

Stable Diffusionを使おうと思ったが、どこをどう設定したらよいか分からない方に向けてStable Diffusionで画像生成を楽しむための最低限の設定方法を解説します。これからStable Diffusionで画像生成してみたい方はご参考ください。(ローカル環境へのセットアップ方法の解説はこちら)
※本記事は2023年7月現在の情報に基づき作成しています。(情報としては古いですがアーカイブとして残しています。)
画像生成の基本
画像生成の基本は「モデル(checkpoint)」と「プロンプト」です。まずは、その2つを正しく選ぶことが重要です。
モデル(checkpoint)とは
モデル(checkpoint)は多くのものが公開されています。例えば、同じプロンプトで生成した場合でも、下のようにまったく違って画像が生成します。例えば、アニメ絵のようなものを出したいなら、meinamixを、また、アジア系の美女を出したいときはbraBeautifulRealisticを使うなど、目的に応じたモデルを使うことが重要です。

少し詳しく説明すると、「v1-5 pruned emaonly」はStable Diffusionで現在主流の多くのモデルのベースとなっているモデルですが、学習に用いているものは、海外の写真やイラストが中心なので、頑張ってプロンプトを工夫しても、日本のアニメイラストのような画像や、アジア人の美女の画像を生成するのは難しいです。一方で特化モデルはある傾向をもった多くの画像から学習されているので、それぞれ特徴的な画像を生成することができます。よって、目的に沿ったモデルを探すことが必要です。
モデルの特徴は実際にそのモデルを使って画像を生成してみるか、モデルの配布サイトや画像投稿サイトでの例を参考すると良いと思います。ただし、モデルによっては利用に制限があったり、違法にアップロードされているものもありますので、注意して自己責任で健全な使用を心がけましょう。
プロンプトとは
プロンプトは実際に生成したい画像の特徴をStable Diffusionに指令する役割を持ちます。プロンプトは一般的には「英単語」や「英文」を用います。プロンプトには通常のプロンプトと、ネガティブプロンプトがあります。通常のプロンプトには生成したい画像の特徴を指定します。一方、ネガティブプロンプトには生成したくない画像の特徴を指定します。プロンプトはモデルと密接に結びついていて、実際に生成する画像はプロンプトとモデルを掛け合わせた結果が画像として生成します。
例えば、同じ1girlというプロンプトに対して、あるモデルでは西洋系の女性が、また、別のモデルはアニメの女の子が、または別のモデルではアジア系の女性が出力することが多くなります。プロンプトは複数のプロンプトをうまく組み合わせることにより、モデルの持つ潜在的な可能性を引き出すことができます。ただし、プロンプトはStable Diffusionの画像生成の推論段階で確率的に処理されるため、必ず入力したプロンプト通りに画像が生成するわけではないことには注意が必要です。
プロンプトの作成方法
プロンプトは独特な言い回しがあります。慣れないうちは他の人の生成した画像のプロンプトを参考にするか、プロンプト集などを参考にするのが良いと思います。プロンプトは「呪文」と呼ばれていています。「Stable Diffusionのプロンプト集」や「呪文集」などで検索するといろいろなプロンプトを検索できます。
プロンプトでは主に以下のようなものを自由に指定します。決まった正解はないので、いろいろ想像力を働かせて自由にプロンプトを作ってみましょう。
・生成対象(例:1girl, 1boy, cute lady, cat, no human, office worker, apple 等)
・見た目(例:tall、beautiful face、black hair 等)
・服装(例:white shirt、business suit、leather jacket、Japanese kimono 等)
・表情(例:happy smile、sad、angry 等)
・背景(例:street、white background、office、bus stop 等)
・構図(例:close up、full body、over head spot 等)
・ポーズ(例:standing、looking at viewer、sitting 等)
・画質(例:high quality、monochrome、highly detail、4K 等)
・画風(例:illustration, photo, painting 等)
等々
ネガティブプロンプトの作成方法
ネガティブプロンプトでは画像の崩れや不適切な画像が生成しないようなキーワードをプロンプトとして指定します。また、「Textual Inversion」(※)として「EasyNegative」がセットされている場合、ネガティブプロンプトに「EasyNegative」を指定するだけで、画像の品質が向上します。ネガティブプロンプトは他の人の使っているネガティブプロンプトを参考にして自分なりの定型ネガティブプロンプトをベースとして持っておくと便利です。
※Textual Inversion(ちょっと難しい説明) 特定の概念をキーワードパッケージとして埋め込んだ言葉を学習させる手法。例えば、「EasyNegative」には低品質の画像を表す情報が学習で埋め込まれているので、これをネガティブプロンプトに入れることにより、画像の品質が向上します。Textual Inversionの学習結果を使うには、ダウンロードした学習済みモデルを、modelsのembeddingsのフォルダの中にセットして、プロンプトに指定することで効果を発揮します。詳しくは後日記事にします。
画像生成をしてみる
例として、「制服を着たポニーテールの女子高校生がバス停に立っているアニメイラスト」画像を生成してみます。例えば条件は以下のように設定します。
モード:txt2img
モデル(checkpoint):meinamix
サンプラー:DPM++SDE Karras
CFGスケール:7
ステップ数:40
画像サイズ(横x縦):600×800
プロンプト:(illustration:1.0), masterpiece, best quality, 1girl, solo, smile, pure face, ponytail, school uniform, looking at veiwer, flat chest, standing, outdoor, bus stop
ネガティブプロンプト:EasyNegative, nsfw, (worst quality, low quality:1.4), (depth of field, blurry, bokeh:1.5), (greyscale, monochrome:1.0), multiple views, text, title, logo, signature, (tooth, lip, nose, 3d, realistic:1.0), dutch angle,(cropped:1.4), text, title, signature, logo,( loli:1.2)
seed:-1(ランダム)
プロンプトでは記述したい女の子のパラメーターを自由に設計しました。
パラメーターの詳細な説明
モードはtxt2imgを選択し、テキストから画像を生成します。モデルはアニメ絵系のモデルのmeinamixを使いました。サンプラーはmeinamixの推奨サンプラーの一つDPM++SDE を使いました。画像サイズは大きい方が細かい部分まで書き込んでくれることが多いので、800×600に設定しています。生成できる画像の大きさはGPUの容量などできまりますが、あまりサイズを大きくしすぎると、1枚に複数人が入ってくることがありますので、適度な大きさにすることが必要です。
ステップ数は40に設定しましたが、20くらいでも大丈夫かもしれません。CFGスケールは大きいとプロンプトに忠実に従う画像を生成しますが、大きくしすぎると、不自然な画像になります。ここではデフォルトの7に設定しました。
シードは-1に設定しました。シードが同じだと毎回同じ画像が生成します。シードは1以上の整数で設定しますが、-1にすると生成を開始するたびに毎回ランダムでシードを変えてくれるので、同じプロンプトでも異なる画像ができます。もし、毎回同じ画像にしたい場合は、シードを固定の正の整数にします。ちなみに、バッチ数(batch count)で生成する画像の枚数を設定できるので、もし、1度に複数の画像を生成したい場合はバッチ数を増やしましょう。
Stable Diffusion WebUIの設定画面
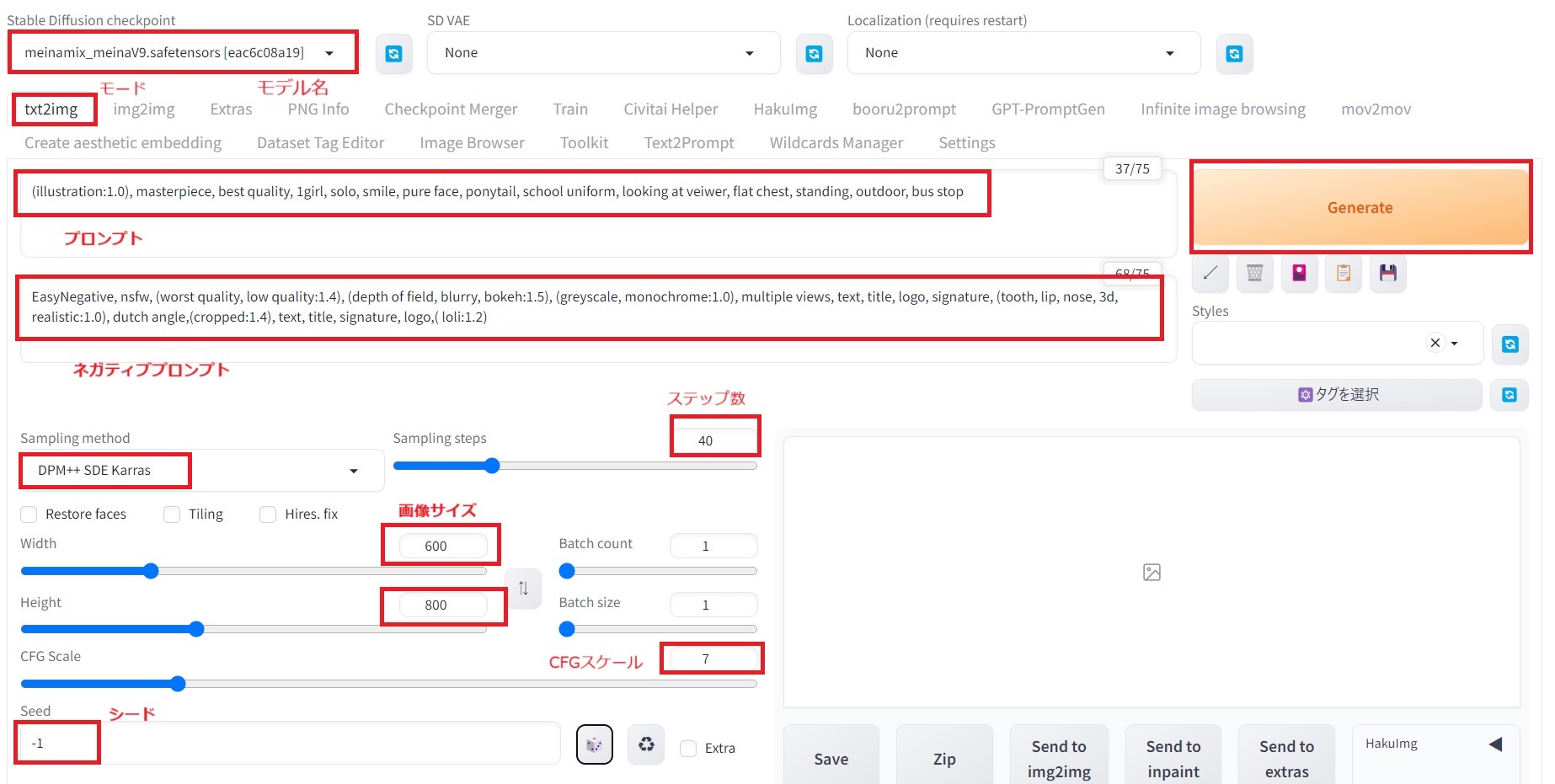
上記の設定をしたら、オレンジ色の生成(Generation)ボタンを押すと画像が生成します。
生成画像例(実際はシードが毎回異なるので、違う画像を生成する)

Stable Diffusionでのイラスト生成のポイント
ここでStable Diffusionを始めたばかりの方々にイラスト生成のポイントを5点まとめます。
・モデル(checkpoint)をしっかり選ぶ。
・プロンプトは最初は他の方のプロンプトを改造するところから始める。
・同じプロンプトでもできる画像が変わるので、複数枚出して良いものを使う。
・イラスト生成自体は簡単だが良いイラストを作るのにはいろいろ研究が必要。
・Stable Diffusionには多くの便利な拡張機能があるので、もし、思ったような画像ができない場合は、拡張機能を調べて使ってみる。
このブログでもいろいろなStable Diffusionの情報は発信しているので、ご参考いただき、うまくStable Diffusionを使いこなしていっていただければと思います。

