
新しいデスクトップPCの情報収集のために価格ドットコムのサイトをPythonでスクレイピングして、販売中のパソコンの相場感を調べようと思います。スクレイピングの勉強も兼ねて、初めてECサイトのスクレイピングに挑戦しています。試行錯誤していますが、同じようなこれからスクレイピングを始めたい人のご参考になればと思います。
なお、スクレピングは2022年8月12日現在の価格ドットコムのサイトから行っています。参考でコードを添付していますが、サイトの改造等でタグなどの構成が変われば、調整が必要になります。
実は、最近、自分は新しいPCを探しているので、今回のスクレイピングは自分のためでもあります。今回は価格ドットコムのサイトからデスクトップのゲーミングPCの販売データを取得して相場を調べてみました。前編ではデータをPandasに取り出すところまでを行っています。後編ではスペックと価格との関係までみていきたいとおもいます。
エラー対応更新(2022/10/14追記)
価格ドットコムサイトのwebデータの一部に変更があり、うまく文字列の抽出が通らなくなったので、したで以下の2点を追記、修正しました。
- 日付データの途中に’2022/07/_3’のようにスペースが入っていて、うまく日付が取れなくなったので、スペース削除したうえで、joinで結合するように変更。
- CPUスコアの一部に欠損値があるので、欠損値に対応した。
ライブラリのインポート
今回の作業は、インタラクティブなPythonの実行環境のJupyter Labを使います。さらにスクレイピングにはBeautifulSoup4とパーサーにlxml、あと、Webページの読み込みにはrequestsとtimeを使います。また、結果の解析にPandasとMatplotlibを使います。Jupyter Lab、BeautifulSoup4、lxml、Pandas、Matplotlibはもしインストールしていなかったら、pip等でインストールが必要ですので、適宜インストールをしましょう。
Jupyter Labのノートブックを立ち上げて、必要なライブラリをインポートします。
# ライブラリのインポート
import lxml.html
import matplotlib.pyplot as plt
import pandas as pd
import requests
import time
from bs4 import BeautifulSoup価格ドットコムからデータの取得
ダウンロード先の調査
価格ドットコムのサイトからrequestsを使ってwebサイトのデータを取得します。まずは一覧の商品ページが何ページあるのか調べてみます。1ページあたり40個の商品情報が載っています。商品一覧のページの製品数を取得してみます。手動で入れても問題ないのですが、今後、自動で実装することを念頭に入れて、webページから自動で読みを取るようにします。ブラウザにChromeを使って、「719製品」と書いてある部分で右クリックから、「検証」を選択すると検証モードが開き、その数字の書いてある部分を確認すると、下のようになっていることがわかります。
<p class="result"><span>719</span> 製品</p>
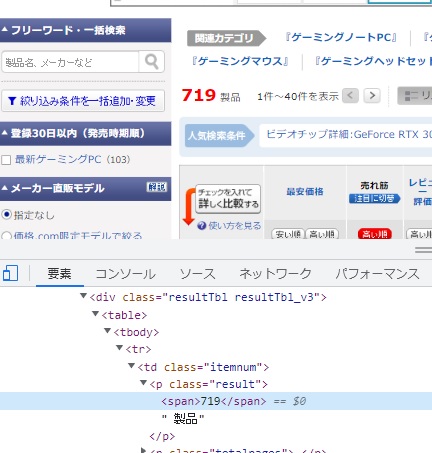
そこでbeautifulsoupで処理して、クラス属性から”result”を探して、その中のspanタグで囲まれたテキストを取得してみます。
url="https://kakaku.com/pc/gaming-pc/itemlist.aspx"
res = requests.get(url)
soup = BeautifulSoup(res.text,"lxml")
soup.find(class_="result").span.text'719'
うまく取得できることを確認できました。そこで、下記のように全製品数を40で割った商に1を足すことにより、ページ数が計算できました。
pages = int(soup.find(class_="result").span.text)//40 + 1
print(pages)18
価格ドットコムのゲーミングPC一覧ページのURLは下記のようになっており、最後の「pdf_pg=」の部分にページ番号が入ります。
https://kakaku.com/pc/gaming-pc/itemlist.aspx?pdf_vi=d&pdf_pg=1
ターゲットのURLが分かったので、次は具体的にデータをダウンロードしていきます。
Webページのダウンロード
ダウンロードするターゲットが決まったので、再びrequestsでページをダウンロードしていきます。今回は複数ページのダウンロードになります。一気に実行すると、短時間にGETリクエストを送ることになり、受け側のサーバーに負荷を与え、迷惑をかけることになりますので、timeライブラリのtime.sleepで待ち時間を作ってリクエストを同時に送らないように設定します。ここでは、1ページのダウンロードごとに5秒の待ち時間を作ります。今回はhtmlのテキストのみの18ページのダウンロードになりますが、ダウンロードするファイルが大きかったり、量が多かったりする場合は、小分けにする必要があります。また、requestsは繰り返し実行しないように、一度成功したら、変数やローカルに収納して、なるべくコードの手直しごとにダウンロードを繰り返し行わないような配慮が好ましいと思います。
参考ページ
スクレイピングとは?違法性があるデータの活用方法とその対処を解説(ココナラ法律相談)
# 上で確認したページ数を入力
pages = 18
# データダウンロード
page_url_base = "https://kakaku.com/pc/gaming-pc/itemlist.aspx?pdf_vi=d&pdf_pg="
res = []
for i in range(1,pages+1):
page_url = page_url_base + str(i)
print(page_url)
res.append(requests.get(page_url))
time.sleep(5)今回はresというリスト変数にダウンロードしたデータを入れておきます。
Webページの解析
スープの作成
続いて、Webページの解析を行っていきます。一覧ページの情報と実際にダウンロードしたWebページのHTMLを見比べて、Beautifulsoupで必要な情報を抽出する準備をします。
やり方はいろいろあるかと思いますが、まず、Chromeの「検証」機能を使って該当する部位のあたりをつけていきます。Webページの気になる部分で右クリックをすることで表示されるクリックメニューから、「検証」を選択すると、ページのHTMLが表示され、該当部分がハイライトされます。
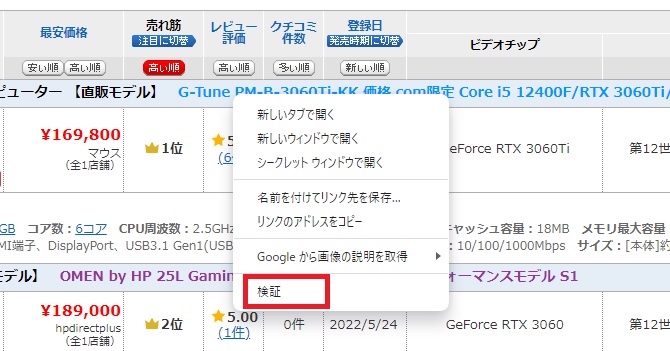
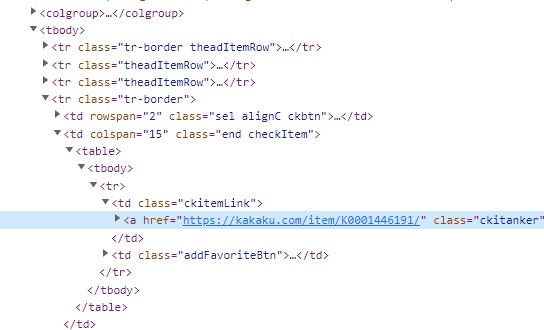
その後、HTMLの内容から抽出したい文字列の方法を考えてみるとことにします。(※このスプレイピングはほぼ試行錯誤の自己流ですので、本当はもっと良い方法があるかもしれません。)
今回の価格ドットコムのページは各製品ごとに3行のテーブルに分けて記述されていました。各行はクラス属性”tr-border”が設定されているようなので、”tr-border”毎にbeautifulsoupで「スープ」を作って、結果をelemsのリストに入れることにします。価格ドットコムのWebサイトはclass属性を多用してくれているので、class属性で必要な部分を探していけば、たいていは用が足りるようです。
elems = soup.find_all(class_="tr-border")作成したelemsを確認します。
len(elems)122
40個の製品データに対して、”tr-border”で抽出したスープが122個ありました。各製品ごとに3行のテーブルを使っているので、40×3=120はちゃんと製品データが取り出せているようです。また、elems[0]とelems[1]は確認すると、テーブルのヘッダー部分で、製品のデータではありませんでしたので、120+2=122個の取り出したデータの素性をはっきりさせることができました。
次から、下のような各製品データの様々な要素を取り出していきます。
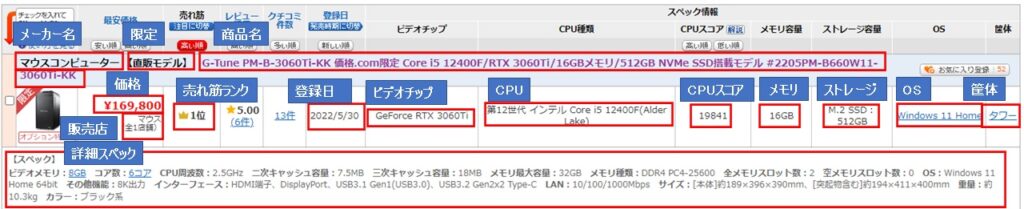
製品データの要素の取り出し方法検討(1)
それでは、各製品データの要素の取り出し方法を確認していきます。ここでは、1ページ目(res[0])の最初の製品のデータ(elems[2]~elems[4])に入っているを取り出していきます。取り出したデータはpandasのDataFrameに入れていくことにします。取り出すデータは汎用性を持たすために、elems[2]、elems[3]、elems[4]は「i=0」として、elems[3*i+2]、elems[3*i+3]、elems[3*i+4]と一般化しておきます。
まず、elems[3*i+2]から確認します。
i = 0
elems[3*i+2]<tr class="tr-border">
<td class="sel alignC ckbtn" rowspan="2"><input name="ChkProductID" onclick="setProductID('K0001446191','V077');"
type="checkbox" value="K0001446191" /></td>
<td class="end checkItem" colspan="15">
<table>
<tr>
<td class="ckitemLink"><a class="ckitanker" href="https://kakaku.com/item/K0001446191/"><span>マウスコンピューター
<span class="dir">【直販モデル】</span> </span>G-Tune PM-B-3060Ti-KK 価格.com限定 Core i5 12400F/RTX
3060Ti/16GBメモリ/512GB NVMe SSD搭載モデル #2205PM-B660W11-3060Ti-KK</a></td>
<td class="addFavoriteBtn"><span class="showNum"
onclick="location.href='https://ssl.kakaku.com/auth/mypage/favorite/entry.aspx?PrdKey=K0001446191&lid=facet_favorite'; return false;"><span
class="txt">お気に入り登録</span><span class="num">52</span></span></td>
</tr>
</table>
</td>
</tr>HTMLの構造が分かりにくければ、VSCodeにHTMLとしてコピーして、SHIFT+ALT+「F」キーでHTMLを階層構造に整形してれるので、そういった機能を使うのもよいと思います。
私の場合は次のようにして、各パーツを取り出していきます。
製品のページへのリンク(URL)
elems[i*3+2].find('a').attrs['href']'https://kakaku.com/item/K0001446191/'
最初の”a”タグを探して、そのhrefパラメータを取得することで取り出せます。
メーカーと限定要素
elems[i*3+2].find('span').text.split()['マウスコンピューター', '【直販モデル】']
最初の”span”タグを探して、内容を取ってきます。”span”タグは2重に重ねられているので、同時に取り出してきます。元のtextデータは下記のようにスペース”\xa0″(ノーブレークスペース)を表す文字コードで区切られているので、split()でスペースで区切って、リストに入れました。そうすることにより、[0]にメーカー名、[1]に限定要素を示す文字列が入ります。ただし、限定要素を持たない可能性がある点は実装の時に注意が必要です。
'マウスコンピューター\xa0【直販モデル】\u3000'
製品名
elems[i*3+2].find('a').text.split('\u3000')[1]'G-Tune PM-B-3060Ti-KK 価格.com限定 Core i5 12400F/RTX 3060Ti/16GBメモリ/512GB NVMe SSD搭載モデル #2205PM-B660W11-3060Ti-KK'
製品名は”a”タグ全体から、”\u3000″(全角スペース)の部分で区切ったリストの2番目を抽出することで取り出すことができました。”a”タグは先ほどのメーカー名や限定要素の部分も含んでいますが、テキストを確認すると、”\u3000″で分割した後半の部分が欲しいところになります。
'マウスコンピューター\xa0【直販モデル】\u3000G-Tune PM-B-3060Ti-KK 価格.com限定 Core i5 12400F/RTX 3060Ti/16GBメモリ/512GB NVMe SSD搭載モデル #2205PM-B660W11-3060Ti-KK'
Pandasに入れてみる
それではここまでの要素をPandasに入れてみます。ここでは、elemsに入っている40製品のデータをまとめてPandasに抽出してみます。
length = (len(elems)-2)//3
df = pd.DataFrame()
df['maker'] = [elems[i*3+2].find('span').text.split()[0] for i in range(length)]
df['limited'] = ["" if len(elems[i*3+2].find('span').text.split())==1 else elems[i*3+2].find('span').text.split()[1] for i in range(length)]
df['product'] = [elems[i*3+2].find('a').text.split('\u3000')[1] for i in range(length)]
df['URL'] = [elems[i*3+2].find('a').attrs['href'] for i in range(length)]まず、最初にlenで製品数を計算します。そして、df = pd.DataFrame()でDataFrameを初期化して、それぞれをDataFrameの’maker’、’limited’、’product’、’URL’の4つのカラムに値をリスト内包表記で入れてやります。そのうち、限定要素は存在しない場合に取り出そうとすると、インデックスエラーになってしまうので、リストの長さを見て、存在しない場合は、空白要素を入れるようにします。
結果は以下のようになります。
df.shape(40, 4)
df.head()| maker | limited | product | URL | |
|---|---|---|---|---|
| 0 | マウスコンピューター | 【直販モデル】 | G-Tune PM-B-3060Ti-KK 価格.com限定 Core i5 12400F/… | https://kakaku.com/item/K0001446191/ |
| 1 | HP | 【直販モデル】 | OMEN by HP 25L Gaming Desktop GT15-0760jp パフォー… | https://kakaku.com/item/K0001444297/ |
| 2 | アプライド | 【直販モデル】 | Katamen Core i7 12700/16GBメモリ/500GB NVMe SSD/R… | https://kakaku.com/item/J0000039215/ |
| 3 | HP | 【直販モデル】 | OMEN by HP 45L Desktop GT22-0781jp 価格.com限定 Co… | https://kakaku.com/item/K0001430518/ |
| 4 | HP | 【直販モデル】 | OMEN by HP 40L Desktop GT21-0780jp 価格.com限定 ハイ… | https://kakaku.com/item/K0001430517/ |
40×4のpd.DataFrameにデータを収納できました。
製品データの要素の取り出し方法検討(2)
引き続き、elems[3]のHTMLを解析して一般式でelems[3*i+3]のデータ抽出方法を検討してみます。elems[3]で取り出したHTMLは下のようになっています。整形はVScodeで行っています。ここには最低価格と、グラフィックボードやCPU、メモリ容量、ストレージ容量など価格を決定づける重要なパラメータがあります。class属性を細かく設定してくれているので、要素の抽出はclass属性を指定してfindでできそうです。
<tr class="tr-border">
<td class="alignC"><a class="withIcnLimited" href="https://kakaku.com/item/K0001446191/"><span
class="withIcnLimitedBox"><span class="icnLimited">限定</span></span><img
alt="G-Tune PM-B-3060Ti-KK 価格.com限定 Core i5 12400F/RTX 3060Ti/16GBメモリ/512GB NVMe SSD搭載モデル #2205PM-B660W11-3060Ti-KK"
height="60"
onerror="this.src='https://img1.kakaku.k-img.com/images/productimage/m/nowprinting.gif';this.onerror=null"
onload="resizeImageFix(this,80,60)"
src="https://img1.kakaku.k-img.com/images/productimage/m/K0001446191.jpg" width="80" /></a><span
class="dFeatureIcn">オプション特典付</span></td>
<td class="td-price">
<ul>
<li class="pryen"><a href="https://kakaku.com/item/K0001446191/">¥169,800</a></li>
<li class="prshop">マウス<br />(全1店舗)</li>
</ul>
</td>
<td class="swrank1" style="display:none;"><span class="withRankIcn fontBold">1位</span></td>
<td class="swrank2"><span class="withRankIcn fontBold">1位</span></td>
<td><span class="withStarIcn fontBold">5.00</span><br /><a
href="https://review.kakaku.com/review/K0001446191/#tab">(6件)</a></td>
<td><a href="https://bbs.kakaku.com/bbs/K0001446191/#tab">13件</a></td>
<td class="swdate1">2022/5/30 </td>
<td class="swdate2" style="display:none;">2022/5/30</td>
<td>GeForce RTX 3060Ti</td>
<td>第12世代 インテル Core i5 12400F(Alder Lake)</td>
<td>19841</td>
<td>16GB</td>
<td>M.2 SSD:512GB</td>
<td><span class="sortBox"><a href="/pc/gaming-pc/itemlist.aspx?pdf_Spec107=21&pdf_vi=d"
onclick="FSNPopup.open(this, 0, 2);return false;">Windows 11 Home</a><span class="variBlnHide"
id="vbcnavK0001446191_Spec107"></span></span></td>
<td class="end"><span class="sortBox"><a href="/pc/gaming-pc/itemlist.aspx?pdf_Spec101=2&pdf_vi=d"
onclick="FSNPopup.open(this, 0, 3);return false;">タワー</a><span class="variBlnHide"
id="vbcnavK0001446191_Spec101"></span></span></td>
</tr>最安価格
class属性”pryen”を探します。そのまま、このまま要素を取り出しても、‘¥169,800’のように「¥」マークと、桁区切りの「,」が入った文字列になります。ここから余分なものを削除して、数値型で抽出できるようにします。まず、replaceでコンマを空文字列で置換することで削除します。さらに先頭の円マークを削除するために、2文字目以降をスライスで切り取ります。全体をintで整数型に変換します。
i = 0
int(elems[i*3+3].find(class_="pryen").text.replace(',','')[1:])169800
販売店
class属性”prshop”を探します。
elems[i*3+3].find(class_="prshop").text'マウス(全1店舗)'
注目ランク、売上ランク、登録日、発売日
注目ランクと売上ランク、登録日、発売日はHTMLソースを見ると、それぞれクラス属性”swrank1″と”swrank2″、”swdate1″、”swdate2″を探せば良さそうです。ただし、日付データは’2022/5/30\xa0‘のように末尾にノーブレークスペースが入っているので、splitで分割して[0]を取り出して、削除します。
# 注目ランク
elems[i*3+3].find(class_="swrank1").text'1位'
# 売上ランク
elems[i*3+3].find(class_="swrank2").text'1位'
日付の途中にスペースがあってうまく日付を抽出できないので再結合するように修正(2022/10/14)
elems[i*3+3].find(class_=”swdate1″).text.split()[0]
↓
“”.join(elems[i*3+3].find(class_=”swdate1″).text.split())
# 登録日
"".join(elems[i*3+3].find(class_="swdate1").text.split())'2022/5/30'
# 発売日
"".join(elems[i*3+3].find(class_="swdate2").text.split())'2022/5/30'
グラフィックボード、CPU、CPUスコア、メモリ容量、ストレージ、OS、筐体
グラフィックボード、CPU、CPUスコア、メモリ容量、ストレージ、OS、筐体については、class属性がついていない項目がありますので、tdタグで取得することにします。find_allでtdタグすべてをリストで取得して確認すると、グラフィックボードは[8]、CPUは[9]、CPUスコアは[10]、メモリ容量は[11]、ストレージは[12]、OSは[13]、筐体は[14]で要素を取ってこれるようです。こうした取り方は新しくテーブルに項目が増えたりすると、ずれてしまうので、ホームページが更新した際は修正が必要になります。。。上手な人はどうやっているのか気になります。
# Graphics board
elems[i*3+3].find_all("td")[8].text'GeForce RTX 3060Ti'
# CPU
elems[i*3+3].find_all("td")[9].text'第12世代 インテル Core i5 12400F(Alder Lake)'
CPUスコアの一部が欠損値になっていて、intに変換するところでエラーが出たので、欠損値を0で置き換えるように修正。具体的にint(cpuスコア or 0)として、cpuスコアが欠損値のときは0が入るようにした(2022/10/14)
int(elems[i*3+3].find_all(“td”)[10].text)
↓
int(“”.join(elems[i*3+3].find_all(“td”)[10].text.split()) or 0)
# CPUスコア
int("".join(elems[i*3+3].find_all("td")[10].text.split()) or 0)19841
# メモリ容量
elems[i*3+3].find_all("td")[11].text'16GB'
# ストレージ
elems[i*3+3].find_all("td")[12].text['M.2 SSD', '512GB']
# OS
elems[i*3+3].find_all("td")[13].text'Windows 11 Home'
# 筐体
elems[i*3+3].find_all("td")[14].text'タワー'
上記で一通りのデータが取れるようになりました。
製品データの要素の取り出し方法検討(3)
最後にelems[4]のHTMLを解析して一般式でelems[3*i+4]のデータ抽出をします。
詳細スペック
HTMLを確認します。ここには様々な詳細スペックデータが入っています。この値は将来参照する可能性はありますが、全部は使わないので、必要な時にデータを取り出せるように、テキスト内容を抽出しておきます。
<tr class="tr-border">
<td class="end ckitemSpec" colspan="16">
<div class="ckitemSpecInnr"><span class="ckitemSpecInnrTtl">【スペック】</span><br /><span
class="specType">ビデオメモリ:</span><span class="sortBox"><span class="typeClk"
onclick="FSNPopup.open(this, 0, 0);return false;">8GB</span><span class="variBlnHide"
id="vbcnavK0001446191_Spec317"></span></span> <span class="specType">コア数:</span><span
class="sortBox"><a href="/pc/gaming-pc/itemlist.aspx?pdf_Spec310=6&pdf_vi=d"
onclick="FSNPopup.open(this, 0, 1);return false;">6コア</a><span class="variBlnHide"
id="vbcnavK0001446191_Spec310"></span></span> <span class="specType">CPU周波数:</span>2.5GHz <span
class="specType">二次キャッシュ容量:</span>7.5MB <span class="specType">三次キャッシュ容量:</span>18MB <span
class="specType">メモリ最大容量:</span>32GB <span class="specType">メモリ種類:</span>DDR4 PC4-25600 <span
class="specType">全メモリスロット数:</span>2 <span class="specType">空メモリスロット数:</span>0 <span
class="specType">OS:</span>Windows 11 Home 64bit <span class="specType">その他機能:</span>8K出力 <span
class="specType">インターフェース:</span>HDMI端子、DisplayPort、USB3.1 Gen1(USB3.0)、USB3.2 Gen2x2 Type-C <span
class="specType">LAN:</span>10/100/1000Mbps <span
class="specType">サイズ:</span>[本体]約189×396×390mm、[突起物含む]約194×411×400mm <span
class="specType">重量:</span>約10.3kg <span class="specType">カラー:</span>ブラック系 </div>
</td>
</tr>まず、試しにタグ全体をテキストで取得してみます。
i = 0
elems[i*3+4].text'\n【スペック】ビデオメモリ:8GB\u3000コア数:6コア\u3000CPU周波数:2.5GHz\u3000二次キャッシュ容量:7.5MB\u3000三次キャッシュ容量:18MB\u3000メモリ最大容量:32GB\u3000メモリ種類:DDR4 PC4-25600\u3000全メモリスロット数:2\u3000空メモリスロット数:0\u3000OS:Windows 11 Home 64bit\u3000その他機能:8K出力\u3000インターフェース:HDMI端子、DisplayPort、USB3.1 Gen1(USB3.0)、USB3.2 Gen2x2 Type-C\u3000LAN:10/100/1000Mbps\u3000サイズ:[本体]約189×396×390mm、[突起物含む]約194×411×400mm\u3000重量:約10.3kg\u3000カラー:ブラック系\u3000\n'
スペックの各パラメータは”\u3000″の文字コードの全角スペースで区切られていることが分かります。あとは不要な部分を削除したり微修正をすることで、下のように各スペックのパラーメータをリストで取り出すことができます。
i = 0
elems[i*3+4].text.replace("\n","").replace("【スペック】","").split("\u3000")[:-1]['ビデオメモリ:8GB', 'コア数:6コア', 'CPU周波数:2.5GHz', '二次キャッシュ容量:7.5MB', '三次キャッシュ容量:18MB', 'メモリ最大容量:32GB', 'メモリ種類:DDR4 PC4-25600', '全メモリスロット数:2', '空メモリスロット数:0', 'OS:Windows 11 Home 64bit', 'その他機能:8K出力', 'インターフェース:HDMI端子、DisplayPort、USB3.1 Gen1(USB3.0)、USB3.2 Gen2x2 Type-C', 'LAN:10/100/1000Mbps', 'サイズ:[本体]約189×396×390mm、[突起物含む]約194×411×400mm', '重量:約10.3kg', 'カラー:ブラック系']
ここまでで全データをとれたので、次にPandasにデータを入れていくことにします。
Pandasへのデータの取り出し
ここまでの結果をPandas に出力してみます。Webページの解析のところでは、最初の1ページ目の結果からデータを取得してみましたが、今回はその他のページについても取得してみます。
製品データの全要素取得
ページごとに出力したDataFrameをPandasのconcatでまとめています。それぞれの製品データの要素の取得は、上で解析した結果をもとに取得を行っています。(2022/10/14コード更新)
# DataFrameの初期化
gamingPC = pd.DataFrame()
# DataFrameの要素を取得し、つなぎ合わせる
for page in range(len(res)):
soup = BeautifulSoup(res[page].text,"lxml")
elems = soup.find_all(class_="tr-border")
length = (len(elems)-2)//3
df = pd.DataFrame()
df['maker'] = [elems[i*3+2].find('span').text.split()[0] for i in range(length)]
df['limited'] = ["" if len(elems[i*3+2].find('span').text.split())==1 else elems[i*3+2].find('span').text.split()[1] for i in range(length)]
df['product'] = [elems[i*3+2].find('a').text.split('\u3000')[1] for i in range(length)]
df['price'] = [int(elems[i*3+3].find(class_="pryen").text.replace(',','')[1:]) for i in range(length)]
df['shop'] = [elems[i*3+3].find(class_="prshop").text for i in range(length)]
df['at_rank'] = [int(elems[i*3+3].find(class_="swrank1").text.replace('位','').replace('-','0')) for i in range(length)]
df['sales_rank'] = [int(elems[i*3+3].find(class_="swrank2").text.replace('位','').replace('-','0')) for i in range(length)]
df['reg_date'] = ["".join(elems[i*3+3].find(class_="swdate1").text.split()) for i in range(length)]
df['release_date'] = ["".join(elems[i*3+3].find(class_="swdate2").text.split()) for i in range(length)]
df['graphics_board'] = [elems[i*3+3].find_all("td")[8].text for i in range(length)]
df['CPU'] = [elems[i*3+3].find_all("td")[9].text for i in range(length)]
df['CPU_score'] = [int("".join(elems[i*3+3].find_all("td")[10].text.split()) or 0) for i in range(length)]
df['memory'] = [elems[i*3+3].find_all("td")[11].text for i in range(length)]
df['storage'] = [elems[i*3+3].find_all("td")[12].text for i in range(length)]
df['OS'] = [elems[i*3+3].find_all("td")[13].text for i in range(length)]
df['body'] = [elems[i*3+3].find_all("td")[14].text for i in range(length)]
df['spec'] = [elems[i*3+4].text.replace("\n","").replace("【スペック】","").split("\u3000")[:-1] for i in range(length)]
df['product_url'] = [elems[i*3+2].find('a').attrs['href'] for i in range(length)]
gamingPC = pd.concat([gamingPC, df], axis=0)
# インデックスの再設定
gamingPC = gamingPC.reset_index(drop=True)作成した”gamingPC”のDataFrameの内容を結果を確認してみます。エラーなく719行×18カラムのデータを取得できました。
gamingPC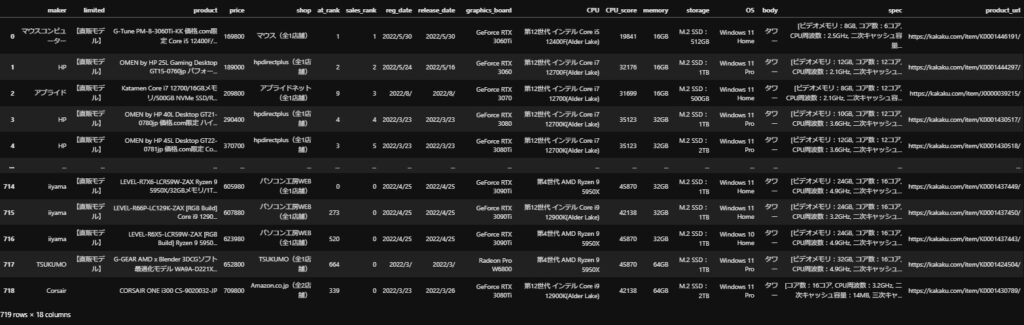
Pandasデータの保存
作ったDataFrameを再利用するために、DataFrameのファイルに保存します。ここでは、DataFrameを丸ごと保存できる”pickle”というPython用のバイナリファイル形式のデータとして保存します。そうすることにより、次回はそのデータをPandasで呼び出すことで、表の解析などをすぐに続けることができます。
# pickle形式でDataFrameのデータを保存
gamingPC.to_pickle("gamingPC_data202208_1.pickle")上のコマンドでgamingPCのDataFrameの内容を、カレントディレクトリ直下にの”gamingPC_data202208_1.pickle”というファイルに保存しました。
データの呼び出し
後日、データを呼び出すときは下のように”read_pickle”で保存したpickleデータのファイル名を指定するだけでOKです。
import pandas as pd
gamingPC = pd.read_pickle("gamingPC_data202208_1.pickle")前編のまとめ
- スクレイピングしたいサイトのページの構造を確認する。
- 必要なデータの入ったページをrequestsで取得する。
- 取得したデータからbeautifulsoupで要素の取り出し方を検討する。
- 全データを取り出して、Pandasに入れる。
- PandasのDataFrameをローカルファイルに保存する。
長くなったので、後半は後日記載します。ここまででデータは取得できました。後半ではスペックと価格との相関を分かりやすいようにグラフにしていきます。



コメント