

スクレイピングの必須のPythonの正規表現reを総復習して、早見表を作ってみました。これで忘れてもすぐに思い出せます。PDFでダウンロード可能なので、よかったら参考にしてください。
※本記事は2022年6月現在の情報に基づき作成しています。(情報としては古いですがアーカイブとして残しています。)
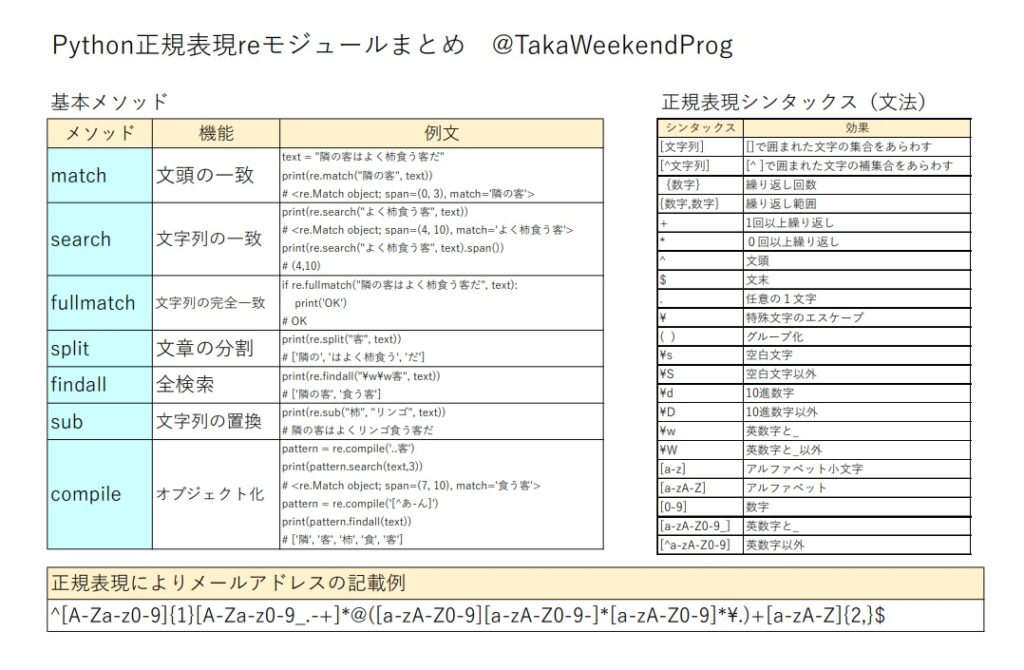
正規表現reモジュールのまとめ
正規表現は文字列の中から特定のパターン(正規表現)に一致する部分を探し出すモジュールで、Pythonに標準に搭載されています。正規表現を使うことで、テキストの検索や加工、webスクレイピングなどを効率的に狙った通りにできるようになります。
便利そうだと思うreモジュールのコマンドをまとめました。PDF版もダウンロードできるので、テキストの処理をするときはぜひご参考にください。
Python正規表現reモジュールまとめ(PDFダウンロード)
何ができるのか、イメージできない方は、下の説明に例文もありますので、そちらをご覧ください。
基本メソッド
ここでは、メソッドとしてのreモジュールの使用方法を見ていきます。
文頭の一致(match)
matchは「文頭」から一致するか調べます。
text = "隣の客はよく柿食う客だ"
# 一致する場合
result = re.match("隣の客", text)
print(result) # <re.Match object; span=(0, 3), match='隣の客'>
# 各情報を出力
print(result.start()) # 0
print(result.end()) # 3
print(result.span()) # (0, 3)
print(result.group()) # 隣の客
# 一致しない場合
result = re.match("よく柿食う客", text)
print(result) # None文字列の一致(search)
matchと似ていますがsearchは文頭でも文中でも文章のどこかで一致するか調べます。
text = "隣の客はよく柿食う客だ"
# 文頭で一致
result = re.search("隣の客", text)
print(result) # <re.Match object; span=(0, 3), match='隣の客'>
# 文中で一致
result = re.search("よく柿食う客", text)
print(result) # <re.Match object; span=(4, 10), match='よく柿食う客'>
# 各情報を出力
print(result.start()) # 4
print(result.end()) # 10
print(result.span()) # (4,10)
print(result.group()) # よく柿食う客文字列の完全一致(fullmatch)
fullmatchでは文章(文字列)が完全に一致しない場合はnoneを返します。
text = "隣の客はよく柿食う客だ"
result = re.fullmatch("隣の客", text)
print(result) # None
result = re.fullmatch("隣の客はよく柿食う客だ", text)
print(result) # <re.Match object; span=(0, 11), match='隣の客はよく柿食う客だ'>文章の分割(split)
splitは文章を指定したキーワードで分割し、分割された文字列のリストを返します。下の例では「客」で分割をしています。
text = "隣の客はよく柿食う客だ"
result = re.split("客", text)
print(result) # ['隣の', 'はよく柿食う', 'だ']全検索(findall)
findallは文章中で一致する文字列をすべて抽出してリストで返します。「\w」(下の表記ではバックスラッシュw(\w))は任意の1文字を表す正規表現のシンタックス(文法)で、\w\wで任意の2文字を表しています。(正規表現のシンタックスについては、下で説明します。)
text = "隣の客はよく柿食う客だ"
result = re.findall("\w\w客", text)
print(result) # ['隣の客', '食う客']文字列の置換(sub)
subは文字列を置換できます。1か所でも2か所以上でもOKです。下の例では、「柿」を「リンゴ」で置換し、また、「客」を「猫」で置換しています。
text = "隣の客はよく柿食う客だ"
result = re.sub("柿", "リンゴ", text)
print(result) # 隣の客はよくリンゴ食う客だ
result = re.sub("客", "猫", text)
print(result) # 隣の猫はよく柿食う猫だ正規表現のシンタックス(文法)
ここからは、具体的に正規表現のシンタックスを見ていきます。シンタックスを組み合わせることで、文字列のマッチングの幅が大きく広がります。
正規表現のシンタックスとは?メールアドレスのルールの正規表現
文字列に特殊文字を組み合わせて、マッチングさせる文字列のルールです。正規表現のルールを覚えると複雑な文字列のマッチングを行うことができます。
例えば、メールアドレスかどうか判別するためのルールを考えてみます。メールアドレスは以下のようにローカル部とドメイン部からなります。
ローカル部@ドメイン部
ローカル部で使える文字は、大小のアルファベット、数字、一部の記号(!#$%&’*+-/=?^_`{|}~)で、また、ドット(.)は文頭、文末以外で連続しない場合は使えるそうです。
ドメイン部はアルファベット、数字、ハイフン(-)からなるサブドメインをドット(.)でつないだ形式になっているそうです。(Wikiページの要約)
上記を踏まえて、メールアドレスとして、以下の条件を満たすような正規表現を書いていきます。
- ローカル部の先頭の文字は英数字。
- ローカル部は先頭の文字を含めて1文字以上で、先頭以外は英数字に加えて、アンダーバー(_)、コンマ(.)、ハイフン(-)、プラス(+)も使える。
- ローカル部とドメイン部はアットマーク(@)で区切る。
- ドメイン名の先頭の文字は英数字。
- ドメイン部は先頭以外では上記に加え、ハイフン(-)も使える。
- ドメイン名の末尾は文字は英数字。
- ドメイン名はコンマ(.)で区切る。
- 末尾のトップドメイン名は2文字以上のアルファベット。
^[A-Za-z0-9]{1}[A-Za-z0-9_.-+]*@([a-zA-Z0-9][a-zA-Z0-9-]*[a-zA-Z0-9]*\.)+[a-zA-Z]{2,}$上記の通りになります。まずは、様々な表記方法を見てから、最後に上の正規表現を紐解きます。
正規表現のシンタックス一覧
[文字列]:文字の集合
[]で囲まれた文字の集合を示します。例えば[AB]ならAかBの文字を表します。さらに[a-z]のようにハイフン(-)でつなぐと、範囲を示し、[a-z]は小文字のa~zを表し、[A-Z]は大文字のA~Zを、[0-9]は数字の0~9を表します。つまり、[A-Za-z0-9]は英数字を示し、[A-Za-z0-9_.-+]は英数字と「_.-+」の記号を示します。
下の例では、'[A-Z]at’で文字列からCat、Bat、Hatを探してくれます。
text = 'Dog Cat Pig Bat Hat'
result = re.findall('[A-Z]at',text)
print(result) # ['Cat', 'Bat', 'Hat']なお、コンマ(.)やプラス(+)などは正規表現の中では特殊な意味を持ちますが、[]の中にある場合は、ただの文字として扱われます。
[^文字列] : 文字の集合(補集合)
[]の中の先頭に^が来ると、続く文字列の集合の補集合を表します。つまり、[^a-z]でa~zではないことを示します。下の例では、先頭がアルファベットでない場合にマッチングします。
print(re.match('[^a-zA-Z]','abcde')) # None
print(re.match('[^a-zA-Z]','5bcde')) # <re.Match object; span=(0, 1), match='5'>{数字}:繰り返し回数
{}で直前の文字の繰り返し回数を示します。例えば、[A-Z]{2}なら、A~Zのアルファベット2文字を表します。例えば、下の例だと文字列の中でa~zのアルファベットが3文字つながっているghiとpqsを抽出します。
text = 'ab2de3ghi4kl5no6pqs7tu8vw9x0y'
result = re.findall('[a-z]{3}',text)
print(result) # ['ghi', 'pqs']{数字,数字}:繰り返し範囲
{}を使って繰り返しの範囲を表すことができます。下の例では7個の「o」の範囲に入る時だけマッチします。{3,}としたら3回以上、{,10}としたら10回以下などと、上限や下限を示さなくてもよいです。
text = 'Hellooooooo!'
print(re.search('Hell[o]{6,9}!', text)) # <re.Match object; span=(0, 12), match='Hellooooooo!'>
print(re.search('Hell[o]{8,10}!', text)) # None
print(re.search('Hell[o]{2,4}!', text)) # None+、*:繰り返し
それぞれ直前のブロックを「+」は1回以上繰り返し、「*」は0回以上繰り返します(つまり0回でもよい)。下の例では一番下の例だけマッチングしませんでした。「+」の場合は必ず1回以上繰り返す必要がありますが、「*」の場合はなくても、出てこなくても構いません。
print(re.search('ab[a-z]*fg', 'abcdefg')) # <re.Match object; span=(0, 7), match='abcdefg'>
print(re.search('ab[a-z]*fg', 'abfg')) # <re.Match object; span=(0, 4), match='abfg'>
print(re.search('ab[a-z]+fg', 'abcdefg')) # <re.Match object; span=(0, 7), match='abcdefg'>
print(re.search('ab[a-z]+fg', 'abfg')) # None^と$:文頭と文末
^は文頭を示します。$は文末を示します。下に使用例を示します。^は単語の前に、$は単語の後ろにつけます。
# 先頭が一致するか確認
print(re.search('^[a-d]', 'apple')) # <re.Match object; span=(0, 1), match='a'>
print(re.search('^[a-d]', 'kid')) # None
# 末尾が一致するか確認
print(re.search('[a-d]$', 'apple')) # None
print(re.search('[a-d]$', 'kid')) # <re.Match object; span=(2, 3), match='d'>コンマ(.) : 任意の1文字
コンマ(.)は任意の1文字を示します。下の例のように文字数と位置が合うと、マッチングします。位置が違ったり、文字数が違うと、マッチせず、Noneを返します。
print(re.match('.a.','cat')) # <re.Match object; span=(0, 3), match='cat'>
print(re.match('.c.','cat')) # None
print(re.match('.a.','ca')) # None\ : 特殊文字のエスケープ
上で示したようなアスタリスク(*)やコンマ(.)や+、*といった正規表現で意味のある特殊記号はそのままだと、正規表現の中で使えませんので、前に\をつけてエスケープします。
print(re.match('\*bc','*bc')) # <re.Match object; span=(0, 3), match='*bc'>
print(re.search('co\.jp','yahoo.co.jp')) # <re.Match object; span=(6, 11), match='co.jp'>丸括弧() : グループ化
()でまとめてやることでグループ化します。下の例だと(abc)でグループ化して、abcの繰り返し部分にマッチングしています。
print(re.search('(abc)+','fedcbabcabcabcdefg')) # <re.Match object; span=(5, 14), match='abcabcabc'>\s : 空白文字
\sは空白文字とマッチングします。下の例では、任意の2文字に挟まれた空白文字を含む部分とマッチングします。他に\t(タブ文字)、\n(改行文字)、\r(リターン文字)、\f(改ページ文字)、\v(垂直タブ)も\sとマッチングする空白文字として扱われます。
print(re.search('..\s..','aaaa bbbb'))その他
その他、正規表現のシンタックスはいろいろありますが、このくらいを分かっていれば、だいたい表現したいことはできると思います。
| シンタックス | 意味 |
| \d | 10進数字 |
| \D | 10進数字以外 |
| \S | 空白文字以外 |
| \w | 英数字とアンダーバー(_) |
| \W | 英数字とアンダーバー(_)以外 |
メールアドレスの判定用の正規表現を紐解く
それではもう一度、メールアドレスの判定用正規表現を見てみます。
^[A-Za-z0-9]{1}[A-Za-z0-9_.-+]*@([a-zA-Z0-9][a-zA-Z0-9-]*[a-zA-Z0-9]*\.)+[a-zA-Z]{2,}$①^[A-Za-z0-9]{1} ⇒先頭の文字は英数字(1文字)
②[A-Za-z0-9_.-+]* ⇒2文字目以降は英数字と記号(_.-+)を0回以上繰り返し
③@ ⇒ローカル部とドメイン部の間にアットマークを挟む
④([a-zA-Z0-9][a-zA-Z0-9-]*[a-zA-Z0-9]*\.)+ ⇒先頭英数字で末尾がドット(.)のグループを1回以上繰り返してローカルドメインを表す
⑤[a-zA-Z]{2,}$ ⇒トップドメインは2文字以上のアルファベット
難解に思えた上の正規表現もシンタックスが分かれば、内容が理解できました。
正規表現のオブジェクト
ここからは正規表現のオブジェクトとしての用法を見ていきます。
オブジェクト化(compile)
正規表現をre.compileでオブジェクト化して、正規表現の再利用ができます。
文字列の一致(search)
上で説明したメソッドとほぼ同じですが、書き方が違います。また、文字列の中で開始位置と終了位置をインデックスで指定できるところがちがいます。(開始インデックスと終了インデックスを省略したら先頭から検索します。)
正規表現オブジェクト.search(文章, 開始インデックス, 終了インデックス)
# 正規表現のオブジェクト化
pattern = re.compile('..客')
# 先頭から検索
result = pattern.search(text)
print(result) # <re.Match object; span=(0, 3), match='隣の客'>
# 4文字目(index=3)から編策
result = pattern.search(text,3)
print(result) # <re.Match object; span=(7, 10), match='食う客'>全検索(findall)
上のメソッドと開始位置と終了位置をインデックスで指定できるところが違います。それ以外は書き方が違うだけです。
正規表現オブジェクト.findall(文章, 開始インデックス, 終了インデックス)
text = "隣の客はよく柿食う客だ"
pattern = re.compile('[^あ-ん]') # 「あ」から「ん」のひらがな以外を指定
# 全範囲
print(pattern.findall(text)) # ['隣', '客', '柿', '食', '客']
# 6文字目~9文字目
print(pattern.findall(text,6,8)) # ['柿', '食']文頭の一致(match), 文章の分割(split), 文字列の置換(sub)
これは上のメソッドと書き方が違うだけです。
text = "隣の客はよく柿食う客だ"
# 文頭一致 (3文字目指定)
pattern = re.compile('客')
print(pattern.match(text, 2)) # <re.Match object; span=(2, 3), match='客'>
# 文章の分割
pattern = re.compile('客')
print(pattern.split(text)) # ['隣の', 'はよく柿食う', 'だ']
# 置換
pattern = re.compile('柿')
print(pattern.sub('リンゴ', text)) # 隣の客はよくリンゴ食う客だ置換の応用例
《 》で囲まれた文字列の削除
正規表現を組み合わせると、少し複雑な文字列操作ができるようになります。ここでは《 》で囲まれたフリガナを削除してみます。青空文庫はこの括弧を使ってルビをふっているので、青空文庫の小説の解析でルビを削除したいときに使えます。
「”《[^》]+》”」の文字列は、《 》で囲まれた部分を示します。
「《」のあと、「》」以外の文字を、「》」がでるまで、選択して、re.subで””と置換します。
import re
text = '私は近くの造幣局《ぞうへいきょく》まで散歩した。\
やけつく炎天下《えんてんか》の太陽が、アスファルトの表層《ひょうそう》に陽炎《かげろう》を作っていた。'
print(re.sub("《[^》]+》", "", text))参考
ここで記載した以外にいろいろな表現がありますので、ご確認ください。
間違いあれば、ご指摘いただけるとありがたいです。
