

mov2movで動画を作成する場合、なかなか安定した動画を作るのが難しいという問題点がありました。動きに合わせて生成される動画が一定にならず、結構カチャカチャした動きが多くなってしまいます。そこで、先日ControlNetに実装されたreference onlyを適用して動画を作成してみました。その結果、生成する画像が安定し、割とスムーズなムービーが生成しました。
準備
reference onlyとmov2movについては、過去のブログで扱っていますので、そちらをご覧ください。

mov2movでTiktokの動画を生成する:Stable Diffusion WebUI拡張機能
mov2movでAI美女に踊らせてみました。元動画は私(おっさん)ですが、Stable Diffusionのmov2movにかかると、そんな私でも美女の踊ってみた動画が作れます。おっさんを美女に変換するという少し無茶なことをやっていますので、ちらつきが大きいです。
happy-shibusawake.com
2023.04.30

reference only Controlで学習なしで好きなキャラを出す:Stable Diffusion ControlNet拡張機能
先日、ControlNetに新しく追加されたReference-onlyを使うと、簡単に好きなキャラクターの画像を生成することができます。これまで、出したいキャラクターを出そうと思ったら、LoRAなどで学習させて、LoRAモデルを作成し、それを使って生成するのが王道でした。今回、LoRAを使わずに好きなキャラクターを生成してみます。
happy-shibusawake.com
2023.05.16
mov2movの設定
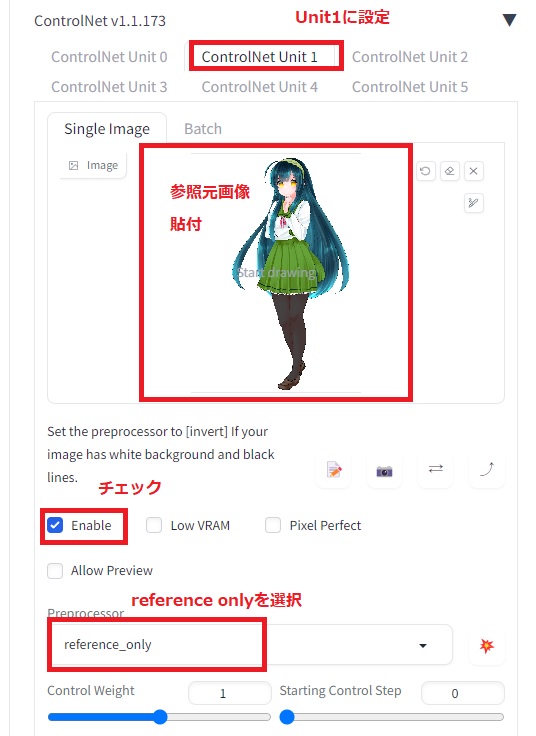
今回、元動画はpixabay様の女性がダンスをしているCGを使わせていただきました。また、reference onlyで参照する画像は東北ずん子様を使わせていただきました。
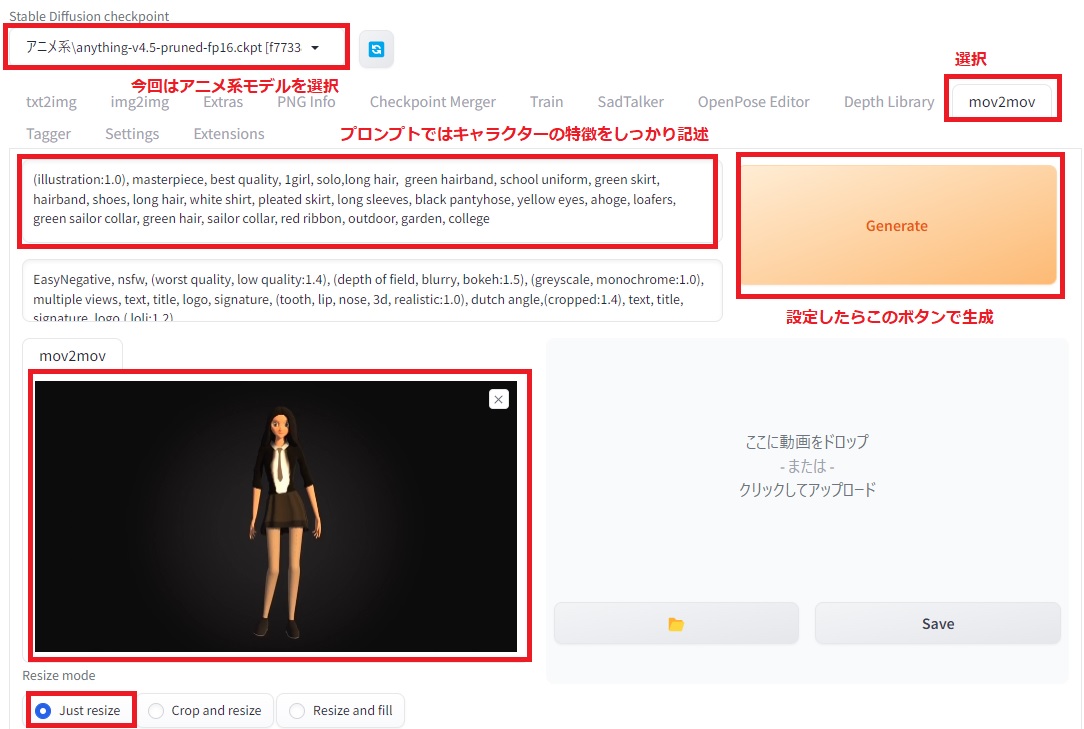
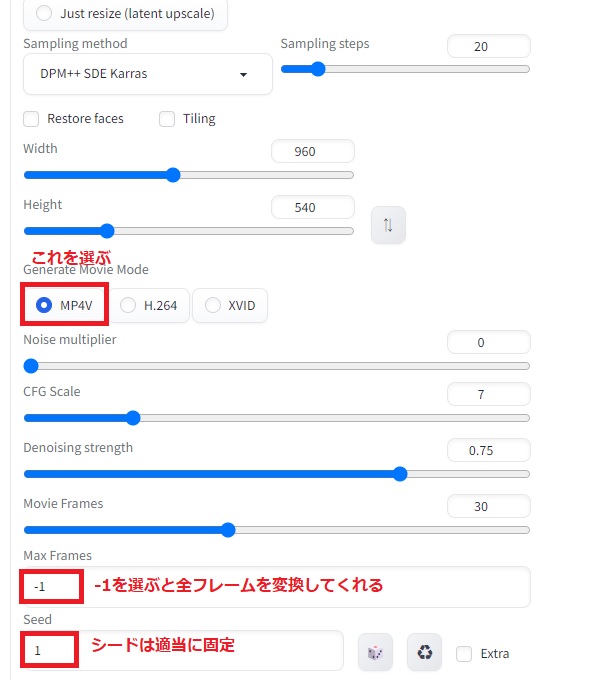
mov2movの設定は以下の通りです。
プロンプトでは生成するずん子様の特徴をとらえた記述をします。色などをちゃんと書く方が動画が安定しやすいです。
プロンプト: (illustration:1.0), masterpiece, best quality, 1girl, solo,long hair, green hairband, school uniform, green skirt, hairband, shoes, long hair, white shirt, pleated skirt, long sleeves, black pantyhose, yellow eyes, ahoge, loafers, green sailor collar, green hair, sailor collar, red ribbon, outdoor, garden, college ネガティブプロンプト: EasyNegative, nsfw, (worst quality, low quality:1.4), (depth of field, blurry, bokeh:1.5), (greyscale, monochrome:1.0), multiple views, text, title, logo, signature, (tooth, lip, nose, 3d, realistic:1.0), dutch angle,(cropped:1.4), text, title, signature, logo,( loli:1.2)
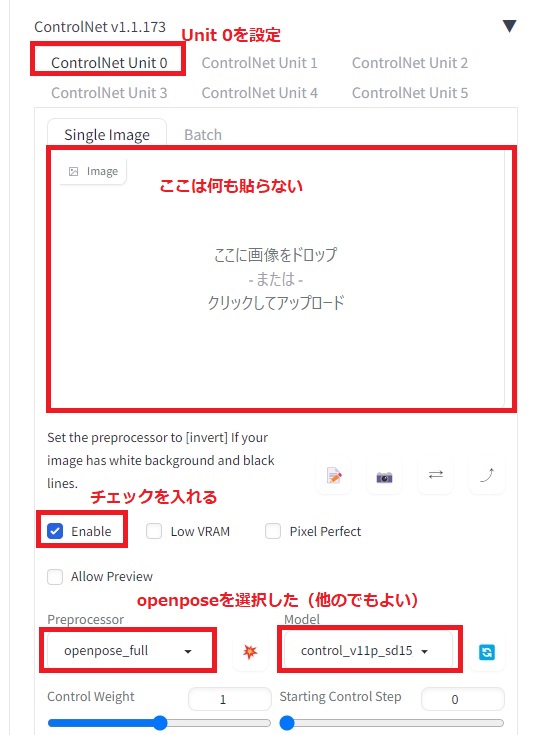
その他の設定は以下の通り。ControlNetではUnit0でopenpose-fullを使い、Unit1でreference onlyを使っています。Unit0は他のモデルを使っても構いません。ここではポーズの生成が得意なopenposeを使っていますが、cannyを使って元動画に寄せていくこともできます。
mov2mov結果
比較的安定した動画ができました。reference onlyはばらつきを抑制するフィルターのような効果もあるような気がします。
音楽は魔王魂様の「サバイバー38」を使わせていただきました。


コメント