進化の早いStable Diffusionですが、少し前のセットアップ方法はすぐに古くなってしまいます。ここではこれからStable Diffusionをご自分のPCにセットアップしたいという方に向けて、2023年8月現在の最新のセットアップ法を紹介したいと思います。
※本記事は2023年6月現在の情報に基づき作成しています。(情報としては古いですがアーカイブとして残しています。)
パソコンの準備
Stable Diffusionを自分のPCで使うためにはStable Diffusionを使えるPCを準備する必要があります。もし、PCを準備できない場合は、Google Colab(有料版)や外部サービスを使う方法もありますが、ここでは、ご自分のPCにセットアップする方法を案内したいと思います。
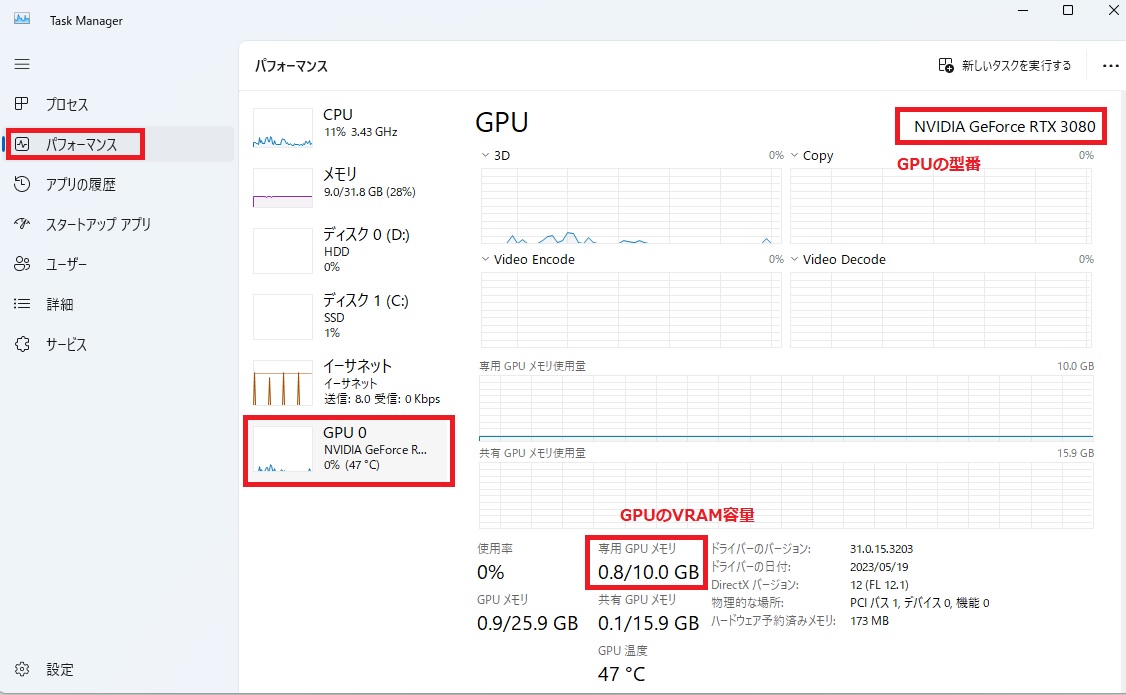
準備するPCはNVIDIA製のGPUを搭載したPCで、GPUのビデオメモリ(VRAM)は4GB以上のものが必要になります。これから、PCやGPUを準備する方は最低8GB以上のVRAMのものをおすすめします。いわゆる「ゲーミングPC」という区分で探すと、いろいろなメーカーのPCが探せると思います。ご自分のPCのGPUを確認するには、Windowsマークを右クリックして、「タスクマネージャー」を開いて、「パフォーマンス」のタブから、GPUを選ぶと「専用GPUメモリ」からお使いのPCのGPUのVRAMを確認できます。下の私のPCの場合、NVIDIA GeForce RTX3080のVRAM10GBです。
過去の記事でおすすめPC&GPUを紹介しているので、もし、パソコンを持っていない方はそちらをご覧ください。GPU搭載の高性能なPCはオンラインゲームができたり、音楽、画像、動画などのクリエーティブな作業をしたり、仕事にもゲームにも使えるので、一台持っておくと趣味やお仕事の幅が広がるのでお勧めです。

Pythonのインストール
Stable Diffusion WebUIを使うためにはPython3.10.6をインストールする必要があります。最新版のPythonでは動きませんのでご注意ください。Python3.10.6を指定してインストールすると不具合が出にくいです。Python3.10.6は以下のページからインストールします。もし、バージョンを間違えてインストールしてしまった場合は、一度アンインストールしてから、インストールしなおせば問題ないです。
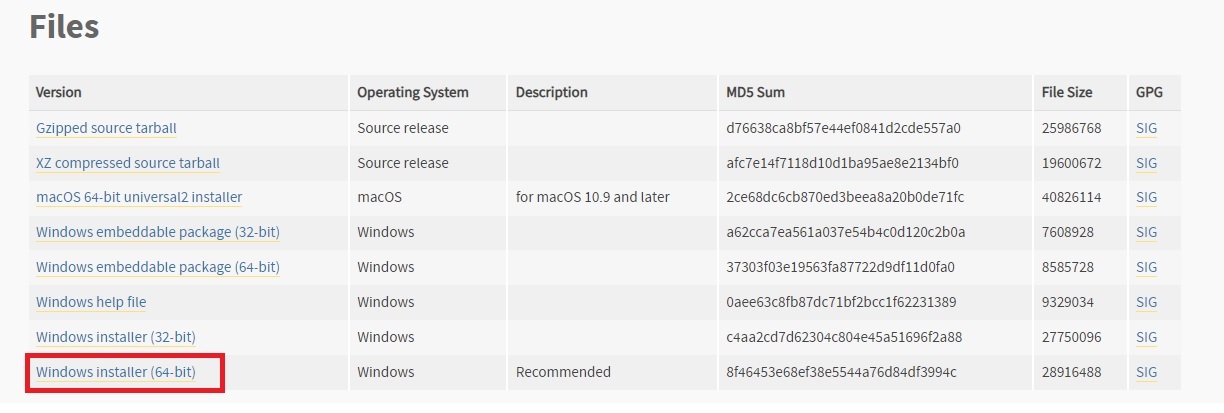
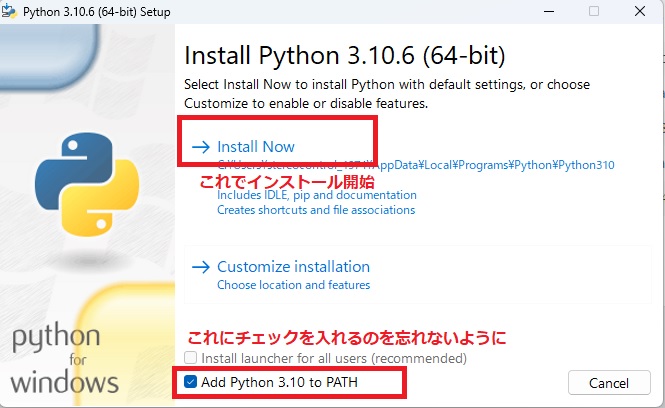
上のサイトからWindowsの方はWindows installer (64-bit)を選んでインストーラーをダウンロードして実行してください。実行すると下のような画面が表示されますので、「Add Python 3.10 to PATH」にチェックを入れてから、「Install Now」でインストールをしましょう。
Gitの手動インストール
Stable Diffusionでは本体や拡張機能のダウンロードにGitというツールを使います。Gitは下のサイトからダウンロードできます
Git -Downloading Package(英語サイト)
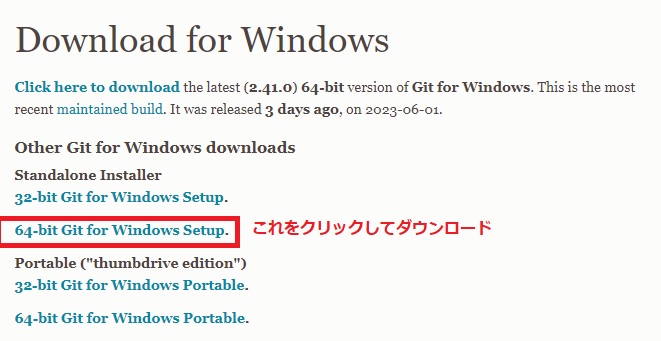
上のページの64-bit Git for Windows Setupをクリックするとインストーラーがダウンロードされるので、指示に従いインストールしましょう。
Stable Diffusion WebUIのインストール
これで準備ができましたので、Stable Diffusion WebUIをインストールします。この段階で念のため再起動しておいた方が良いです。再起動が終わったら、インストールする場所を決めます。Stable Diffusionはモデルや生成した画像などでストレージを多く使うので、もし、Dドライブなど、システムで使っているCドライブ以外のストレージに余裕があれば、Dドライブなどへのインストールをお勧めします。50GB以上の空のあるストレージが理想。ちなみに筆者はSDで300GB以上のストレージを使っています。。。また、インストールする場所はPATHに日本語が含まれていない方が良いです。(拡張機能の一部設定がうまくいかないことがあった。)
インストールする場所を決めたらそのフォルダでコマンドプロンプトを開きます。インストールしたいフォルダやドライブを「SHIFT+右クリック」して、「ターミナルで開く」を選択します。コマンドプロンプトが開くので、その画面で以下のように入力し、Enterキーを押します。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
これで最新版のStable Diffusion WebUIを入手してくれます。インストール場所に「stable-diffusion-webui」というフォルダができているかと思います。その中に「webui-user.bat」というフォルダがあるので、それをダブルクリックして実行します。(もし、この時点でPCが拡張子を表示しない設定になっている場合は、拡張子を表示できるようにしておいた方がよいです。参考ページ)そのまま、しばらくセッティングが行われるので、待ちます。(ネットワーク状態や本体の性能にも寄りますが、30分以上掛かることもあります。)セットアップが終了したら、以下のようなメッセージがでます。
Calculating sha256 for D:\app\stable-diffusion-webui\models\Stable-diffusion\v1-5-pruned-emaonly.safetensors: Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Startup time: 223.6s (import torch: 2.6s, import gradio: 2.0s, import ldm: 0.7s, other imports: 2.7s, setup codeformer: 0.2s, list SD models: 213.9s, load scripts: 1.0s, create ui: 0.4s, gradio launch: 0.1s).
6ce0161689b3853acaa03779ec93eafe75a02f4ced659bee03f50797806fa2fa
Loading weights [6ce0161689] from D:\app\stable-diffusion-webui\models\Stable-diffusion\v1-5-pruned-emaonly.safetensors
Creating model from config: D:\app\stable-diffusion-webui\configs\v1-inference.yaml
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
Applying optimization: Doggettx... done.
Textual inversion embeddings loaded(0):
Model loaded in 7.9s (calculate hash: 4.0s, load weights from disk: 0.2s, create model: 0.4s, apply weights to model: 0.7s, apply half(): 0.8s, move model to device: 0.8s, load textual inversion embeddings: 1.0s).
ブラウザから指定されたURL「http://127.0.0.1:7860」にアクセスするとStable Diffusion WebUIが起動します。
拡張機能のインストール
さて、これで一応、Stable Diffusionのインストールができたので、試しに好きなプロンプトを入れて、「Generate」ボタンにより画像生成ができるのを確認できると思います。ただ、このままだと必要な機能やモデルがセットアップされていないので、引き続いて設定を行っていきます。
ここでは、拡張機能をインストールしていきます。ここでは、狙った画像を生成するのに必須となっている「ControlNet」と、こちらはお好みですが日本語化拡張機能をインストールします。
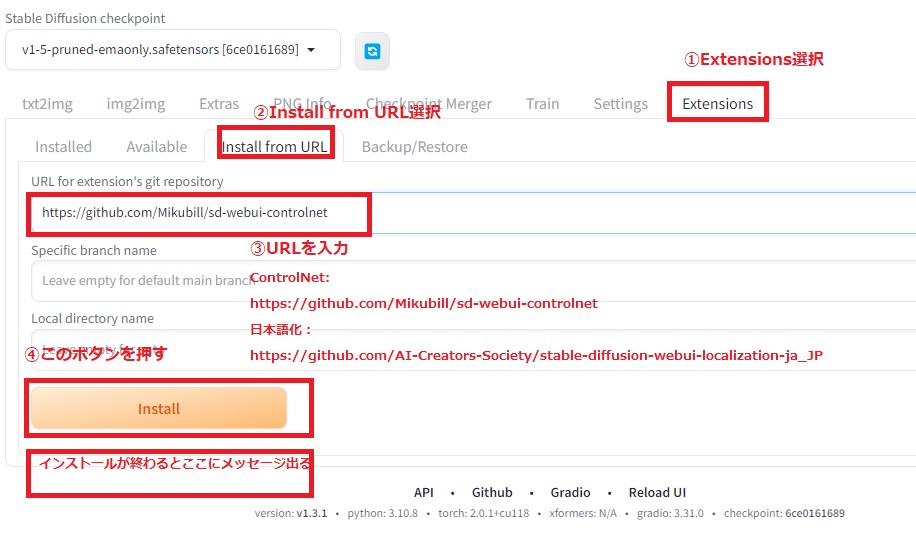
「Extensions」のタグから、「Install from URL」を選択し、「URL for extesion’s git repository」に「https://github.com/Mikubill/sd-webui-controlnet」を入力し、「Install」ボタンを押してしばらくすると、ControlNetのインストールが終了します。引き続いて、「https://github.com/AI-Creators-Society/stable-diffusion-webui-localization-ja_JP」を入力してしばらくすると、日本語化拡張機能のインストールが終了します
ここで一旦Stable Diffusionを終了し、開いているコマンドプロンプトのウインドウも閉じます。
webui-user.batの設定
ここでwebui-user.batの設定を行います。「stable-diffusion-webui」の中の「webui-user.bat」を「SHIFT+右クリック」で「編集」を選択してメモ帳からファイルを開き、下記の黄色ハイライト部分を追記します。
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS= --no-half-vae --opt-channelslast --autolaunch --xformers
call webui.bat
この設定により、①画像生成時のエラー回避、②メモリの有効利用/高速化、③WebUIの自動起動の設定ができます。各環境に応じて、適切な設定は違いますので、ご注意ください。変更したら上書き保存します。
以後、WebUIの起動は、「webui-user.bat」をクリックして起動しますので、起動しやすいようにショートカットなどをどこかにおいておくことをお勧めします。
モデルの設定
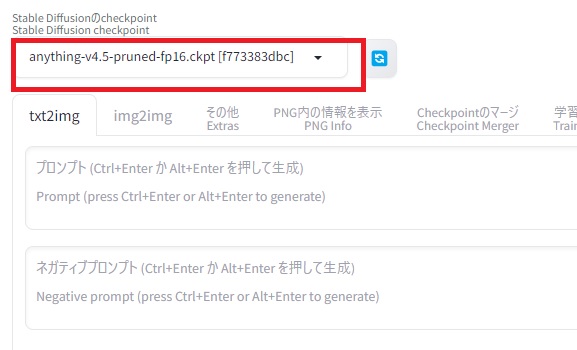
初期状態では、stable diffusionの標準のモデル(v1-5-pruned-emaonly.safetensors)しか入っていませんので、モデルを入れる必要があります。モデルはオンラインからダウンロードして適切な場所に入れます。Stable DiffusionのモデルはHugging FaceやCivitaiなどからダウンロード可能です。それぞれライセンスや配布元が信頼できるかを確認して、自己責任でダウンロードしてください。例えば、アニメ系の生成で有名なanything-v4.5をダウンロードしてみます。ファイルはckptかsafetensorsの拡張子のファイルをダウンロードします。今回は軽量版のanything-v4.5-pruned-fp16.ckptをダウンロードします。
anything-v4.5-pruned-fp16.ckpt
また、VAEはv4.5版は見当たらないので、anything-v4.0.vae.ptを使うことにします。
VAEを入れておくと若干生成する画像の画質をあげてくれます。なくても構いませんし、他のモデルのVAEを使っても問題ないことが多いです。モデルは「\stable-diffusion-webui\models」のフォルダの中の「Stable-diffusion」のフォルダの中に入れます。また、VAEは同じ「\stable-diffusion-webui\models」のフォルダの中の「VAE」のフォルダに入れます。
また、ControlNetのモデルについてもダウンロードをします。モデルのダウンロードはここから行います。接続先のpthの拡張子のファイル(一つあたり約1.5GB)のファイルがcontrolnetのモデルファイルになります。2023年6月現在14種類ありますが、容量が大きいですが、ストレージに余裕があれば、すべてダウンロードしておくことをお勧めします。ダウンロードしたモデルファイルは、「\stable-diffusion-webui\extensions\sd-webui-controlnet\models」の中に入れましょう。もし、ストレージに余裕がない場合は、個人的に以下の4つは特におすすめです。(個人的なおすすめ順)
control_v11p_sd15_canny.pth
control_v11p_sd15_openpose.pth
control_v11p_sd15_scribble.pth
control_v11f1p_sd15_depth.pth
日本語の設定
再び「webui-user.bat」をダブルクリックしてstable diffusionを起動しましょう。最初は起動に少し時間かかります。
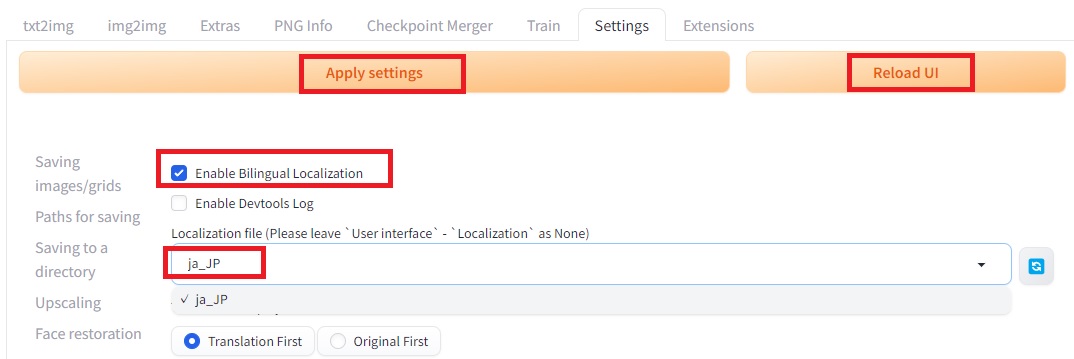
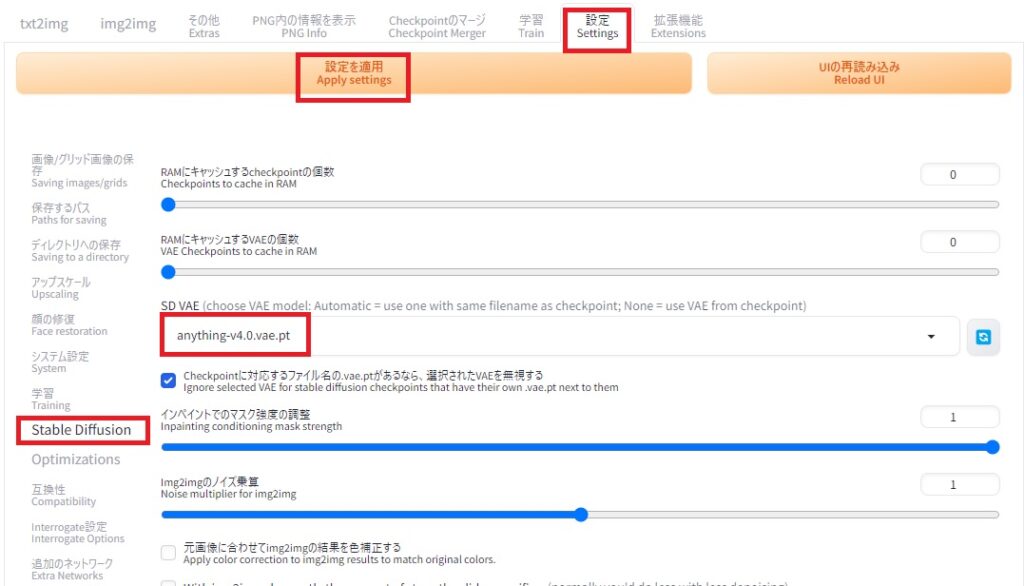
起動に成功すると今度は自動的にブラウザが開きます。日本語化の設定をするために「Settings」の「Bilingual Localization」を選択し、Localization fileにja_JPを選択します。「Enable Billingual Localization」はチェックを入れたままにします(チェックが入っていないとうまくいかないようです。)。設定したら、「Apply settings」のボタンを押し、設定を適用させた上で、Reload UIでUIを再読み込みすると、日本語になります。
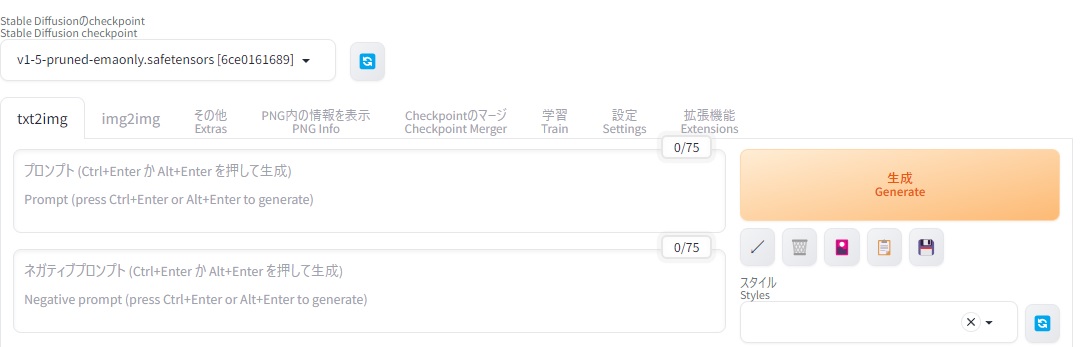
モデルの選択
モデルは左上のボックスから変更できます。モデルを変更した後は読み込ませるのに少し時間が掛かるので、設定が終わるまで待ちます。
また、VAEは「Settings」の「Stable Diffusion」の中の「SD VAE」から選択して、「Apply settings」で設定できます。
画像の生成テスト
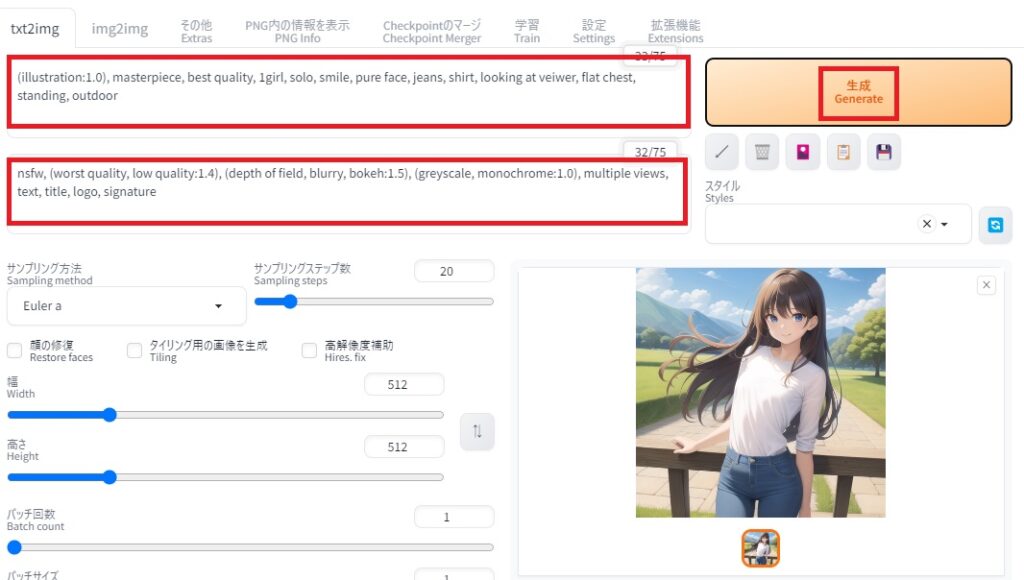
これで準備ができました。txt2imgのプロンプト欄にプロンプトを入れて画像を生成してみましょう。細かい設定は抜きにして、まずは英語のプロンプトを入れて画像を生成してみます。
例えば、プロンプトには以下のようなテキストを入れます。
(illustration:1.0), masterpiece, best quality, 1girl, solo, smile, pure face, jeans, shirt, looking at veiwer, flat chest, standing, outdoor
また、ネガティブプロンプトに以下のテキストを入れます。(割と決まりきった構文があります)
nsfw, (worst quality, low quality:1.4), (depth of field, blurry, bokeh:1.5), (greyscale, monochrome:1.0), multiple views, text, title, logo, signature
それで、「Generate」のボタンを押して、しばらく待つと画像を生成します。