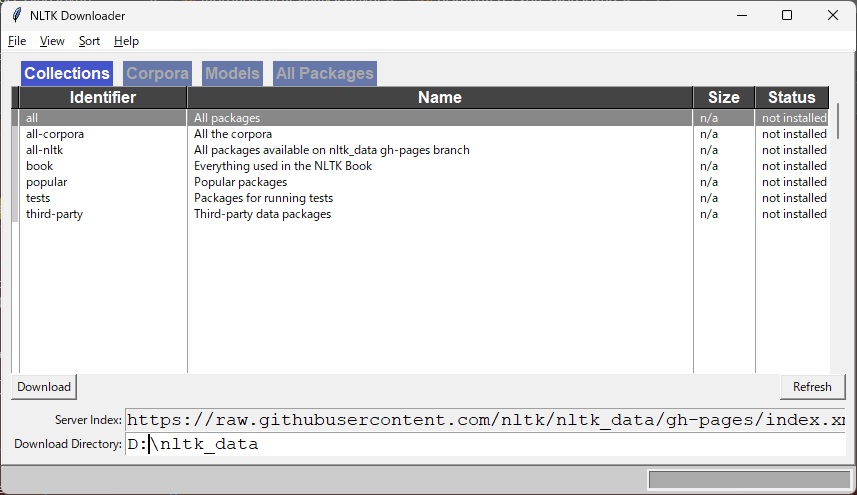
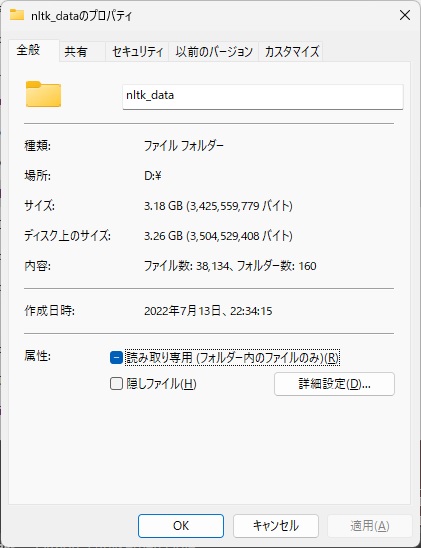
ダウンロードが終わったので確認してみます。全部で3.18GBの辞書データをダウンロードできました。
Wordnetを使ってみる
単語検索
それではWordnetで遊んでみます。Wordnetですが、最初に述べたようにシーソーラスという階層状に各単語の上下関係を収納しています。では、インポートして、さっそく単語を検索してみます。
# Wordnetをインポート
from nltk.corpus import wordnet as wn
# 単語検索
wn.synsets('earth')[Synset('earth.n.01'),
Synset('earth.n.02'),
Synset('land.n.04'),
Synset('earth.n.04'),
Synset('earth.n.05'),
Synset('worldly_concern.n.01'),
Synset('ground.n.09'),
Synset('earth.v.01'),
Synset('earth.v.02')]
単語の意味確認
n: 名詞として7件、v:動詞として2件が登録されています。では、先頭の’earth.n.01’と8番目の’earth.v.01’の意味をそれぞれ確認してみます。
# リストから1番目を指定してdefinitionで意味を確認
wn.synsets('earth')[0].definition()'the 3rd planet from the sun; the planet we live on'
「太陽系第3惑星。我々が住んでる惑星」と説明してくれました。
wn.synsets('earth')[7].definition()'hide in the earth like a hunted animal'
日本で意味確認
「地面に隠れること」をearthをいうらしいです。意味は日本語でも表示してくれます。
wn.synsets('earth')[0].definition(lang='jpn')['太陽から3番目の惑星', 'われわれが住んでいる惑星']
英語、日本語で類義語、同義語確認
続いて、類義語、同義語をみてみます。今回はearthの最初の用法に対する英語と日本語の類義語、同義語を表示してみます。
print(wn.synsets('earth')[0].lemma_names())
print(wn.synsets('earth')[0].lemma_names(lang='jpn'))['Earth', 'earth', 'world', 'globe'] ['グローブ', '世界', '地球']
動詞の意味確認
続いて、日本語の動詞「走る」を検索して、それぞれの意味を表示してみます。
[[x, x.definition(lang='jpn')] for x in wn.synsets('走る', lang="jpn")][[Synset('race.v.02'), ['競走で競い合う']],
[Synset('fly.v.02'), ['素早く、または突然動く']],
[Synset('run.v.29'), ['ランニングにより補う', '特定の距離を走る']],
[Synset('run.v.01'), ['自分の足を使って、常時地面から片足を上げ、速く動く']],
[Synset('drive.v.14'), ['力により推進されることによる動き']],
[Synset('rush.v.01'), ['速く動く']],
[Synset('rush.v.05'), ['フットボールで、ボールと一緒に走る']],
[Synset('run.v.26'), ['動物が速く動かせる']],
[Synset('breeze_through.v.01'), ['容易に成功する']]]
なるほど、日本語の「走る」は英語の「rush.v.05」と紐づけされて、フットボール用語になっているようです。日本語の辞書も英語を介した変換辞書になっているのでなかなか楽しいです。
形容詞の同義語、類義語
続いて、形容詞の「楽しい」の検索をしてみます。
wn.synsets('楽しい', lang="jpn")[Synset('happy.a.01'),
Synset('entertaining.s.01'),
Synset('gay.s.05'),
Synset('pleasant.a.01'),
Synset('enjoyable.s.01'),
Synset('delightful.s.01'),
Synset('good.s.15')]
「楽しい」から、happy, entertaining, gay, pleasant, enjoyable, delightful, goodの単語が紐づけれます。続いて、これらから類義語、同義語を引いてみます。setを使って重複を排除して、happyの中に追加していきます。
happy = set()
for x in wn.synsets('楽しい', lang="jpn"):
happy = happy.union(set(x.lemma_names(lang='jpn')))
print(happy){'仕合せ', '好い', '快い', '心地良い', '痛快', '幸福', '心うれしい', '御機嫌', 'ハッピー', '嬉しい', 'おもしろい', 'うれしい', 'よい', '大喜び', '幸せ', '麗しい', '満足', '小気味好い', '好いたらしい', '明るい', '快然たる', '面白い', '可笑しい', '心地好い', 'おもろい', '心嬉しい', '楽しげ', '善い', '賑やか', '小気味よい', 'ご機嫌', '心地よい', '愉しい', '快適', '愉しげ', '愉快', '悦ばしい', '仕合わせ', '喜ばしい', '楽しい', '良い', 'いい', '気持ち良い', '嬉々たる'}
44個の「楽しい」を表す単語が並びました。
単語の上位階層確認
続いて、「地球」という単語で、シーソーラスの上位レベルを見てみます。
for x in wn.synsets('地球', lang='jpn')[0].hypernym_paths()[0]:
print(x, x.definition('jpn'))Synset('entity.n.01') ['(生命がある、あるいは生命がないに関わらず)それ自身の明確な存在を持つと感知される、知られている、あるいは推定される何か']
Synset('physical_entity.n.01') ['物理的な存在がある実体']
Synset('object.n.01') ['触れることができて目に見える実体', '影を落とすことができる実体']
Synset('whole.n.02') ['1つのものとしてとらえらえる、部分の集合']
Synset('natural_object.n.01') ['天然にある物', '人間によって作られない']
Synset('celestial_body.n.01') ['空に見られる自然物']
Synset('planet.n.01') ['太陽の周りを公転し、反射光によって輝く太陽系の9つの大きな天体のいずれか', '太陽から近い順に、水星、金星、地球、火星、木星、土星、天王星、海王星及び冥王星', 'ヘラクレス星座から見るとすべての惑星は太陽の周りを時計と逆に回転している']
Synset('terrestrial_planet.n.01') ['地球のもののように小さい岩が多い表面がある惑星', '太陽系の4つの一番奥深い惑星']
Synset('earth.n.01') ['太陽から3番目の惑星', 'われわれが住んでいる惑星']
earth→terrestrial planet→planet→celestial body→natural object→whole→object→physical entity→entityと上位レベルに行くほど、概念的に言葉になっていき、面白いです。
単語の類似性確認
最後に単語同士の類似性を確認してみます。path_similarityを使うと単語同士の類似性を0~1で表示してくれます。例えば、dogとcatの類似性は0.2と表示されます。
word1="dog"
word2="cat"
wn.synsets(word1)[0].path_similarity(wn.synsets(word2)[0])0.2
その機能を使って、いろいろな言葉の類似性を調べてみます。ここでは日本語の単語同士を比較する関数を作って、いろいろな言葉で試してみます。
def word_similarity_jp(word1, word2):
syn = []
for i in range(len(wn.synsets(word1, lang="jpn"))):
for j in range(len(wn.synsets(word2, lang="jpn"))):
syn.append(wn.synsets(word1, lang="jpn")[i].path_similarity(wn.synsets(word2, lang="jpn")[j]))
return syn関数word_similarity_jpが定義できたので、様々な言葉を比較してみます。
word_list = [["地球","星"], ["音", "声"], ["宇宙", "空"], ["子供", "大人"], ["犬", "猫"], ["虎", "猫"],
["虎", "狼"], ["犬","狼"],["犬","ミミズ"],["ミミズ","ミジンコ"],["犬","リンゴ"], ["犬","鉛筆"]]
for i in range(len(word_list)):
print(word_list[i][0], word_list[i][1], max(word_similarity_jp(word_list[i][0], word_list[i][1])))地球 星 0.2 音 声 1.0 宇宙 空 0.25 子供 大人 0.3333333333333333 犬 猫 0.2 虎 猫 0.25 虎 狼 0.16666666666666666 犬 狼 0.3333333333333333 犬 ミミズ 0.125 ミミズ ミジンコ 0.1111111111111111 犬 リンゴ 0.08333333333333333 犬 鉛筆 0.09090909090909091
同じネコ科やイヌ科の動物が類似性が大きかったり、犬みたいな動物とリンゴや鉛筆など動かないものでは類似性が小さかったり、感覚とだいたい一致します。
最後に
Wordnetのようなシーソーラスはすべて、人の手によって作られています。ですので、更新も大変だったり、数も限りがあったりします。しかし、類義語だったり関連性を見るのには非常に便利な方法です。自分で収集したものを追加するとさらに強力なツールになるかもしれません。
関連情報
プリンストン大学のWordnet開発者の公式ページです
Wordnet公式ページ
PythonライブラリNLTKの公式ページです
NLTK(Natural Language Toolkit)公式ページ
日本語Wordnetの公式ページです。Wordnetで日本語が扱えるのに感謝です。
日本語版のWordnetページ
日本語ワードネット (XX版)© 2009-2011 NICT, 2012-2015 Francis Bond and 2016-2017 Francis Bond, Takayuki Kuribayashi

