Stable Diffusionの進化が止まりません。Sadtalker拡張機能を使うことで、Stable DiffusionのWebUIで何と画像がしゃべる動画を作成できます。ここでは、Sadtalkerのセットアップから使用方法まで丁寧に解説します。
※本記事は2023年5月現在の情報に基づき作成しています。(情報としては古いですがアーカイブとして残しています。)
Sadtalkerとは
Sadtalkerは、顔の画像とスピーチの音声から会話するムービーを作成する技術です。Sadtalkerは音声から頭部の姿勢や表情など3D情報を生成し、それを空間マッピングすることで最終映像を合成します。
一枚の画像と音声さえあれば、画像が動き出して実際にしゃべっているように見えます。本当に夢のような技術です。
Sadtalkerセットアップの前準備
・Stable Diffusion WebUI Automatic1111のセットアップ
Sadtalkerを使うためにStable Diffusion WebUI Automatic1111をセットアップします。セットアップの方法は下のリンク先をご参照ください。
・ffmpegのインストール
Sadtalkerでは音声の読み込みなどを行うためにffmpegをインストールする必要があります。ffmpegは動画や音声を扱うためのフリーウエアです。ffmpegは下の公式ページからダウンロードしてインストールできます。詳しくは以下に説明いたします。

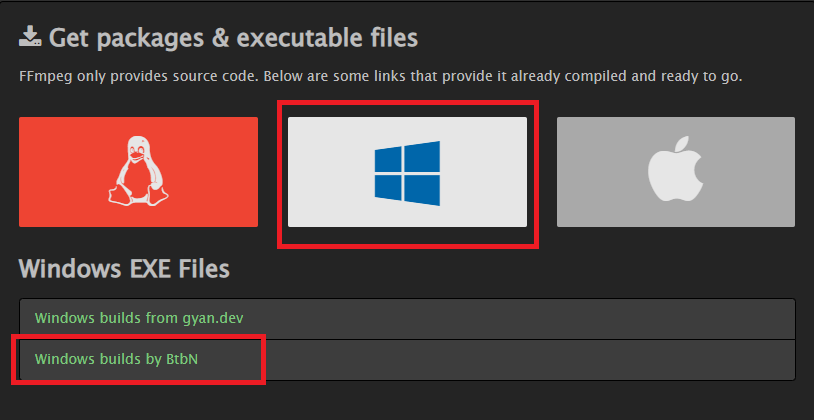
windows版は「Windows builds by BtbN」を選んでその先のzipファイルをダウンロードします。
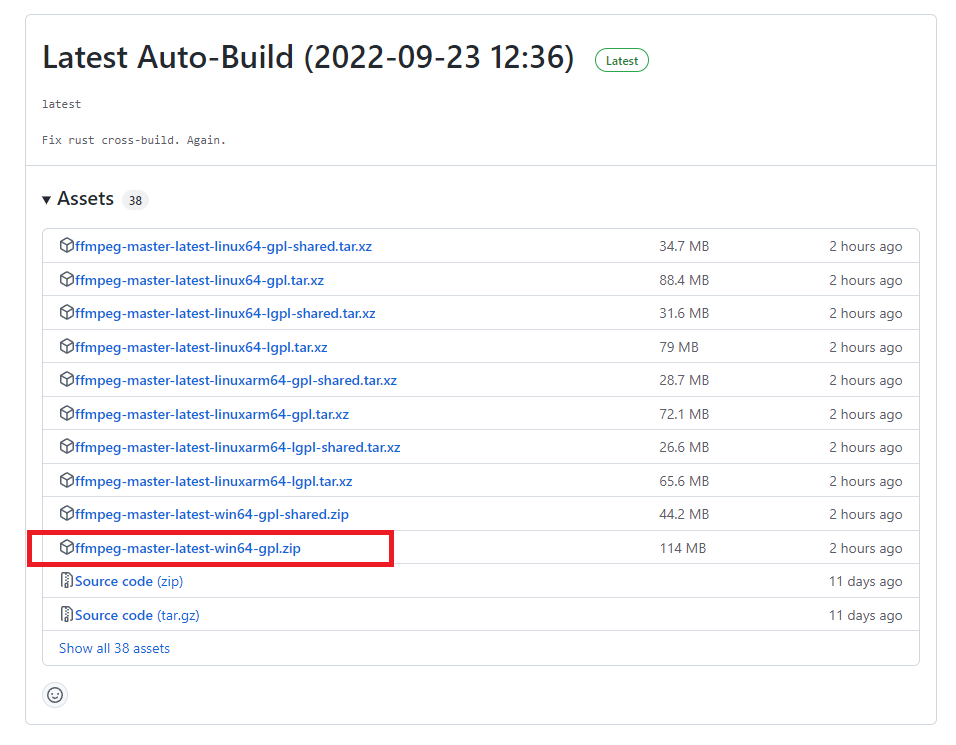
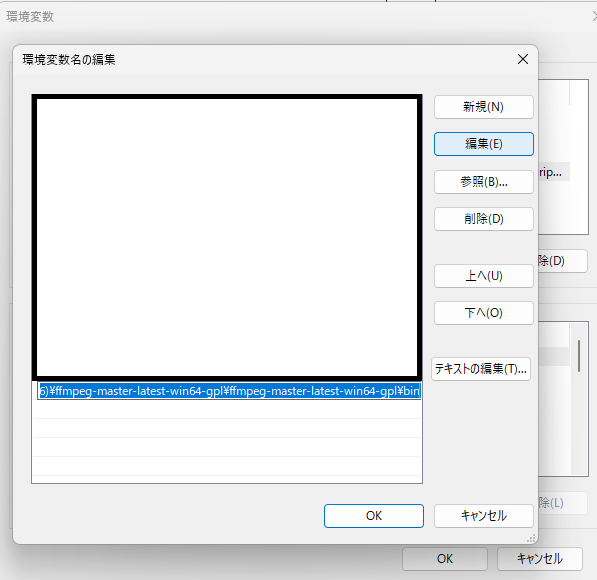
ダウンロードしたzipファイルを適当な場所に解凍したあと、環境変数名の編集からbinフォルダにPATHを通してから、一旦PCを再起動します。
> ffmpeg
ffmpeg version N-108306-ge7a987d7c9-20220923 Copyright (c) 2000-2022 the FFmpeg developers
built with gcc 12.1.0 (crosstool-NG 1.25.0.55_3defb7b)Shellから「ffmpeg」と入力するとffmpegの情報が表示され、インストールできたことが分かります。
Sadtalkerのインストール
Sadtalkerのインストールは①Sadtalker拡張機能のインストールと②Sadtalkerモデルの設置を順に行います。
Sadtalker本体はStable Diffusion WebUIの拡張機能からインストールできます。「Extensions」タグから「Install from URL」から下記の黄色のフォーム「URL for extension’s git repository」にgithubの配布リポジトリ「https://github.com/Winfredy/SadTalker」を指定し、「Install」ボタンを押してインストールします。
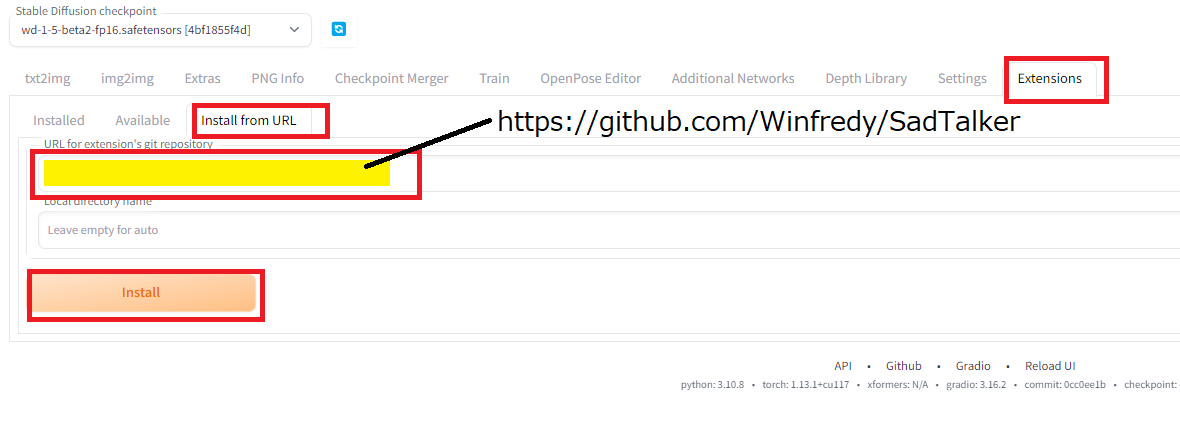
インストールボタンを押してしばらくすると、WebUIのExtensionsのフォルダの中にSadTalkerのフォルダが作られます。
次にモデルをダウンロードします。モデルはSadTalkerのフォルダ直下に設置する必要があります。モデルは、Windowsの場合は手動でダウンロードする必要があります。ちょっとややこしいです。checkpointsとgfpganをダウンロードします。
・checkpointsのダウンロード先
以下のいずれでもダウンロードできます。
・gfpganのダウンロード先
ダウンロードしたモデル等は以下のように配置しました。必要に応じてフォルダを作成してください。一部のファイルは圧縮したままだったりして本当に正しいのか良く分かりませんが、以下の配置でうまくいっているので、無駄なものもあるかもしれませんが、ご容赦ください。
stable-diffusion-webui
┗ extensions
┗ SadTalker
┗ checkpoints
┣ BFM_Fitting
┃ ┣ 01_MorphableModel.mat
┃ ┣ BFM_exp_idx.mat
┃ ┣ BFM_front_idx.mat
┃ ┣ BFM09_model_info.mat
┃ ┣ Exp_Pca.bin
┃ ┣ facemodel_info.mat
┃ ┣ select_vertex_id.mat
┃ ┣ similarity_Lm3D_all.mat
┃ ┗ std_exp.txt
┣ hub
┃ ┗ checkpoints
┃ ┣ 2DFAN4-cd938726ad.zip
┃ ┗ s3fd-619a316812.pth
┣ auido2exp_00300-model.pth
┣ auido2pose_00140-model.pth
┣ epoch_20.pth
┣ facevid2vid_00189-model.pth.tar
┣ mapping_00109-model.pth.tar
┣ mapping_00229-model.pth.tar
┣ shape_predictor_68_face_landmarks.dat
┗ wav2lip.pth
モデルなどを配し終わったら、WebUIを一旦終了して、「webui-user.bat」から起動しなおします。これで準備完了です。
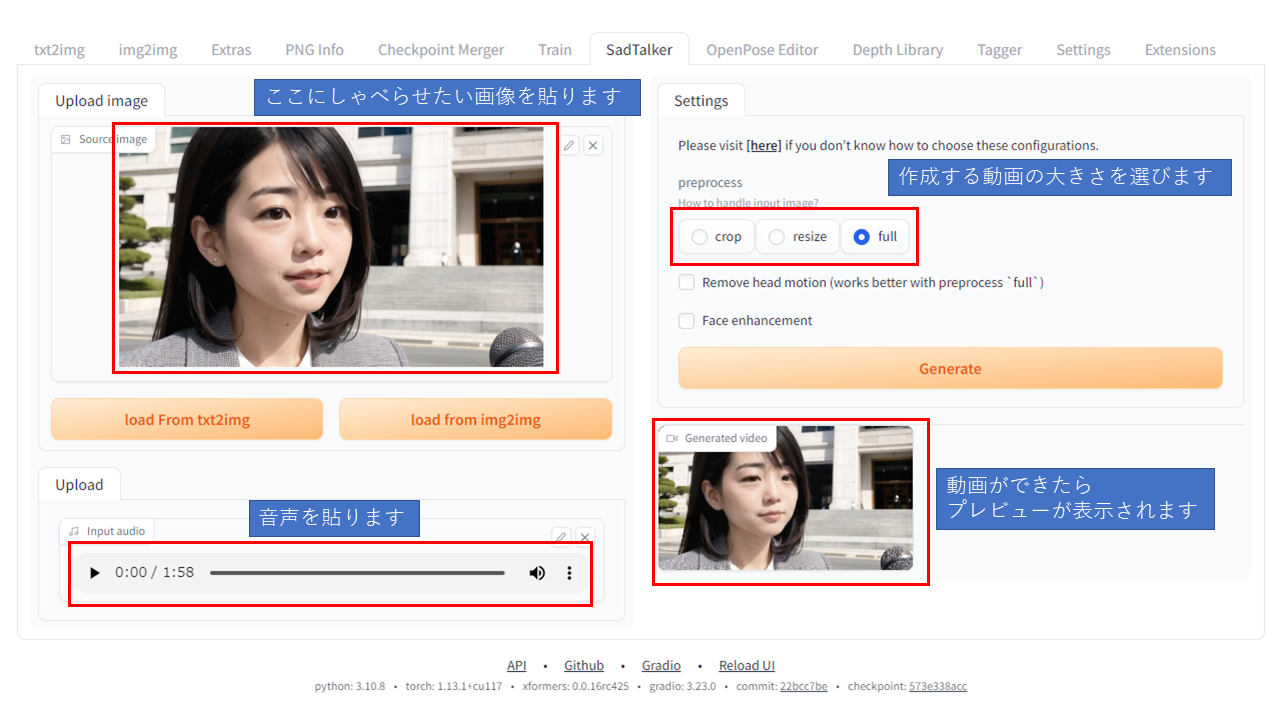
SadTalkerで動画作成
それではWebUIのSadtalkerで会話画像生成を行ってみます。今回、会話生成に使うのは、政府広報「明日への声」の音声を使用します。「明日への声」は内閣府大臣官房政府広報室が作成する広報音声で、政府の施策等を、分かりやすい内容にまとめて収録し、政府のwebサイトで公開されています。

今回、その中から令和5年3月発行分の「明日への声」から1分58秒のオープニング部分の動画を作成します。
動画の作成の方法は非常にシンプルです。画像と音声を添付して、実行するだけです。動画の生成が終わったら、「\stable-diffusion-webui\outputs\SadTalker」のフォルダの中に保存されます。今のところ、使う画像としては実写に近いものの方が成功率が高いようです。アニメ絵だとうまく顔を認識してくれないことがあるようですので、ご注意ください。